python读取/创建XML文件
Python中定义了很多处理XML的函数,如xml.dom,它会在处理文件之前,将根据xml文件构建的树状数据存在内存。还有xml.sax,它实现了SAX API,这个模块牺牲了便捷性,换取了速度和减少内存占用。
本文将要说明的是xml.tree.ElementTree的使用。与DOM比较,它使用起来更快更方便,和SAX比较呢,性能相仿,但使用起来更快捷。
ET(ElementTree)提供了两个对象:ElementTree和Element
ElementTree:将整个XML转化为树,对整个XML文档进行操作(读取,写入,查找等)一般在ElementTree层面进行。
Element:代表树上单个节点,对单个XML元素及其子元素进行操作,则是在Element层面进行。
1)加载整个文档(demo.xml):
import xml.etree.ElementTree as ET
tree = ET.ElementTree(file="demo.xml")
2)获取根元素
root = tree.getroot()
根元素是一个Element对象,它具有以下属性:
root.tag:返回元素的标签名
root.attrib:以字典形式返回属性名和值
3)根元素本身就是一个可迭代对象,和其他Element对象一样,也具备直接遍历子元素的接口
for child in root:
print(child.tag, child.attrib)
也可以通过索引来访问特定的子元素 root[1].tag
4)查找需要的元素:find,findall, findText,iterfind等
find(tagName):总是返回第一个匹配的元素
findall(tagName):返回当前元素下一级所有匹配的元素列表
findtext:
iterfind(tagName):作用和findall一样,但是它返回的是一个生成器。
4)要想找到当前元素下所有元素,而不是只找到下一级元素
list(root.iter()) #列出根元素下所有子节点列表
list(root.iter(tagName)) # 列出所有标签名为tagName的子节点
5)正则表达式的使用:
*:所有 ---------> root.find("Menues/*") 查找路径Menus下面的所有子节点
.:当前元素---------->root.find(./*) 查找当前元素下的所有子节点
//:------------> root.findall(".//Menu"):查找当前目录下任意层级的标签名为Menu的子元素
..:------------>root.findall(".//Menu/.."):查找当前目录下任意层级的标签名为Menu的子元素的父元素
[@attrib]:根据指定的属性搜索元素
[@attrib='value']:根据给定属性名搜索元素--------->root.findall("Tab[@type='subabsent']"):找到所有type为subabsent的Tab标签
[tag]:----->root.findall("Tab[Menues]"):找到包含子元素为Menues的Tab标签
[tag='text']:---------->root.findall("Tab[Menues=5]"):找到包含Menues标签,且Menues标签中间text值为5的Tab元素
[position]:----->根据元素位置找相应的元素,从1开始: root.findall("Tab[1]") root.findall("Tab[last()-1]"):找到倒数第二个元素
写入XML文件:
调用ElementTree的write函数:ElementTree.write(file)
def pretty(e,level=0):
# 格式化xml文件
if len(e)>0:
e.text = "\n"+"\t"*(level+1)
for child in e:
pretty(child,level+1)
child.tail = child.tail[:-1]
e.tail = "\n"+"\t"*level
把如下CSV文件写入XML文件

---》
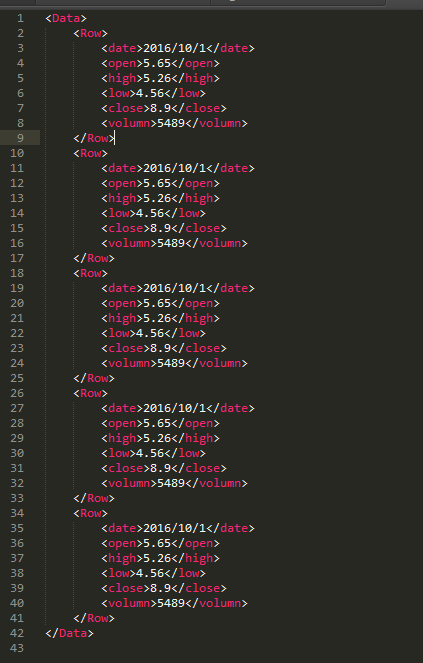
import xml.etree.ElementTree as ET
from xml.etree.ElementTree import ElementTree,Element
import csv
def WriteXML(csvfile):
# 把CSV文件写入到xml文件
with open(csvfile,"r") as rf:
reader = csv.reader(rf)
header = next(reader)
root = Element("Data")
for row in reader:
eRow = Element("Row")
root.append(eRow)
for tag, text in zip(header, row):
e = Element(tag.strip())
e.text = text.strip()
eRow.append(e)
pretty(root)
return ElementTree(root)

