文本相关杂七杂八
一、词袋模型
维度=|词典|; 稀疏向量
假设词典里有7个单词【我们,去,爬山,今天,你们,昨天,运动】
每个单词的表示:
我们:[1,0,0,0,0,0,0]
爬山:[0,0,1,0,0,0,0]
运动:[0,0,1,0,0,0,1]
句子的表示:
我们今天去爬山:[1,1,1,1,0,0,0]
你们昨天运动:[0,0,0,0,1,1,1]
怎么表示句子的相关性?
欧式距离计算:d=|s1-s2| 只关注距离没考虑方向 , 值越高句子相似度越低
![]()
余弦相似度计算:d = (s1*s2)/|s1|*|s2| 值越高句子相似度越高
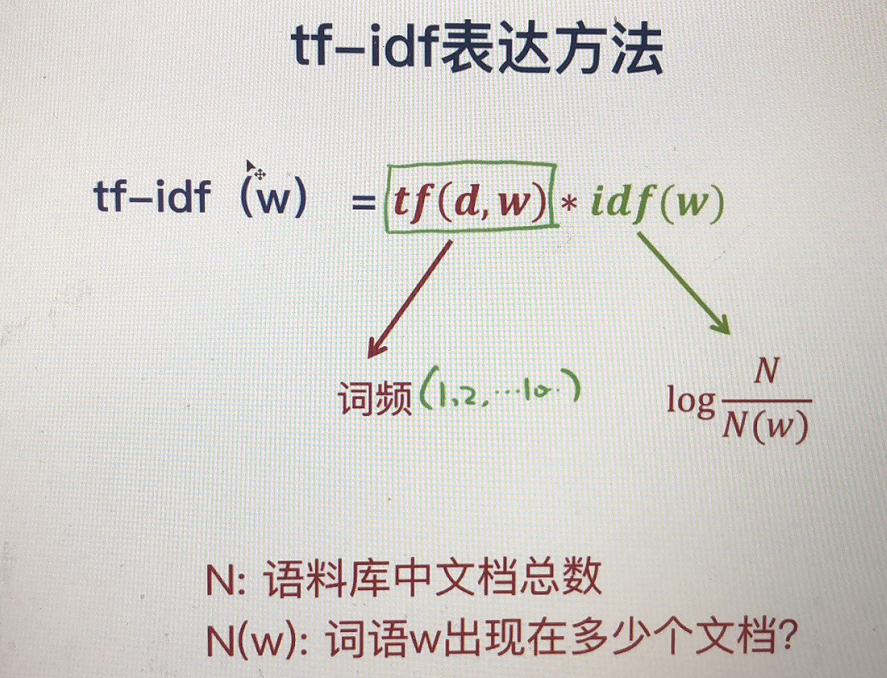
TFIDF

如何刻画每个单词的重要性,上图只考虑了词的频率,把每个单词的重要性考虑进来。TFIDF,考虑了频率和重要性。

corpus = ['He is going from Beijing to Shanghai.', 'He denied my request, but he actually lied.', 'Mike lost the phone, and phone was in the car'] #方法1只考虑词频 from sklearn.feature_extraction.text import CountVectorizer vectorizer = CountVectorizer() X=vectorizer.fit_transform(corpus) print(X.toarray()) #方法2 考虑词频和重要性TFIDF from sklearn.feature_extraction.text import TfidfVectorizer vectorizer = TfidfVectorizer() X=vectorizer.fit_transform(corpus) print(X.toarray())
二、Word2Vec词向量表示
从词袋模型到分布式表示,通过深度学习模型Word2Vec(SkipGram, Glove, Cbow, Gaussion Embedding, Hyperbolic Embedding)将词表示成向量(计算每个单词的词向量),模式的输入是我们的语料库。

有了词向量后,句子向量的求法有很多:1.求平均average 2.考虑时序模型LSTM RNN(可以计算整个句子的向量)
提前准备语料库,假设是金融相关的语料库,比如研报;使用word2vec开源工具
python word2vec.py -train wiki_sample.txt -cbow 0 -negative 10 -dim 20 -window 5 -min-count 5
词向量模型
词向量模型包括skipGram、CBOW、Glove、ELMO、Bert、MF、NNLM等,核心思想是一个分布假设,就是相邻的单词相似度更高。
下面主要介绍下SkipGram,利用周围的信息预测中间词,关键是构造我们的目标函数。
首先是在分布假设下(相邻的单词相似度更高)构造的目标函数,但是这种目标函数的求解很困难,所有换一种同样含义的目标函数的构造方法


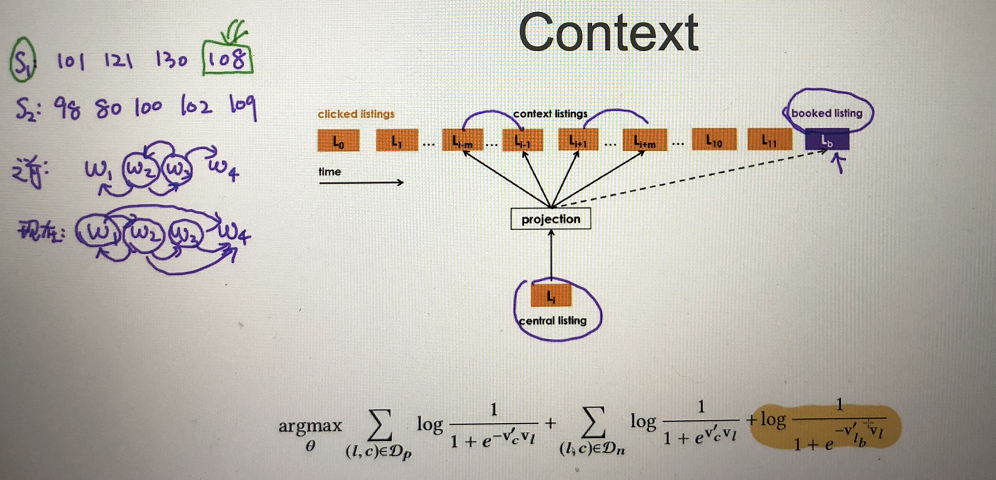
换一种模型的构造方法,将原来的问题转换为二分类问题,可以沿用逻辑回归的方法。在给定窗口范围内,在中心词附近的上下文词和中心词构成了正样本,中心词与剩余的词构成了负样本,U是中心词向量,V是上下文词向量(U,V都是要求的参数θ)

正样本数量少(根据窗口),负样本非常多,针对每一个正样本,可以进行负采样选择一组负样本。

skipGram可以用于产品推荐,比如论文《Real-time Personalization using Embeddings for Search Ranking at Airbnb》
如何计算每个产品的向量表示呢?我们可以用skipGram直接套在session 产品ID, 产品的点击序列, 用户兴趣短暂是不会改变,看的顺序可以转变成词向量的学习(把session信息从日志中抽取出来)
在skipGram的基础上,基于业务的理解,做了两方面的优化,1.S1中有付费产品 S2都没付费,关注S1成单的产品,所有的中心词都要预测成单项 2.负采样不再是全局采样,而是针对性负采样,比如当前是北京的产品,负采样只针对北京的产品

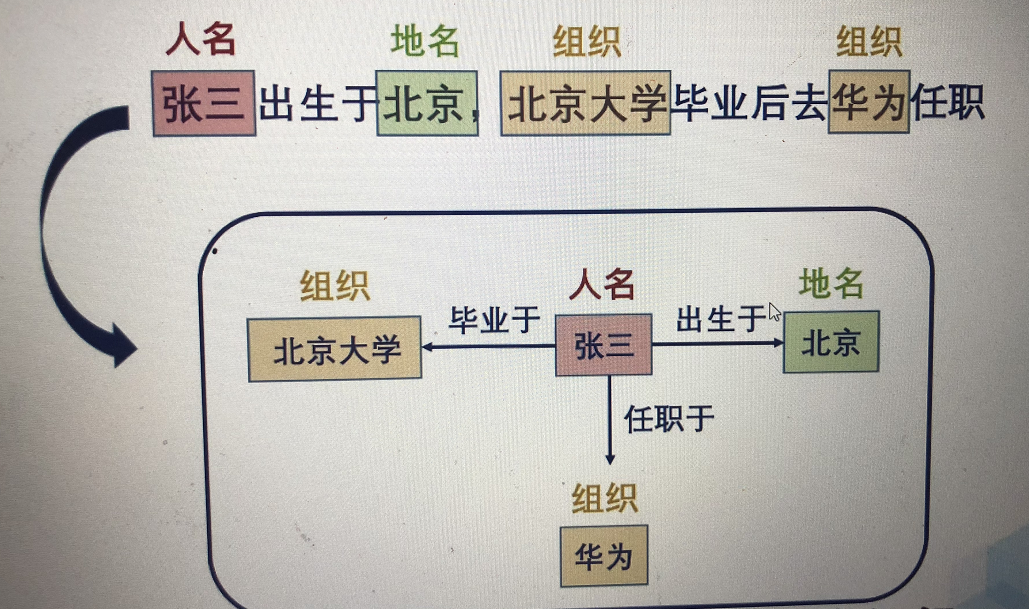
三、命名实体识别
按照类型标记每一个名词。比如“张三出生于北京,北京大学毕业后去华为任职”。对于文章里面的话做进一步的分类,分类的结果可以是人名、地名、组织或时间。
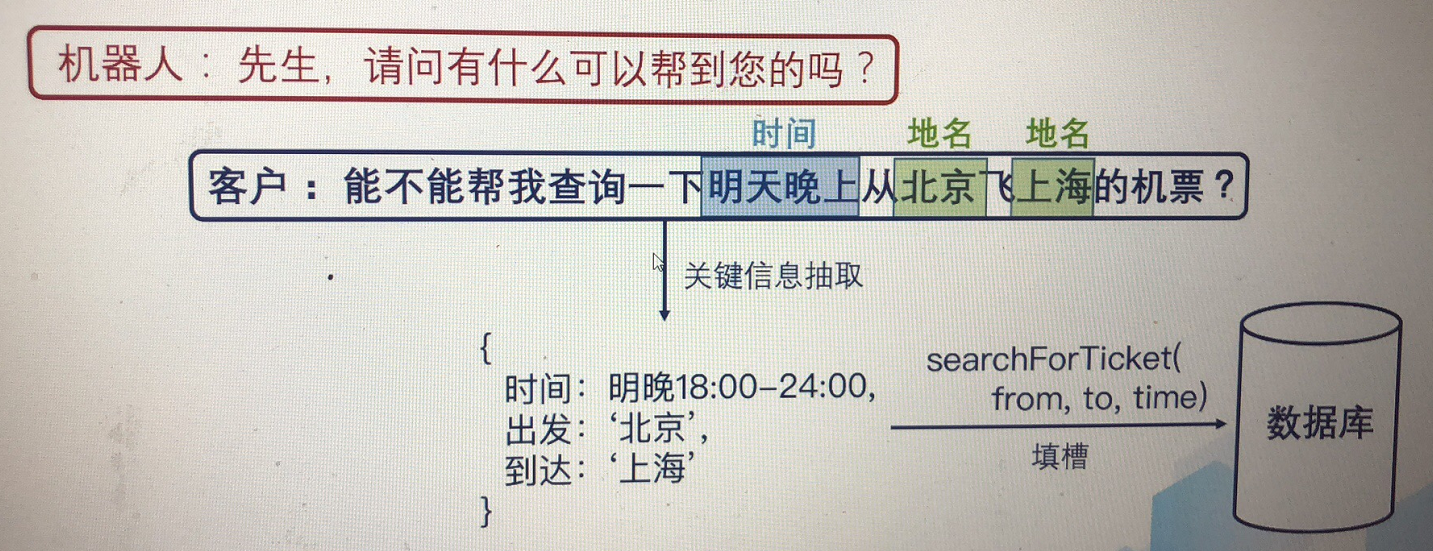
命名实体识别对于知识图谱的构建十分重要,聊天机器人也十分重要。
使用随机森林预测实体类别
1 from sklearn.preprocessing import LabelEncoder 2 from sklearn.model_selection import cross_val_predict 3 from sklearn.metrics import classification_report 4 #列名:Sentence# word pos Tag 5 # Sentence1 Throunds NNS O 6 # Sentence1 of IN O 7 8 data = pd.read_csv('ner_dataset.csv') 9 #读取每句话 10 def get_sentences(data): 11 agg_func = lambda s: [(w,p,t) for w, p, t in 12 zip(s["word"].values.tolist(), s["pos"].values.tolist(), 13 s["Tag"].values.tolist())] 14 sentence_grouped = data.group("sentence#").apply(agg_func) 15 return [s for s in sentence_grouped] 16 sentences = get_sentences(data) 17 #特征工程 18 out = [] 19 y = [] 20 mv_tagger = MajorityVoting() 21 tag_encoder = LabelEncoder() 22 pos_encoder = LabelEncoder() 23 words = data['word'].values.tolist() 24 tags = data['Tag'].values.tolist() 25 mv_tagger.fit(words, tags) 26 tag_encoder.fit(tags) 27 pos_encoder.fit(pos) 28 for sentence in sentences: 29 # w:单词,p:词性, t:NER标签 30 for i in range(len(sentences)): 31 w, p, t = sentences[i][0], sentences[i][1], sentences[i][2] 32 # 如果不是句子中的最后一个单词,则可以提取出上下文特征 33 if i< len(sentence)-1: 34 mem_tag_r = tag_encoder.transform(mv_tagger.predict([sentence[i+1][0]])[0])[0] 35 true_pos_r = pos_encoder.transform(sentence[i+1][1])[0] 36 else: 37 mem_tag_r = tag_encoder.transform(['O'])[0] 38 true_tag_r = pos_encoder.transform(['.'])[0] 39 # 如果不是句子中的第一个单词,则可以提取上文的特征 40 if i>0: 41 mem_tag_r = tag_encoder.transform(mv_tagger.predict([sentence[i-1][0]])[0])[0] 42 true_pos_r = pos_encoder.transform(sentence[i-1][1])[0] 43 else: 44 mem_tag_r = tag_encoder.transform(['O'])[0] 45 true_tag_r = pos_encoder.transform(['.'])[0] 46 out.append(np.array([w.istitle(), w.islower(), w.isupper(), len(w), w.isdigit(), w.isalpha(), 47 tag_encoder.transform(mv_tagger.predict([w]))[0], 48 pos_encoder.transoform([p])[0], 49 mem_tag_r, true_pos_r, mem_tag_r, true_tag_r])) 50 y.append(t) 51 pred = cross_val_predict(RandomForestClassifier(n_estimator=20), X=out,y=y, cv=5) 52 report = classification_report(y_pred=pred, y_true=tags)
使用CRF预测实体类别
HM是当前词只受前一个词的影响,CRF是当前词会受一整句话有关系,考虑时序。但是参数轨迹和推断很难,无向图计算量上比有向图难很多。
def word2feature(sent, i): """ :param sent: input sentence :param i:index of word """ word = sent[i][0] postag = sent[i][1] feature = { 'bias':1.0, 'word.lower()':word.lower(), 'word[-3:]':word[-3:], 'word.isupper()':word.isupper(), 'word.istitle()':word.istitle(), 'word.isdigit()':word.isdigit(), 'postag':postag, 'postag[:2]':postag[:2], } #提取前缀特征 if i>0: word1 = sent[i-1][0] postag1 = sent[i-1][1] feature.update({ '-1:word.lower()':word1.lower(), '-1:word.istitle()':word1.istitle(), '-1:word.isupper()': word1.isupper(), '-1:postag':postag1, '-1:postag[:2]':postag1[:2] }) else: feature['BOS']=True #提取下文特征 if i<len(sent) -1: word1 = sent[i + 1][0] postag1 = sent[i + 1][1] feature.update({ '+1:word.lower()': word1.lower(), '+1:word.istitle()': word1.istitle(), '+1:word.isupper()': word1.isupper(), '+1:postag': postag1, '+1:postag[:2]': postag1[:2] }) else: feature['EOS'] = True def sent2feature(sent): return [word2feature(sent,i) for i in range(len(sent))] def sent2labels(sent): return [label for token, postag, label in sent] x = [sent2feature(s) for s in sentences] y = [sent2labels(s) for s in sentencse] from sklearn_crfsuite import CRF crf = CRF(algorithm='lbfgs', c1=0.1, c2=0.1, max_iterations=100 ) from sklearn.model_selection import cross_val_predict from sklearn_crfsuite.metrics import flat_classification_report pred = cross_val_predict(estimator=crf, X=x, y=y, cv=5) report = flat_classification_report(y_pred=pred, y_true=y)
四、关系抽取
方法:基于自定义模板、Bootstrap方法、监督学习方法、无监督学习方法
1.基于自定义模板
要自己去定义一条条规则,找出尽可能多的拥有“is-a”关系实体对(考虑实体类型)。有多少种关系,就有多少个实体对Table.


2.基于监督学习的关系挖掘
准备条件:定义好所有实体类型(比如20种)、定义好所有的关系类型(30种)、标注好的语料库(Training data)
特征的抽取

3. Bootstrap方法
假设你没有很多的数据来训练模型,但是你已经有设计好几个很有效的模板,大量没有标记过的数据
Bootstrap方法可以看做是半监督学习,我们能不能把这些已有的模板和数据用起来?
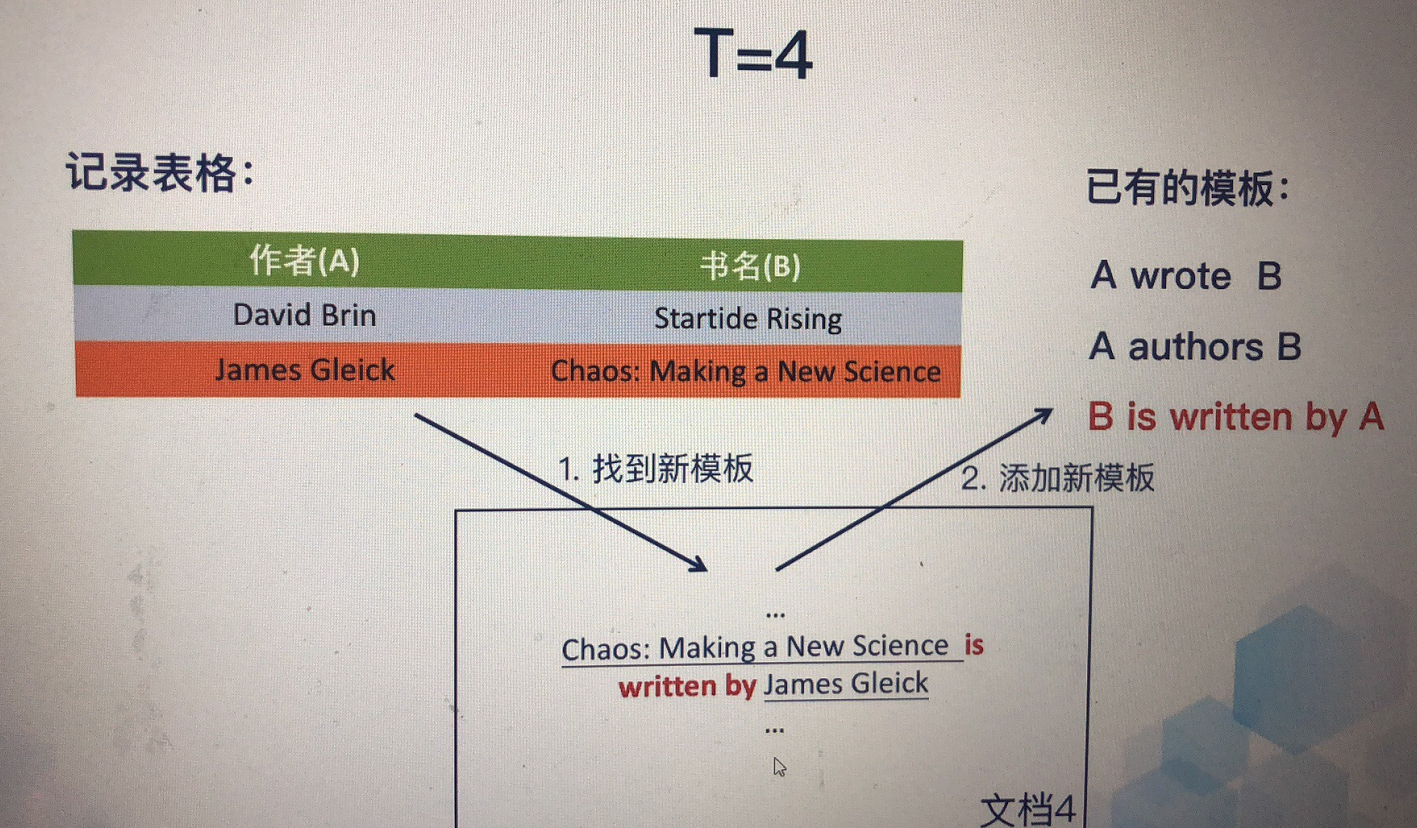
Bootstrap方法缺点,对于每种关系,需要提前准备至少一种模板,每次迭代都有可能降低准确率,不具备概率可解释性。可以结合人工检查。
seed tuples-->new pattern--->new tuples-->new pattern--->new tuples.......
Snowball这个工具提供了评估的方法自动的去筛选最好的一些记录,它其实是bootstrap的升级版本
五、工具
HanLP
https://github.com/hankcs/HanLP
https://github.com/hankcs/pyhanlp
HanLP词性标注集:http://www.hankcs.com/nlp/part-of-speech-tagging.html#h2-8
from pyhanlp import * print(HanLP.segment('你好,欢迎在Python中调用HanLP的API')) for term in HanLP.segment('下雨天地面积水'): print('{}\t{}'.format(term.word, term.nature)) # 获取单词与词性 testCases = [ "商品和服务", "结婚的和尚未结婚的确实在干扰分词啊", "买水果然后来世博园最后去世博会", "中国的首都是北京", "欢迎新老师生前来就餐", "工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作", "随着页游兴起到现在的页游繁盛,依赖于存档进行逻辑判断的设计减少了,但这块也不能完全忽略掉。"] for sentence in testCases: print(HanLP.segment(sentence)) # 关键词提取 document = "水利部水资源司司长陈明忠9月29日在国务院新闻办举行的新闻发布会上透露," \ "根据刚刚完成了水资源管理制度的考核,有部分省接近了红线的指标," \ "有部分省超过红线的指标。对一些超过红线的地方,陈明忠表示,对一些取用水项目进行区域的限批," \ "严格地进行水资源论证和取水许可的批准。" print(HanLP.extractKeyword(document, 2)) # 自动摘要 print(HanLP.extractSummary(document, 3)) # 依存句法分析 print(HanLP.parseDependency("徐先生还具体帮助他确定了把画雄鹰、松鼠和麻雀作为主攻目标。"))
六、实体统一
比如不同的用户可能填写地址的时候,对同一个地址的描述完全不一样,而这些地址其实指向的是同一个实体,那这个时候就需要实体统一
比如同一个公司,可能叫百度、叫百度有限公司、叫百度科技有限公司,这时候也需要实体统一
比如同一个用户用不同的手机号登陆了一个网站,但这些手机号实际上是来自于同一个实体
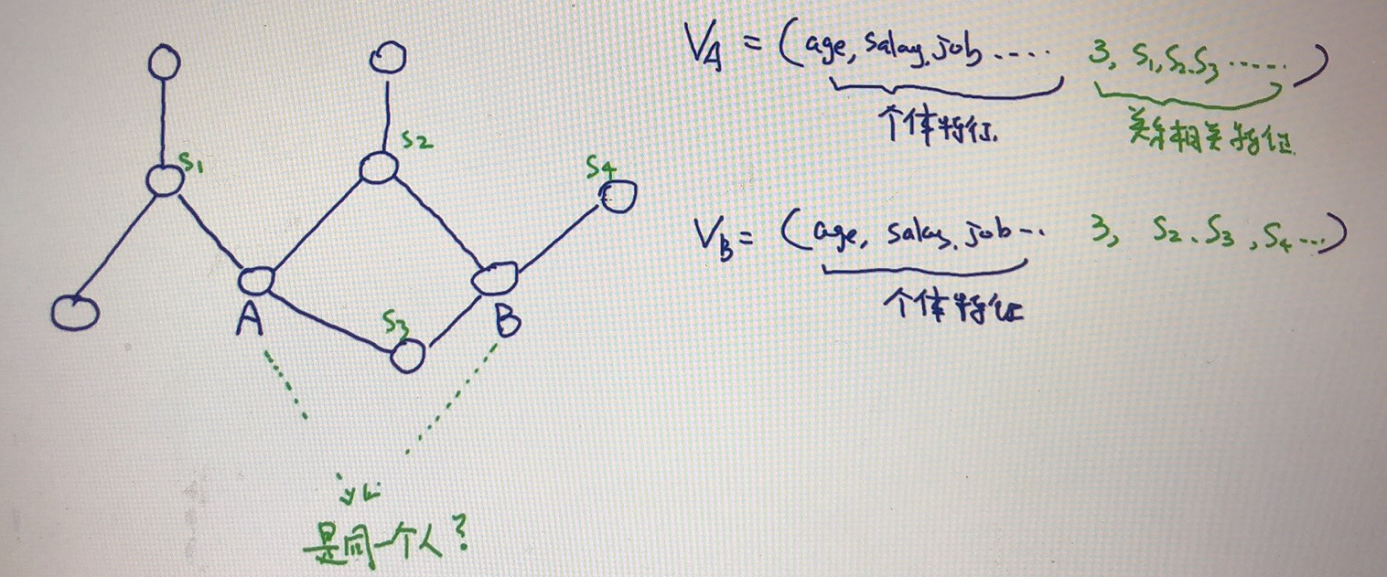
定义:给定两个实体,判断会否指向同一个实体?(0,1分类)
第一种方法:sim(str1, str2)
第二种方法:基于规则,常用于地址和公司名消歧。提前维护好描述库,(有限公司、无限公司、。。。)(北京市、天津市、。。。)
然后遇到“百度有限公司”,“百度科技有限公司”,“百度广州分公司”就可以通过规则映射(删掉描述库里面出现词)成原型“百度”
第三种方法:监督学习方法
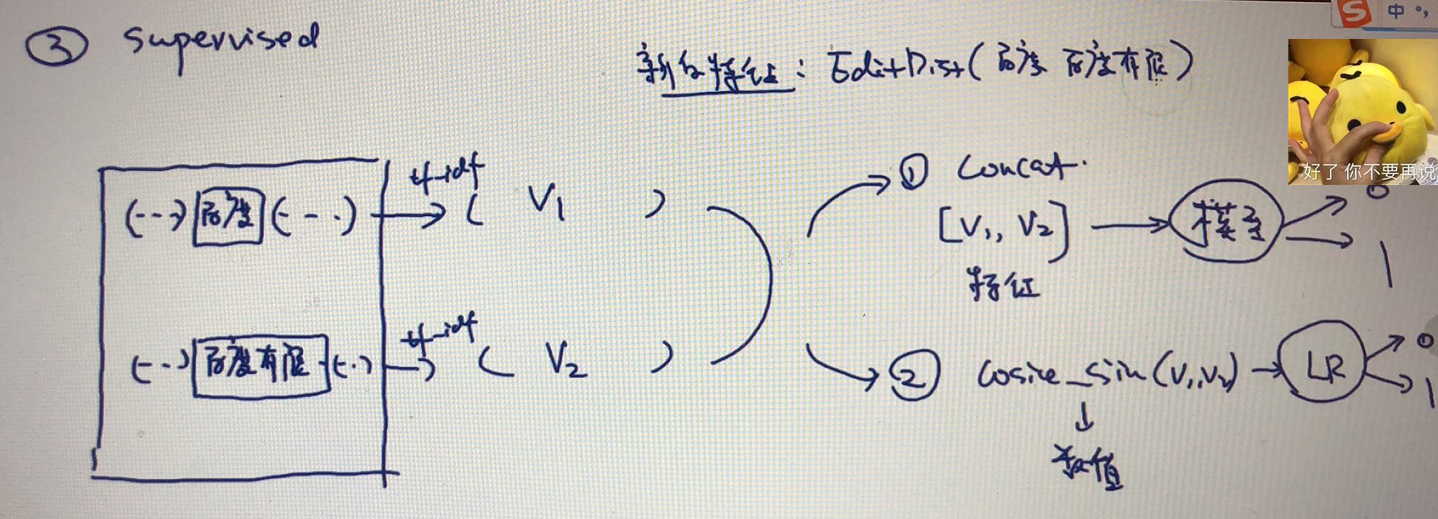
基于图的实体统一