



百度网盘背后的存储系统atlas
百度网盘免费提供2TB存储, 它的存储量一定是惊人的, 支持它的存储系统atlas也是相当不错的。 atlas是一个KV存储, 支持GET/PUT/DELETE三个接口, 看起来接口简单, 但要做好这么一个大规模系统非常不易, 我们来看看atlas到底长啥样。

atlas基于如图所示arm存储机, 2U放6个机器, 每个机器4核、4GB内存、4个3T硬盘, 2U总共72TB存储, 相比普通机架服务器,存储密度提升1倍。arm存储机的内存量过小, 而文件系统产生的元数据过大, 考虑性能原因不能把文件存储成文件。 甚至也不能采用haystack存储方式, haystack元数据虽然小, 但也超过ARM存储机的内存量。

atlas架构如上图所示, altas采用分布式元数据管理机制, 根据哈希策略将对象元数据切片成N个slice, 这些slice交由PIS(Patch and Index Server)集群管理, 每个PIS节点负责管理多个slice。 slice到PIS的映射表通过元数据服务器管理(图中未画出), 映射表较小,能被客户端全量缓存。
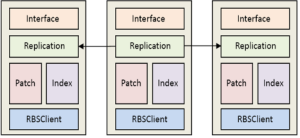
PIS的结构如上图所示, replication模块以主从复制方式保证slice三副本一致性。 写请求发往主节点, 主节点生成唯一请求ID之后将ID和请求转发给从节点, 从节点接收到请求之后, 追加到patch模块维护的log文件。 请求ID的作用是串行化写, 即从节点按照ID排序串行化执行请求。 主节点至少收到一个从节点的响应后, 将KV写入本地, 并告诉客户端写成功。 (如何保证一致性?)。 patch文件长度达到64MB时, PIS新开一个patch文件处理写请求, 调用RBSClient将满64MB的块写入到RBS系统中, 并将对象元数据(即对象的key,以及对象的存储位置:RBS块,偏移,长度)记录到Index中。
RBS(RAID-like Block System), 是一个64MB大块存储系统, 支持随机读取, 整块写入和删除, 不支持随机写。 PartServer负责数据存储, RBS Master负责记录块的位置信息, 并负责集群管理和数据恢复工作, 而RBSClient是提供给应用的开发包。 RBS采用纠删码技术保障数据可靠性, 写入数据时, RBSClient将64MB大块切分为8个8MB part,用RS纠删码生成另外4个8MB 校验part, 保存这12个part到PartServer。
对象读取流程。 对象数据是先进patch后转移到RBS, 所以读也是要先读patch, patch命中则直接返回, 若不命中则查index得到对象位置信息, 再根据位置信息从RBS读取数据。
删除和垃圾回收。 如果对象在patch中则直接删除,反之若对象在RBS中,则从index中删除对象元数据, 删除对象空间不会马上回收, 而是留在RBS中形成垃圾数据。 垃圾回收的思路是使用map-reduce扫描所有index数据, 计算RBS块的空间率, 针对空闲率大于一定阈值的块, 读取有效数据,写回到RBS, 更新index, 最后删除块。
atlas是优秀的KV存储系统, 非常适合于网盘类应用。其最大的特色是软硬件协同设计, 基于arm存储和纠删码极大降低了存储成本。 atlas垃圾回收的成本较高, 删除较多的应用场景下效率可能会有问题。
文献atlas: baidu’s key-value storage system
http://www.open-open.com/lib/view/open1437919655143.html

