
HResults计算字错率(WER)、句错率(SER)
前言
好久没发文,看到仍有这么多关注的小伙伴,觉得不发篇文对不住。确实好久没有输出经验总结相关的文档,抽了个时间,整理了下笔记,发一篇关于ASR常用测试指标。比如字错率、句错率指标,以及计算工具HResults的使用篇,后续慢慢找时间输出一些人工智能领域,小白可理解可用的基础知识,或者整理一些其他笔记发一发。
转载说明
本文为原创文章,如需转载,请在开篇显著位置注明作者Findyou和出处
一、基础概念
1.1、语音识别(ASR)
语音识别(speech recognition)技术,也被称为自动语音识别(英语:Automatic Speech Recognition, ASR),
狭隘一点白话说:将语音转换为文字的技术。

Findyou:一般使用ASR缩写。
1.2、句错率(SER)
- 句错误率:Sentence Error Rate
- 解释:句子识别错误的的个数,除以总的句子个数即为SER
-
计算公式:(所有公式省了 * 100%)
SER = 错误句数 / 总句数
1.3、句正确率(S.Corr)
- 句正确率:Sentence Correct
-
计算公式:
S.Corr = 1 - SER = 正确句数 / 总句数
1.4、字错率(WER/CER)
WER,Word error rate,词错率,但一般称为字错率,是语音识别领域的关键性评估指标,WER越低表示效果越好!
CER,Character Error Rate,字符错误率,中文一般用CER来表示字错率,原因请见1.4.3。
»1.4.1 、计算原理
字符串编辑距离(Levenshtein距离)算法
»1.4.2、计算公式(重要)
WER = (S + D + I ) / N = (S + D + I ) / (S + D + H )

(公式图片和文字一样,仅方便拷贝)
- S 为替换的字数,常用缩写WS
- D 为删除的字数,常用缩写WD
- I 为插入的字数,常用缩写WI
- H 为正确的字数,维基百科是C,但我统一改用H
- N 为(S替换+ D删除+ H正确)的字数
Findyou:
1.正确的字数:维基百科里用的是C代表,H = N - (S+D) = C,我这边直接改成H,减少过多概念与变量。
2.大多数文章都没有给出N的计算方式,很容易误以为是原句总字数或者识别结果总字数。
3.不理解没关系,下面实例会帮助理解。
»1.4.3、 问题
- 问题1:为什么WER会大于100%
因为有插入字(识别多出来的字),所以理论上WER有可能大于100%,在下面实例我会举例(请见2.3.5),但实际场景,特别是大样本量的时候,基本太不可能出现。
- 问题2:说中文应该用CER,即“字符错误率”(Character Error Rate)
Findyou举个栗子:
英文:hello # 算一个Word 中文:你好 # 算两个字符
啰嗦文字解释,就是:
英文,因为最小单元是Word,语音识别应该用"字错误率"(WER),
中文,因为最小单元是字符,语音识别应该用“字符错误率”(CER)。
BUT(就是但是的意思...),他跟我前面那一句一样,说的都是废话!
我们计算的时候谁不是按:中文的一个字符 = 英文的一个Word,那这样用WER的公式有什么问题呢?
谁再跟你咬文嚼字,怼他,使劲怼!
怼完,说回严谨的话,建议采用CER表示,哈哈哈哈哈......
1.5、字正确率(W.Corr)
字正确率,Word Correct,一般国内宣传用的多,识别率(识别正确率)达到多少多少(请见1.7)。
-
计算公式
W.Corr = ( N - D - S ) / N = H / N
-
问题:只计算了识别正确的字,没有管多出来的字(I插入),当然一般情况下不会有什么问题。
1.6、字准确率(W.Acc)
字准确率,Word Accuracy
-
计算公式
W.Acc = 1 - WER = ( N - D - S - I ) / N = (H - I) / N
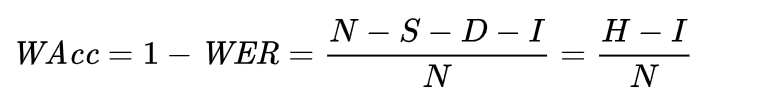
(图片和文字一样,方便拷贝,W.Acc是Findyou自己用的简写)
- 特殊情况:当 I=0 时, W.Acc = W.Corr
-
问题:为什么W.Acc会是负数?
同WER,因为有插入字。换个说法,因为字准确率=1 - WER,而WER可能大于1,所以W.Acc会出现负数,但实际情况基本不存在。
1.7、聊点其他
-
ASR影响素因
- 人群:男、女、老人、小孩...
- 音量)
- 距离(与拾音设备的距离)
- 角度(与拾音设备的角度)
- 设备(拾音设备的硬件)
- 环境:安静、嘈杂(自噪、外噪)、家庭、商场...
- 句长
- 口音、方言
- 语速
- 语言:中文、英语
- 等等
大概举例几个影响因素(懒得放脑图,文字也方便大家拷贝),
因为ASR的识别影响因素过多,所以很多时候会从各种纬度测试,比如:男生字错率、女生字错率,或者小孩字错率、平均字错率等等,
如果没有公布测试数据与方法,不可信,因会存在几个操作,最大的问题是:
过拟合:训练数据、测试数据、验证数据是同一份,打外比方说:要考试的卷子就是你前一天发的老师发的练习卷还带答案的。
先扯到这,后面找时间再整理一篇ASR测试方法系统讲一讲,
做为测试我们如何去测ASR以及制定各种测试标准。
-
行业水平
-
- 英语-WER;
- IBM:行业标准Switchboard语音识别任务,2016年 6.9%,2017年 5.5%
- 微软:行业标准Switchboard语音识别任务,2016年 6.3% -> 5.9%,2017年 5.1%,这个目前最低的。
- 英语-WER;
说明:ICASSP2017上IBM说人类速记员WER是5.1%,一般认为5.9% 的字错率是人类速记员的水平。
-
- 中文-WER/CER:
- 小米:2018年 小米电视 2.81%
- 百度:2016年 短语识别 3.7%
- 中文-W.Corr:
- 百度:2016年 识别准确率 97%
- 搜狗:2016年 识别准确率 97%
- 讯飞:2016年 识别准确率 97%
- 中文-WER/CER:
Findyou部分数据来源:
微软WER 5.9%:https://arxiv.org/abs/1610.05256
微软WER 5.1%: https://www.microsoft.com/en-us/research/wp-content/uploads/2017/08/ms_swbd17-2.pdf
小米电视CER 2.81% :https://arxiv.org/pdf/1707.07167.pdf
国内百度等同时宣布识别准确率97% : https://www.zhihu.com/question/53001402
二、HTK工具
了解了ASR相关的指标,需要有工具来进行结果统计计算,
本次主要介绍HTK工具,python也有Levenshtein的库,但没有HResults现成的来的简单。
2.1、HTK工具简介
HTK工具,HTK(HMM Toolkit)一款基于HMM模型(隐马尔可夫模型)的语音处理工具,HTK主要用于语音识别研究,尽管它已被用于许多其他应用,包括语音合成,字符识别和DNA测序的研究。HTK最初是在剑桥大学工程系(CUED)的机器智能实验室 (以前称为语音视觉和机器人小组)开发的。后版权辗转到Microsoft,其保留了原始HTK代码的版权,具体介绍请移步HTK官网。
- HTK官方主页:http://htk.eng.cam.ac.uk/
- 最新稳定版:HTK 3.4.1
- 最新版:HTK 3.5
Findyou:下载你需要先注册用户,记住你的密码,FTP下载的时候需要。
2.2、HResults简介与使用
HTK有一系列工具,但我主要想写的是HResults。
Centos系统编译后的HTK3.4.1版本,HResults下载地址
百度网盘: https://pan.baidu.com/s/1gfm9jjqjZzJXU0lyGrLrCA 提取码: wbfp
»2.2.1 、使用帮助
$ HResults
USAGE: HResults [options] labelList recFiles... Option Default -a s Redefine string level label SENT -b s Redefine unitlevel label WORD -c Ignore case differences off -d N Find best of N levels 1 -e s t Label t is equivalent to s -f Enable full results off -g fmt Set test label format to fmt HTK -h Enable NIST style formatting off -k s Results per spkr using mask s off -m N Process only the first N rec files all -n Use NIST alignment procedure off -p Output phoneme statistics off -s Strip triphone contexts off -t Output time aligned transcriptions off -u f False alarm time units (hours) 1.0 -w Enable word spotting analysis off -z s Redefine null class name to s ??? -A Print command line arguments off -C cf Set config file to cf default -D Display configuration variables off -G fmt Set source label format to fmt as config -I mlf Load master label file mlf -L dir Set input label (or net) dir current -S f Set script file to f none -T N Set trace flags to N 0 -V Print version information off -X ext Set input label (or net) file ext lab
HTKBook: https://labrosa.ee.columbia.edu/doc/HTKBook21/node233.html
»2.2.2 、文本转换为MLF文件
- 测试用例:src.txt (暂时不要去管专业术语)
1 今天天气怎么样
2 明天天气怎么样
Findyou:
1.第一列是数字,主要是为了与ASR结果一一对应
2.我们一般会剔除标点符号计算WER,所以注意去标点符号
- src.txt - > src.mlf 文件
#!MLF!# "*No1.lab" 今 天 天 气 怎 么 样 . "*No2.lab" 明 天 天 气 怎 么 样 .
Findyou:
1.注意第一行加:#!MLF!#
2.注意"*xxx.lab"
3.注意每句的点
- ASR识别结果:testResult.txt 文件
1 惊天天气
2 明天天气怎么样
Findyou:
1.很多时间是自动化执行,或手工执行得到识别结果
2.测试结果,第一列应该与src.txt对齐,通过第一列来识别需要对比的语料。
例:HResults 会根据 "*No1.lab" 对应 "*No1.rec" 来找到对应的文本计算WER。
- testResult.txt - > testResult.mlf 文件
#!MLF!# "*No1.rec" 惊 天 天 气 . "*No2.rec" 明 天 天 气 怎 么 样 .
Findyou:
1.txt转换到mlf可以用脚本转换,注意双个mlf文件的不同,lab与rec关键字。
»2.2.3 、TXT转换为MLF脚本
- src2mlf.py
1 #-*- coding:utf-8 -*- 2 import os,sys 3 4 def to_mlf(xi): 5 dx={ 6 "0":"零", 7 "1":"一", 8 "2":"二", 9 "3":"三", 10 "4":"四", 11 "5":"五", 12 "6":"六", 13 "7":"七", 14 "8":"八", 15 "9":"九" 16 }; 17 d=[] 18 eng=[] 19 tx=[",",".","!","(",")",",","。","!",';','、',':','?','“','”']; 20 for x in xi: 21 u=x.encode("utf-8") 22 if u in tx: 23 continue; 24 if len(u)==1: 25 if u in dx: 26 u=dx[u] 27 eng.append(str(u, encoding='utf-8')) 28 else: 29 if len(eng)>0: 30 d.append("".join(eng).upper()) 31 eng=[] 32 d.append(str(u, encoding='utf-8')) 33 if len(eng)>0: 34 d.append("".join(eng).upper()) 35 return d 36 37 def fn_to_lab(s): 38 x=s.split() 39 for i in x: 40 d=to_mlf(i.strip()) 41 if len(d)>0: 42 print("\n".join(d)) 43 print('.') 44 45 fn=sys.argv[1] 46 print('#!MLF!#') 47 for l in open(fn): 48 l=l.strip() 49 x=l.split() 50 k=x[0].strip() 51 v=" ".join(x[1:]) 52 t=".".join(k) 53 print('"*No%s.lab" ' % t) 54 fn_to_lab(v)
Findyou:
1.此脚本是将测试用例转为src.mlf
2.如需将测试结果testResult.txt 转testResult.mlf,则拷贝一份如 rec2mlf.py,改第53行的关键字lab为rec即可。
- 脚本使用
1 python src2mlf.py src.txt >src.mlf 2 python rec2mlf.py testResult.txt >testResult.mlf
»2.2.4 、常用命令
以上文2.2.2 举例文本为例
-
HResults -t -I src.mlf /dev/null testResult.mlf
Aligned transcription: *No.1.lab vs *No.1.rec LAB: 今 天 天 气 好 吗 REC: 惊 天 天 气 ,-------------------------------------------------------------. | HTK Results Analysis at Wed Apr 3 16:26:59 2019 | | Ref: src.mlf | | Rec: testResult.mlf | |=============================================================| | # Snt | Corr Sub Del Ins Err S. Err | |-------------------------------------------------------------| | Sum/Avg | 2 | 76.92 7.69 15.38 0.00 23.08 50.00 | `-------------------------------------------------------------'
-
HResults -t -I src.mlf /dev/null testResult.mlf
Aligned transcription: *No.1.lab vs *No.1.rec LAB: 今 天 天 气 好 吗 REC: 惊 天 天 气 ====================== HTK Results Analysis ======================= Date: Wed Apr 3 16:26:59 2019 Ref : src.mlf Rec : testResult.mlf ------------------------ Overall Results -------------------------- SENT: %Correct=50.00 [H=1, S=1, N=2] WORD: %Corr=76.92, Acc=76.92 [H=10, D=2, S=1, I=0, N=13] ===================================================================
2.3、HResults样例解析
以一句测试用例与测试结果为例,举实例让大家快速了解HResults的WER。
»2.3.1 只有删除(D)
# 说明 LAB:测试用例 REC:识别结果 # 结果 Aligned transcription: *No.1.lab vs *No.1.rec LAB: 今 天 天 气 怎 么 样 REC: 今 天 天 气 ,-------------------------------------------------------------. | HTK Results Analysis at Tue Apr 2 22:37:09 2019 | | Ref: src.mlf | | Rec: testResult.mlf | |=============================================================| | # Snt | Corr Sub Del Ins Err S. Err | |-------------------------------------------------------------| | Sum/Avg | 1 | 57.14 0.00 42.86 0.00 42.86 100.00 | `-------------------------------------------------------------' ... ------------------------ Overall Results -------------------------- SENT: %Correct=0.00 [H=0, S=1, N=1] WORD: %Corr=57.14, Acc=57.14 [H=4, D=3, S=0, I=0, N=7] ===================================================================
- SER(句错率) = 1 / 1 = 100 %
- S.Correct(句正确率) = 0 S.H / 1 S.N = 0.00 %
- N = 0替换 + 3删除 + 4正确 = 7
- WER(字错率) = ( S 0 + D 3 + I 0 ) / 7 = 42.86 %
- W.Correct(字正确率) = H / N = 4 / 7 = 57.14 %
- W.Accuracy(字准确率) = (H - I)/ N = 1 - W.Err = 57.14 %
»2.3.2 替换(S) + 删除(D)
LAB: 今 天 天 气 怎 么 样 REC: 惊 天 天 气 # 结果 ... |=============================================================| | # Snt | Corr Sub Del Ins Err S. Err | |-------------------------------------------------------------| | Sum/Avg | 1 | 42.86 14.29 42.86 0.00 57.14 100.00 | `-------------------------------------------------------------' ... SENT: %Correct=0.00 [H=0, S=1, N=1] WORD: %Corr=42.86, Acc=42.86 [H=3, D=3, S=1, I=0, N=7]
- SER = 1 - S.Corr = 100 %
- S.Correct = S.H / S.N = 0.00 %
- N = 1替 + 3删 + 3H = 7
- WER = (S + D + I ) / N = 57.14 %
- W.Correct = H / N = 42.86 %
- W.Accuracy = (H - I) / N = 1 - W.Err = 42.86 %
»2.3.3 替换(S) + 删除(D) + 插入(I)
LAB: 今 天 天 气 怎 么 样 REC: 惊 天 田 天 气 # 结果 ... |=============================================================| | # Snt | Corr Sub Del Ins Err S. Err | |-------------------------------------------------------------| | Sum/Avg | 1 | 42.86 14.29 42.86 14.29 71.43 100.00 | `-------------------------------------------------------------' ... SENT: %Correct=0.00 [H=0, S=1, N=1] WORD: %Corr=42.86, Acc=28.57 [H=3, D=3, S=1, I=1, N=7]
- SER = 1 - S.Corr = 100 %
- S.Correct = S.H / S.N = 0.00 %
- N = 1S + 3D + 3H = 7
- WER = (S + D + I) / N = 5/7 = 71.43 %
- W.Correct = H / N = 42.86 %
- W.Accuracy = (H - I) / N = 1 - W.Err = 28.57 %
»2.3.4 全错(结果字数<语料字数)
LAB: 今 天 天 气 好 吗 REC: 不 知 道
... |=============================================================| | # Snt | Corr Sub Del Ins Err S. Err | |-------------------------------------------------------------| | Sum/Avg | 1 | 0.00 50.00 50.00 0.00 100.00 100.00 | `-------------------------------------------------------------' ... SENT: %Correct=0.00 [H=0, S=1, N=1] WORD: %Corr=0.00, Acc=0.00 [H=0, D=3, S=3, I=0, N=6]
- SER = 1 - S.Corr = 100 %
- S.Correct = S.H / S.N = 0.00 %
- N = 3S + 3D + 0H = 6
- WER = (S + D + I) / N = 6/6 = 100.00 %
- W.Correct = H / N = 0.00 %
- W.Accuracy = (H - I) / N = 1 - W.Err = 0.00 %
»2.3.5 全错(结果字数>语料字数)
LAB: 今 天 天 气 好 吗 REC: 惊 田 田 七 豪 嘛 嘛 ... |=============================================================| | # Snt | Corr Sub Del Ins Err S. Err | |-------------------------------------------------------------| | Sum/Avg | 1 | 0.00 100.00 0.00 16.67 116.67 100.00 | `-------------------------------------------------------------' ... SENT: %Correct=0.00 [H=0, S=1, N=1] WORD: %Corr=0.00, Acc=-16.67 [H=0, D=0, S=6, I=1, N=6]
- SER = 1 - S.Corr = 100 %
- S.Correct = S.H / S.N = 0.00 %
- N = 6S + 0D + 0H = 6
- WER = (S + D + I) / N = 7/6 = 116.67 %
- W.Correct = H / N = 0.00 %
- W.Accuracy = (H - I) / N = 1 - W.Err = -16.67 %
转载说明
本文为原创文章,如需转载,请在开篇显著位置注明作者Findyou和出处

 浙公网安备 33010602011771号
浙公网安备 33010602011771号