YoutubeNet视频推荐技术博客
YoutubeNet是一种经典的推荐系统算法,本篇实现方式依托于山烛视频平台,该平台是一个为教育资源匮乏地区的孩子提供线上教育的视频平台,其主创团队连接:https://www.cnblogs.com/Growinglight/
技术概述
该技术的使用场景包括视频推荐、书籍推荐、文章推荐等,多用于在页面主页给用户推荐用户可能感兴趣的内容。学习该技术的原因:模型简单、速度快,满足在线使用的需求。 该技术的难点:论文的提到的结构可能和实际应用场景不同,需要对其进行数据预处理、修改网络结构。
技术详述
系统架构
总体来说,包括前端服务器、业务逻辑服务器、算法服务器和数据库。
在获取推荐这一过程中,这四者的交互过程如下:

除了获取推荐,算法服务器还需要每天定时更新模型、用户和视频的数据。为了使响应时间满足要求,网络模型和用户数据、视频数据作为临时变量一直存储在算法服务器中,每天要定时更新。定时更新的交互过程如下:

YoutubeNet模型详解
我们重点关注一下YoutubeNet是如何实现的,以及如何使模型适配山烛视频平台的项目要求。
网络结构
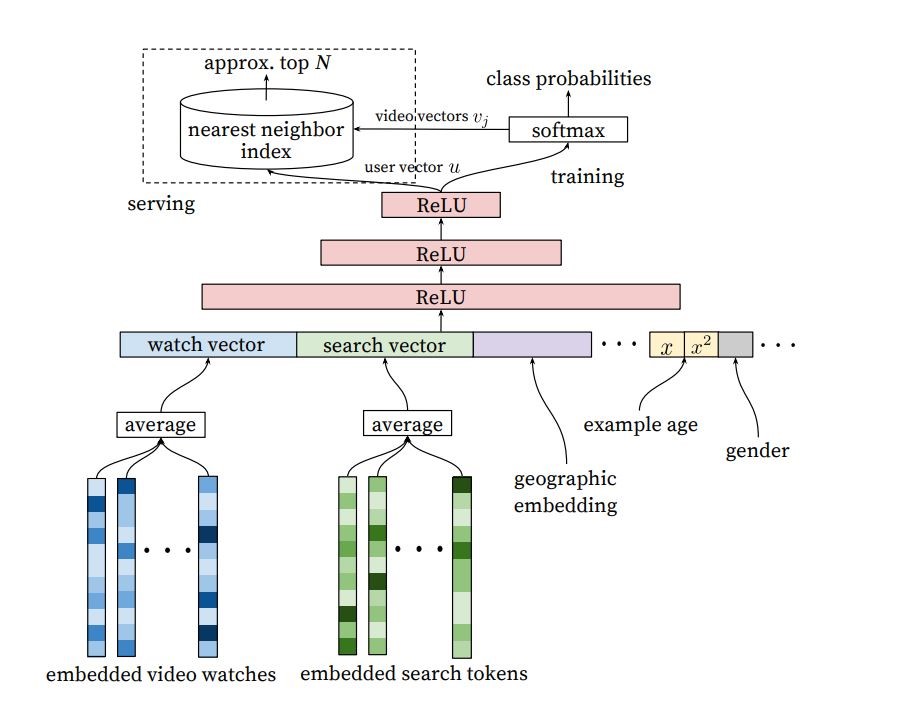
其网络结构如上,其实YotubeNet还包括召回和排序,因为排序主要利用用户观看视频的时间长度来对召回的视频进行逻辑回归,而我们平台并没有记录用户观看视频的时间,所以这里主要还是实现召回的网络结构。
数据预处理
由网路结构图我们可以看到,输入主要由三个部分组成,分别是embedded video watches, embedded search tokens, 后面那一串可以看成是用户相关的信息,即用户的特征。而输出层由一个softmax层表示,代表每一个视频的评分,评分高的优先推荐。那么,该模型就可以转化为一个多分类监督学习问题,输入是用户的历史观看视频的特征平均值、搜索记录的特征平均值(这里要用word2vec将单词转变为一个向量)、以及用户的特征,输出是用户下一次观看的视频的id。
首先是embedded video watches的构造,先从数据库中读取所有视频的信息
# 执行SQL语句
cursor.execute(sql)
# 获取所有记录列表
results = cursor.fetchall()
for row in results:
temp = []
temp.append(row[0]) # id 0
temp.append(time_to_integer(datetime.datetime.now()) - time_to_integer(row[4])) # 已经发布的天数 1
temp.append(row[6]) # 播放量 2
temp.append(row[8]) # 点击量 3
temp.append(np.where(types == row[10])[0][0]) # typeKey 需序列化 4
title_vector = getWordVector(row[1], w2v_model) # 视频标题,经过word2vec转为向量
temp = np.append(temp, title_vector)
videos.append(temp)
videosEmbedding = embeddingVideosData(np.asarray(videos))
可以看到这里主要保留了视频的id、发布的天数、视频播放量、视频点击量、视频的类型、视频的标题,所有特征组合在一起成为一个向量。
这里视频的类型要进行哑变量处理,即数据库中类型都是用1,2,3...来表示,这里要转变为[1 0 0],[0 1 0],[0 0 1],即把数字转变为向量,使其取值范围从连续 变为 离散。
这里还用pandas构造了dataframe,以方便后续检索。
def embeddingVideosData(videos):
# 对type进行哑变量处理
mycolumns = ["id", "time", "play", "click", "type"]
for i in range(300):
mycolumns.append("title" + str(i))
dataFrame = pd.DataFrame(videos, columns=mycolumns, index=videos[:, 0])
dummies_fields = ['type']
for each in dummies_fields:
dummies = pd.get_dummies(dataFrame.loc[:, each], prefix=each)
dataFrame = pd.concat([dataFrame, dummies], axis=1)
data_new = dataFrame.drop(dummies_fields, axis=1)
return data_new
对业务逻辑服务器发过来的用户历史观看记录和搜索记录,我们可以对其进行处理,得到类似于[(用户id,[视频1,视频2,视频3...],[搜索记录1,搜索记录2,搜索记录3...]),(用户id,[视频1,视频2,视频3...],[搜索记录1,搜索记录2,搜索记录3...])]的一个元组数组,每一个元组都可以构造一定数量的训练样本,例如,我们想考虑利用三个观看记录作为一次训练内容,则(用户信息,[视频1,视频2,视频3],搜索记录4)就是一个输入,视频4的id就是一个输出。(搜索记录4代表用户搜索了这个关键词才点击视频4,而视频1,2,3代表观看视频4之前用户的历史观看记录)。
具体代码如下:
# 首先加入用户的特征信息
tempx = np.append(tempx, np.asarray(userEmbedding)[0, 1:])
for i in range(len(history[1]) - usedHistoryNum):
tempAvg = np.zeros(videos.values.shape[1])
num = 0
for j in range(i, i + usedHistoryNum):
# error: 应该根据id而不是行号
if sum(videos.index == history[1][j]) != 0:
tempAvg += np.asarray(videos.loc[history[1][j]])
num = num + 1
tempAvg = tempAvg / num
# 加入历史观看视频特征
newRecord = np.append(tempx, tempAvg[1:])
# 插入搜索关键字特征
newRecord = np.append(newRecord, getWordVector(history[2][i], w2v_model))
newLabel = history[1][i + usedHistoryNum]
trainX = np.r_[trainX, newRecord]
rows = rows + 1
trainY = np.r_[trainY, newLabel]
word2vector的函数,先用结巴分词,再调用gensim.models的Word2Vec进行转换,将字符串转变为向量。
def getWordVector(convert_string, model):
words = jieba.cut_for_search(convert_string)
# model = Word2Vec.load("D:\机器学习课程\chinese_wiki_word2vec.model")
word_list = []
avg_vec = np.zeros(300)
for word in words:
word_list.append(word)
print("搜索关键词:" + convert_string + ",拆分为:" + (",").join(word_list))
wordlen = 0
for word in word_list:
try:
word_vector = model.wv[word]
wordlen = wordlen + 1
except KeyError:
word_vector = np.zeros(300)
avg_vec += np.asarray(word_vector)
if wordlen == 0:
return np.zeros(300)
return avg_vec / wordlen
用户的信息主要包括id、年龄和性别:
# 获得用户特征
selectUsers = "select id,age,gender from users;"
users = []
cursor.execute(selectUsers)
results = cursor.fetchall()
for row in results:
temp = []
temp.append(row[0]) # id
temp.append(row[1]) # age
if row[2] == '男':
gender = 1
else:
gender = 0
temp.append(gender) # gender
users.append(temp)
usersEmbedding = embeddingUsersData(np.asarray(users))
搭建神经网络
按照论文中的描写,该层神经网络的隐含层由三层ReLU全连接层构成,每层的神经元个数分别为1024、512、256,输入层取决于历史观看视频特征向量、历史搜索记录特征向量、以及用户特征向量这三者向量大小之和。输出层和视频id数一致,且激活函数为softmax。
def getTrainModel(resultsSize):
model = Sequential()
model.add(Dense(1024, input_dim=8 + 300 + 300, activation='relu'))
model.add(Dense(512, activation='relu'))
model.add(Dense(256, activation='relu'))
model.add(Dense(resultsSize + 1, activation='softmax')) # 从0开始
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
print(model.summary())
return model
获取推荐
根据用户id,用户历史浏览视频id,用户搜索关键字获取推荐。
def getRecommendationByUserId(uid, history, search_tokens, w2v_model, videos, users, model, usedHistoryNum):
userEmbedding = users.loc[[uid]]
inputData = np.asarray([])
# 拼接用户特征信息
inputData = np.append(inputData, np.asarray(userEmbedding)[0, 1:])
# 拼接视频特征信息
tempAvg = np.zeros(videos.values.shape[1] - 1)
if len(history) > usedHistoryNum:
for j in range(0, usedHistoryNum):
tempAvg += np.asarray(videos.iloc[[history[j]], :])[0, 1:]
tempAvg = tempAvg / usedHistoryNum
inputData = np.append(inputData, tempAvg)
search_vector = np.zeros(300)
# 拼接搜索关键字信息
for search_token in search_tokens:
search_token_vector = getWordVector(search_token, w2v_model)
search_vector += search_token_vector
if len(search_tokens) > 0:
search_vector = search_vector / len(search_tokens)
inputData = np.append(inputData, search_vector)
inputData = np.asarray([inputData])
# 获取神经网络输出
inputData = inputData.astype('float64')
recommendation = np.asarray(model.predict(inputData)[0])
# 分页起始地址
# bias = (pageIndex - 1) * pageSize
# 取分数最大视频id
sortArray = np.argsort(-recommendation)
result = []
for index in sortArray:
if sum(videos.index == index) != 0:
result.append(index)
return result[0:6]
flask相关代码
获取推荐的接口。
@app.route('/getRecommendation', methods=['POST'])
def getRecommendation():
data = request.json
jsonArray = data.get('history')
history = processJsonData(jsonArray)
if len(history) == 0:
recommendation = videos['id'].sample(n=6).values.tolist()
result = []
for item in recommendation:
result.append(int(item))
response = {
'data': result
}
return response
uid = history[0][0]
vid = history[0][1]
keys = history[0][2]
global predict_model
used_history_num = min(5, len(vid))
recommendation = getRecommendationByUserId(uid, vid, keys, w2v_model, videos, users, predict_model,
used_history_num)
result = []
for r in recommendation:
result.append(int(r))
response = {
'data': result
}
return response
训练的接口,该接口由业务逻辑服务器调用,定时训练。
可以看到,这里videos,users和model都声明为全局变量,以减少访问数据库的次数,减少响应时间。
# 定时执行这个函数
@app.route('/train', methods=['GET'])
def train():
global videos, users
videos, users = readDataFromDB(w2v_model)
# 获取训练数据
r = requests.get('http://150.158.191.172:8081/search/allUserSearchHistory')
response = r.json()
data = response['data']
print('训练数据:')
print(data)
history = processJsonData(data)
print('拆分为元组:')
print(history)
trainX, trainY, resultsSize = getTrainData(videos, users, w2v_model, history)
trainX = trainX.astype('float64')
trainY = trainY.astype('float64')
print(trainX.shape)
print(trainY.shape)
model = getTrainModel(resultsSize)
trainModel(trainX, trainY, model, epochs=300, batch_size=6)
global predict_model
predict_model = model
savePredictModel(predict_model, "VideoRecommendation.h5")
return {'msg': '谢谢你通知我'}
遇到的问题以及解决办法
问题一:flask和keras同时使用时会报错
同时使用flask和keras时,调用keras.models加载模型文件load_model会报TypeError: tuple indices must be integers, not list,经过检查,不是代码的问题(因为单独使用keras可以正常运行)。
解决方法:
在flask的app.run方法中令debug=False,threaded=False。好像是因为flask和keras的有线程上的冲突(具体原因没看源码我也不是很懂。。。)。
if __name__ == '__main__':
app.run(host="127.0.0.1", port=8000, debug=False, threaded=False)
问题二:如何进行分词,以及训练Word2Vec模型
在论文原文中利用word2vec来将字符串转为向量,其具体步骤如下:
1.收集语料库,即收集用户输入的字符串,以句子的方式保存
2.对句子进行分词,再调用Word2Vec的构造函数训练模型
有两个问题:
1.语料库怎么得?
2.对句子进行分词,英文的比较好分,只要按照空格隔开即可,中文词与词之间没有空格,要如何进行分词?
回答:
1.语料库可以直接调用现成的,例如维基百科中英文语料库(规模比较大,大概几十万篇文章)。也可以自己收集,当然这个要看条件允不允许这样做。
维基百科语料库下载地址
语料库处理,将.bz2文件转为txt文件,其中path_to_wiki_dump是语料库的地址,D:/网页下载/wiki_text.txt是输出文件的地址:
import logging
from gensim.corpora import WikiCorpus
def main():
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
logging.info("------------ the program is running -------------")
path_to_wiki_dump = "D:/网页下载/zhwiki-latest-pages-articles.xml.bz2"
wiki_corpus = WikiCorpus(path_to_wiki_dump, dictionary={})
num = 0
with open('D:/网页下载/wiki_text.txt', 'w', encoding='utf-8') as output:
for text in wiki_corpus.get_texts(): # get_texts() 将 wiki的一篇文章转为textd的一行
output.write(' '.join(text) + '\n')
num += 1
if num % 10 == 0:
logging.info("已处理 %d 文章" % num)
if num==100:
break
2.对语句进行分词处理,这里用的是结巴分词,可使用pip install jieba安装github网址
分词过后的文本存放在D:\网页下载\wiki_seg.txt中:
import jieba
import logging
def main():
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
stopword_set = set()
output = open('D:\网页下载\wiki_seg.txt', 'w', encoding='utf-8')
with open('D:\网页下载\OpenCC-1.0.5-Win64\simplified_sentence.txt', 'r', encoding='utf-8') as content:
for texts_num, line in enumerate(content): # enumerate 给 line前加序号
line = line.strip('\n')
words = jieba.cut(line, cut_all=False)
for word in words:
if word not in stopword_set:
output.write(word + ' ')
output.write('\n')
if (texts_num + 1) % 1000 == 0:
logging.info("已完成前 %d 行的断词" % (texts_num + 1))
if texts_num==2000:
break
output.close()
if __name__ == '__main__':
main()
最后,由分词过后的文件,就可以用来训练Word2Vec模型,训练完成后,可以将模型保存下来,重复使用:
from gensim.models import word2vec
import logging
def main():
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
sentences = word2vec.LineSentence("D:\网页下载\wiki_seg.txt")
#wiki的语料库比较大,这里向量特征取300维
model = word2vec.Word2Vec(sentences, vector_size=300, min_count=5,batch_words=1000) # size 用来设置神经网络的层数
model.save("D:\机器学习课程\chinese_wiki_word2vec_part.model")
if __name__ == "__main__":
main()
问题三:推荐视频中出现了未审核过的视频
在平台上线之前,我们小组的测试人员发现首页视频推荐竟然有未审核通过的视频,经检查,视频推荐时并没有对视频状态进行筛选,于是在从数据库中取数据时,添加了条件判断。
由
sql = "select * from course;"
转变为
sql = "select * from course where course_status=1;"
总结
该篇文章主要讲述如何利用flask和keras、tensorflow搭建一个视频推荐获取接口,其中涉及一些YoutubeNet的实现方式(主要还是召回模型的实现方式),同时还复习了一下结巴分词的用法。记录了一下编写代码中遇到的坑。
参考文献
[1]https://link.zhihu.com/?target=https%3A//static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/45530.pdf
[2]https://blog.csdn.net/qq_33278884/article/details/81987714
[3]https://zhuanlan.zhihu.com/p/52169807
[4]https://www.jianshu.com/p/47dfa461e72f?utm_campaign=maleskine&utm_content=note&utm_medium=seo_notes&utm_source=recommendation

 浙公网安备 33010602011771号
浙公网安备 33010602011771号