Python —— 文件处理
1、文件操作分为读、写、修改
两种方式读写文件:
方法1:
1 f = open(file = '路径', mode = 'r', encoding = 'utf-8') 2 data = f.read() 3 f.close()
方法2:
1 with open(‘路径’,‘r’,encoding = 'utf-8') as f: 2 f.read()
2、以什么方式存的文件,就要用什么方式打开,必须指定,否则会出现编码错误,所以在open里面要写上encoding
3、路径
相对路径
绝对路径
4、二进制模式
在不知道文件使用什么编码的情况下,要打开文件,可以使用二进制模式打开:
1 f = open(file = '路径', mode = 'rb') 2 data = f.read() # f.read(1) 读1个字符 3 print(data) 4 f.close()
5、智能检测编码工具:
要判断文件到底使用哪种方式编码的(一般就是utf-8、Unicode、gbk)
需要使用第三方模块: chardet, 根据编码的规律(不同编码的字节)
# -*- coding:utf -8-*- import chardet f = open('hello', 'rb') data = f.read() f.close() result = chardet.detect(data) print(result) out: {'encoding': 'IBM855', 'confidence': 0.20479192628309825, 'language': 'Russian'}
安装方法:pip
打开终端,输入pip install chardet (要在pip已经成功安装在电脑上才行)
编码和解码:
编码 encode 使用一个编码方式进行编码或者打开
unicode ----> encode 编码 -----> gbk\ utf-8 当内存里的数据要存储或者传输的时候用utf-8 保存
解码 decode
utf- 8 ----> decode 解码 ----> unicode 当硬盘的数据加载到内存中读取的时候,使用Unicode 读取
6、写模式操作文件 w\ wb
如果文件很大,在不占内存的情况下,处理完文件,可以进行边读边处理,把整个文件每次读一点,循环读完整个文件
# 循环语句读文件
f = open('file','r') for line in f: print(line) # print会自动换行,所以打印出来会空一行打印
print 具有打印完后,自动换行的功能
写文件:
f = open('younggirl', 'w', encoding='utf-8') # 使用w ,会自动创建这个文件 # 文件编码是utf-8 ,加载到内存后,是自动转换成Unicode 读取 f.write('today is monday') f.write('tomorrow is tuesday') # write 是不会自己换行的 f.close()
创建一个二进制的文件,写内容的时候 要标志编码类型,才能顺利写入:
7、追加模式 a \ ab :把文件追加到文件尾部:
1 f = open('file', mode = 'a', encoding = 'gbk')
8、文件读、写混合模式(r+):先读后写
f = open(file='hello1', mode='r+', encoding='gbk') print(f1.read()) f.write('\nahhahah') f.write('\n111111') print(f.read()) f1.close() 只会打印第一个print,因为先读 后写,写完之后,文件中的光标已经在最后一个,再读的话,已经没有内容可读了
9、文件写、读模式(w+):先清空,后写入内容
10、文件处理的其他功能:
fileno:
返回文件句柄在内核中的索引值,以后做IO多路复用时可以用到
flush:
把文件从内存buffer里强制刷新到硬盘
在内存里写入文件的时候,没有真正的写到文件中,只有close,才会存入
当内存的buffer满了之后,才会自动刷到硬盘
如果要强制刷入硬盘,可以中间用flush
readable:
判断是否可读
- 在Linux中,一切皆文件(连一个安装包、视频、终端都是文件)所以要判断文件是否可读才能正常读取
- 当文件是w模式的时候,是不能读取文件的
readline:
只读一行内容,遇到\n 、 \r 结束读取
\r前面的字符不打印,后面的才打印
\n打印前面的字符
seek:
把操作文件的光标移动到指定位置
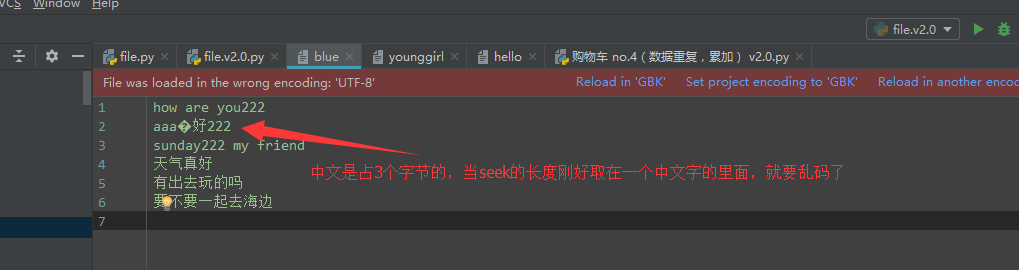
f.seek(10): 长度是按照字节算的,但是不同的字符编码所占用的字节长度是不一样的,当不知道字符编码的时候,错用seek,会出现乱码
f = open('blue', 'r+', encoding='utf-8') f.seek(15) f.write('aaa') f.close()
seekable:判断是否可移动
tell:
读取当前光标的位置(字节的长度)
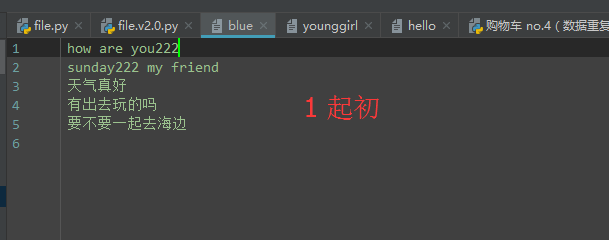
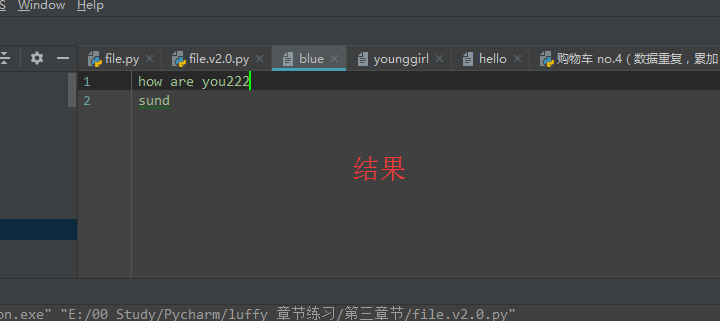
truncate:
按指定长度截断文件,从当前位置往后面删除
1 f = open('blue', 'r+', encoding='utf-8') 2 f.truncate(20) 3 f.close()
11、修改文件
使用seek,把光标移动到文件的中间
f = open('blue', 'r+', encoding='utf-8') f.seek(6) f.write('用seek插入字符') f.close()
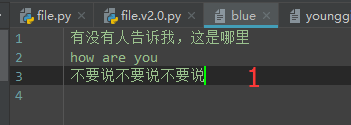
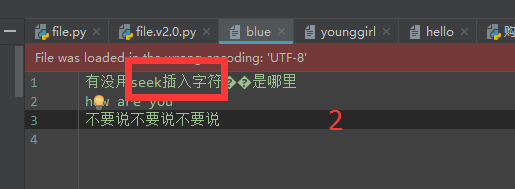
以上问题: 把有一些内容被替换掉了,没有直接插入,
还有可能会出现乱码(输入字节3个的话,剩下的多了一个出来,就乱码了) 这个和存储原理导致的
解决方法:
方法1: 占硬盘方式的文件修改代码
要边读边修改,写到新的文件里
f = 'blue' f_new = '{}.new'.format(f) old_str = 'how' new_str = 'how222.how' file = open(f, 'r', encoding='utf-8') file_new = open(f_new, 'w', encoding='utf-8') for line in file: if old_str in line: new_line = line.replace(old_str, new_str) else: new_line = line file_new.write(new_line) file.close() file_new.close()
方法2:若想覆盖原先的文件
上面的代码是生成了一个新的文件,如果想要覆盖,需要使用第三方模块
import os # 以下代码可上面一样
f = 'blue'
f_new = '{}.new'.format(f)
old_str = 'how'
new_str = 'how222.how'
file = open(f, 'r', encoding='utf-8')
file_new = open(f_new, 'w', encoding='utf-8')
for line in file:
if old_str in line:
new_line = line.replace(old_str, new_str)
else:
new_line = line
file_new.write(new_line)
file.close()
file_new.close()
os.rename(file_new, file)
# 新文件名字改成原先的名字
# Windows 的方法有点不一样 os.replace
# 帮助文档说明replace会覆盖原文件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号