决策树与随机森林
首先,在了解树模型之前,自然想到树模型和线性模型有什么区别呢?其中最重要的是,树形模型是一个一个特征进行处理,之前线性模型是所有特征给予权重相加得到一个新的值。决策树与逻辑回归的分类区别也在于此,逻辑回归是将所有特征变换为概率后,通过大于某一概率阈值的划分为一类,小于某一概率阈值的为另一类;而决策树是对每一个特征做一个划分。另外逻辑回归只能找到线性分割(输入特征x与logit之间是线性的,除非对x进行多维映射),而决策树可以找到非线性分割。
而树形模型更加接近人的思维方式,可以产生可视化的分类规则,产生的模型具有可解释性(可以抽取规则)。树模型拟合出来的函数其实是分区间的阶梯函数。
决策树学习:采用自顶向下的递归的方法,基本思想是以信息熵为度量构造一棵熵值下降最快的树,到叶子节点处熵值为0(叶节点中的实例都属于一类)。
其次,需要了解几个重要的基本概念:根节点(最重要的特征);父节点与子节点是一对,先有父节点,才会有子节点;叶节点(最终标签)。
一、决策树
决策树生成的数学表达式:


决策树的生成:
决策树思想,实际上就是寻找最纯净的划分方法,这个最纯净在数学上叫纯度,纯度通俗点理解就是目标变量要分得足够开(y=1的和y=0的混到一起就会不纯)。另一种理解是分类误差率的一种衡量。实际决策树算法往往用到的是,纯度的另一面也即不纯度,下面是不纯度的公式。不纯度的选取有多种方法,每种方法也就形成了不同的决策树方法,比如ID3算法使用信息增益作为不纯度;C4.5算法使用信息增益率作为不纯度;CART算法使用基尼系数作为不纯度。

决策树要达到寻找最纯净划分的目标要干两件事,建树和剪枝
建树:
(1)如何按次序选择属性
也就是首先树根上以及树节点是哪个变量呢?这些变量是从最重要到次重要依次排序的,那怎么衡量这些变量的重要性呢? ID3算法用的是信息增益,C4.5算法用信息增益率;CART算法使用基尼系数。决策树方法是会把每个特征都试一遍,然后选取那个,能够使分类分的最好的特征,也就是说将A属性作为父节点,产生的纯度增益(GainA)要大于B属性作为父节点,则A作为优先选取的属性。


(根据log(x)的函数可知,p值越小,熵越大,所以当分组完全是会出现p=0此时熵最大)
(2) 如何分裂训练数据(对每个属性选择最优的分割点)
如何分裂数据也即分裂准则是什么?依然是通过不纯度来分裂数据的,通过比较划分前后的不纯度值,来确定如何分裂。
下面做具体的介绍:
——CART算法:既可以做分类,也可以做回归。只能形成二叉树。
分支条件:二分类问题
分支方法:对于连续特征的情况:比较阈值,高于某个阈值就属于某一类,低于某个阈值属于另一类。对于离散特征:抽取子特征,比如颜值这个特征,有帅、丑、中等三个水平,可以先分为帅和不帅的,不帅的里面再分成丑和中等的。
得分函数(y):就是上面提到的gt(x),对于分类树取得是分类最多的那个结果(也即众数),对于回归树取得是均值。
损失函数:其实这里的损失函数,就是分类的准则,也就是求最优化的准则
对于分类树(目标变量为离散变量):同一层所有分支假设函数的基尼系数的平均。
对于回归树(目标变量为连续变量):同一层所有分支假设函数的平方差损失
对于分类树(目标变量为离散变量):使用基尼系数作为分裂规则。比较分裂前的gini和分裂后的gini减少多少,减少的越多,则选取该分裂规则,这里的求解方法只能是离散穷举。关于基尼系数,可以参考周志华的西瓜书决策树那章,讲得比较简洁,也比较易懂。“直观来说,(数据集D的基尼系数)Gini(D)反映了从数据集D中随机抽取两个样本,其类别标记不一致的概率,因此Gini(D)越小,则数据集D的纯度越高。”
具体这个的计算,我觉得有例子才好理解,下面这个红绿球的例子很好的说明了,如何根据损失函数最小(也就是基尼系数最小)来选取分裂规则。最后GIINs2更小,因此选择它作为分类规则。

对于回归树(目标变量为连续变量):使用最小方差作为分裂规则。只能生成二叉树。

CART与逻辑回归的比较:
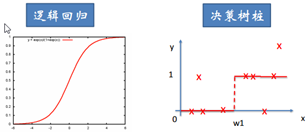
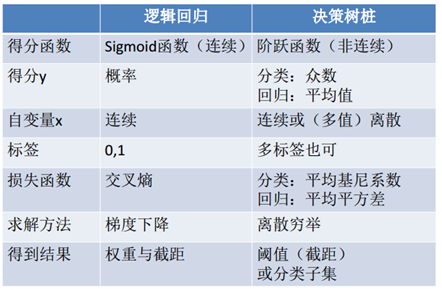
主要优缺点如下图。缺点补充几点,不是很稳点,数据变化一点,你的树就会发生变化;没有考虑变量之间相关性,每次筛选都只考虑一个变量(因此不需要归一化);只能线性分割数据;贪婪算法(可能找不到最好的树)。优点也补充三点,同时可以处理分类变量和数值变量(但是可能决策树对连续变量的划分并不合理,所以可以提前先离散化);可以处理多输出问题;另外决策树不需要做变量筛选,它会自动筛选;适合处理高维度数据。

ID3算法:使用信息增益作为分裂的规则,信息增益越大,则选取该分裂规则。多分叉树。信息增益可以理解为,有了x以后对于标签p的不确定性的减少,减少的越多越好,即信息增益越大越好。

C4.5算法:使用信息增益率作为分裂规则(需要用信息增益除以,该属性本身的熵),此方法避免了ID3算法中的归纳偏置问题,因为ID3算法会偏向于选择类别较多的属性(形成分支较多会导致信息增益大)。多分叉树。连续属性的分裂只能二分裂,离散属性的分裂可以多分裂,比较分裂前后信息增益率,选取信息增益率最大的。

三种方法对比:
ID3的缺点,倾向于选择水平数量较多的变量,可能导致训练得到一个庞大且深度浅的树;另外输入变量必须是分类变量(连续变量必须离散化);最后无法处理空值。
C4.5选择了信息增益率替代信息增益。
CART以基尼系数替代熵;最小化不纯度而不是最大化信息增益。
剪树:
(2) 如何停止分裂
下面这六种情况都会停止分裂。其中第一种其实属于树的完全长成,但这会出现过拟合问题,所有之前很流行一种抑制这种情况的方法,叫树的剪枝。树的剪枝分为预剪枝和后剪枝,预剪枝,及早的停止树增长控制树的规模,方法可以参考如下6点停止分类的条件。后剪枝在已生成过拟合决策树上进行剪枝,删除没有意义的组,可以得到简化版的剪枝决策树,包括REP(设定一定的误分类率,减掉对误分类率上升不超过阈值的多余树)、PEP,还有一种CCP,即给分裂准则—基尼系数加上惩罚项,此时树的层数越深,基尼系数的惩罚项会越大。


二、随机森林
尽管有剪枝等等方法,一棵树的生成肯定还是不如多棵树,因此就有了随机森林,解决决策树泛化能力弱的缺点。(可以理解成三个臭皮匠顶过诸葛亮)
而同一批数据,用同样的算法只能产生一棵树,这时Bagging策略可以帮助我们产生不同的数据集。Bagging策略来源于bootstrap aggregation:从样本集(假设样本集N个数据点)中重采样选出Nb个样本(有放回的采样,样本数据点个数仍然不变为N),在所有样本上,对这n个样本建立分类器(ID3\C4.5\CART\SVM\LOGISTIC),重复以上两步m次,获得m个分类器,最后根据这m个分类器的投票结果,决定数据属于哪一类。
随机森林在bagging的基础上更进一步:
1. 样本的随机:从样本集中用Bootstrap随机选取n个样本
2. 特征的随机:从所有属性中随机选取K个属性,选择最佳分割属性作为节点建立CART决策树(泛化的理解,这里面也可以是其他类型的分类器,比如SVM、Logistics)
3. 重复以上两步m次,即建立了m棵CART决策树
4. 这m个CART形成随机森林,通过投票表决结果,决定数据属于哪一类(投票机制有一票否决制、少数服从多数、加权多数)
关于调参:1.如何选取K,可以考虑有N个属性,取K=根号N
2.最大深度(不超过8层)
3.棵数
4.最小分裂样本树
5.类别比例
三、python实现代码

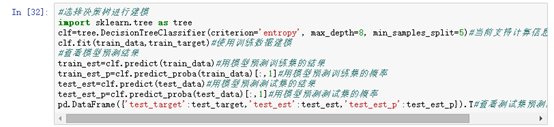
决策树的重要参数都是防止过拟合的. 有2个参数是关键,min_samples_leaf 这个sklearn的默认值是1,经验上必须大于100,如果一个节点都没有100个样本支持他的决策,一般都被认为是过拟合;max_depth 这个参数控制树的规模。决策树是一个非常直观的机器学习方法。一般我们都会把它的决策树结构打印出来观察,如果深度太深对于我们的理解是有难度的。
输出决策树图像
from sklearn import tree import pydotplus from IPython.display import Image from sklearn.externals.six import StringIO import os os.environ["PATH"] += os.pathsep + "C:/Program Files (x86)/Graphviz2.38/bin/" with open(path + "dt.dot", "w") as f: tree.export_graphviz(clf, out_file=f) dot_data = StringIO() tree.export_graphviz(clf, out_file = dot_data, feature_names = x.columns, class_names = ['bad_ind'], filled=True, rounded=True, special_characters=True) graph = pydotplus.graph_from_dot_data(dot_data.getvalue()) Image(graph.create_png())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号