卷积神经网络
为什么除了人工神经网络,又冒出来卷积神经网络、循环神经网络等等,因为之前人工神经网络的框架,对于高纬度的图像等数据需要求的W太多。卷积神经网络,可以参数共享(指的是各神经元有自己的固定参数),保持了层级网络结构,不同层次有不同形式(运算)与功能(而人工神经网络都是全连接)。三个关键点:local connectivity ; share weights(parameter shareing) ; Pooling & subsampling 主要有以下层次:
数据输入层\卷积计算层(conv layer)\激励层\池化层\全连接层\batch normalization

输入层:去均值(训练集上均值,会有不同求均值方式)、归一化、PCA
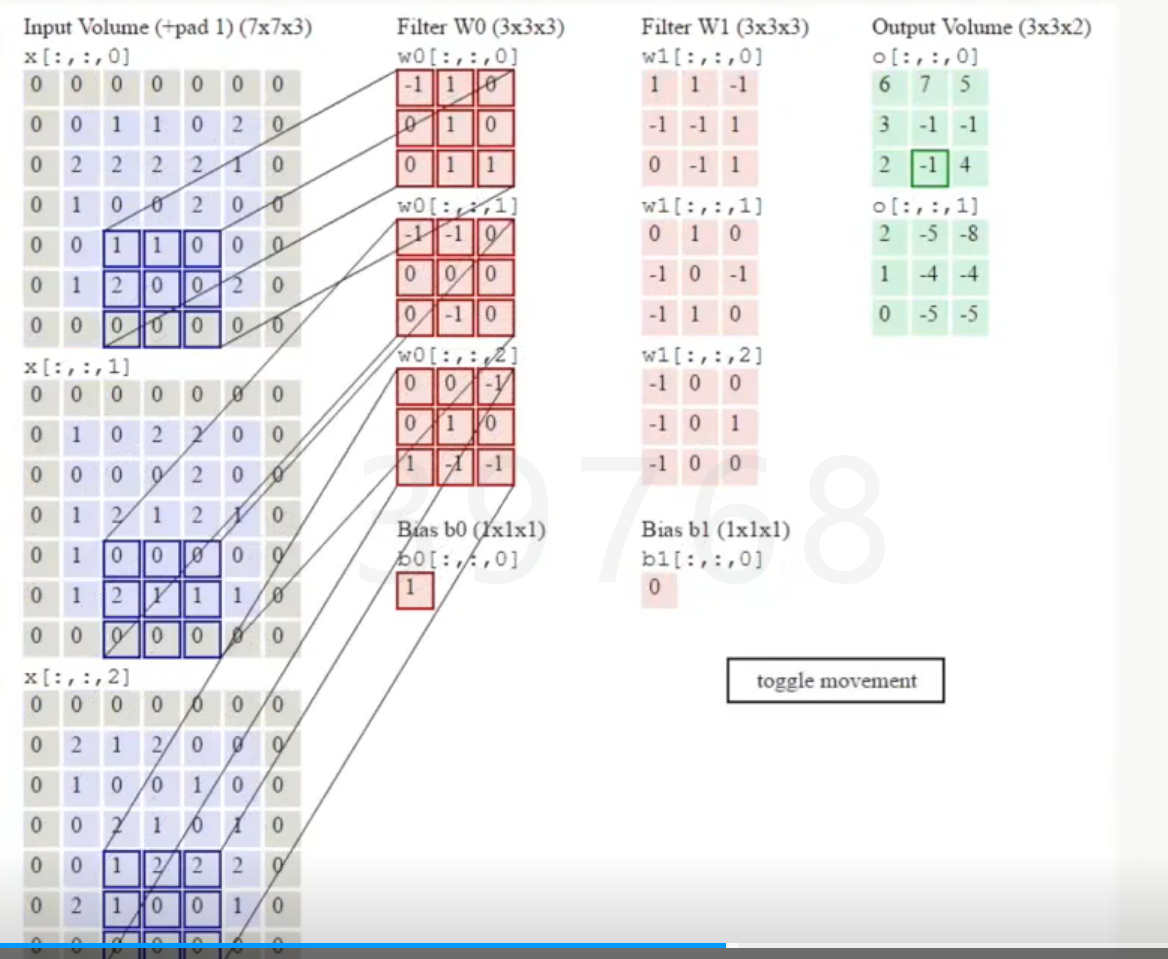
卷积计算层:每个神经元看做一个filter,窗口滑动,filter对局部数据计算。(某个点只和它局部的点相关),局部关联性;每个神经元做自己的一份工作,只关注一个特性,由32*32*3变成2*2*3*5,A和B用的参数不同。
深度(depth):分工分给了几个同学,有多少个神经元
步长(stride):这个窗口到下一个窗口怎么跳
填充值(zero-padding):为了橱窗刚好贴合,可在边缘填补0
计算,点积(逐点做乘积然后求和);参数共享机制,假设每个神经元连接数据窗的权重是固定的,每个神经元只关注一个特性。一组固定的权重和不同窗口内数据做内积叫做卷积。


激励层(relu):把卷积层输出结果做非线性映射,使得叠加有意义;类似开关的东西,控制前面的信息要不要传,有没有帮助,需要信息的压缩和控制。传递函数包括sigmoid, Tanh, ReLU(修正线性单元), Leaky ReLU, ELU, Maxout等。Sigmoid存在一定的问题,SGD求导时,很大部分sigmoid函数的切线为0,带来梯度离散的问题,使得模型无法学习。

实际经验,在CNN中尽量不要用sigmoid,首先试试Relu,但要小心点,有可能不收敛,如果失效用leaky relu或者maxout。
池化层pooling:尽管有参数共享,可以减少一定的参数量,但如果神经元的个数比较多,参数还是较多,因此能不能降维呢或者数据压缩呢,因此有了池化层,实际是下采样过程,防止过拟合。有两种方式,一种叫Max pooling,另一种叫average pooling,池化层和卷积层的滑动方式是一样的,唯一的区别是,它不做点乘,而是做的取最大值或者平均值。其作用也类似于特征选择,选出我们人能看到图片的最耀眼的区域。

全连接FC: 两层之间所有神经元都有权重连接,通常全连接层在卷积神经网络尾部
一般CNN的结构依次为:输入,然后若干个卷积接激励,可能后面会接一个池化层,后面可能会接若干个全连接。
训练算法:
先定义LOSS Function,此时的损失函数需要对卷积层、激励层和池化层都求导,很大的混合函数,求偏导依然是链式法则,利用SGD迭代和更新W和b。w=w-η(αJ(w)/αW)

优缺点:

正则化与过拟合
神经网络学习能力强,可能过拟合,随机使一部分神经元失去活性Drop out(随机失活),训练的时候要drop out ,预测的时候不要