
控制台程序的中文输出乱码问题(export LC_CTYPE=zh_CN.GBK,或者修改/etc/sysconfig/i18n为zh_CN.GBK。使用setlocale(LC_CTYPE, "");会使用默认办法。编译器会将源码做转换成Unicode格式,或者指定gcc的输入文件的编码参数-finput-charset=GBK。Linux下应该用wprintf(L"%ls/n",wstr))
今天发现用securecrt登陆时,gcc编译出错时会出现乱码,但直接在主机的窗口界面下用Shell编译却没有乱码。查看了一下当时的错误描述,发现它的引号是中文引号,导致在SecureCRT中显示出错:
before numeric constant
在网上查了一下,可以通过修改LC_CTYPE=zh_CN.GBK解决这个问题,具体的方法有两个:
1. 通过export命令修改LC_CTYPE变量的值
tianfang > export LC_CTYPE=zh_CN.GBK
tianfang > gcc main.c
main.c:1:1: error: expected identifier or '(' before numeric constant
tianfang >
2. 修改/etc/sysconfig/language(大部分linux版本下这个文件叫/etc/sysconfig/i18n)中的变量设置,重新登陆后生效。
#RC_LC_CTYPE=""
RC_LC_CTYPE="zh_CN.GBK"
我个人比较推荐方法2。
#include <stdio.h>
#include <wchar.h>
int main(void) {
char str[] = "中文";
wchar_t wstr[] = L"中文";
printf("1:%s\n", str);
wprintf(L"2:%s\n", wstr);
return 0;
}Windows平台下VS2008输出:

Windows平台下MinGW输出:
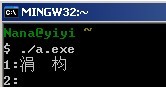
当加上setlocale函数设定后,
#include <stdio.h>
#include <locale.h>
#include <wchar.h>
int main(void) {
setlocale(LC_CTYPE, "");
char str[] = "中文";
wchar_t wstr[] = L"中文";
printf("1:%s\n", str);
wprintf(L"2:%s\n", wstr);
return 0;
}
输出分别为:
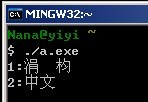
为解其中各种纷乱的纠结,又让我一个美好的下午就此悲剧= =.
=============================================================分割线
这档子事还得从字符编码说起.关于字符集和编码的基础知识,请看咱昨天写的 字符集相关知识的简单总结.
这里涉及到一个字符在源代码(文本)中,编译好的二进制文件中,以及最后控制台输出编码形式的区别.
首先,要明确一点:C(语言/程序)并不理解ANSI,UTF-8以及任何其他编码.它只知道处理你给它的字符的二进制表示.
在简体中文Windows下,默认的文本保存编码是ANSI(即GBK);Linux下根据系统locale设定,一般应该是(zh_CN.UTF-8).(以下基于简体中文Windows)
1)对于源文件中保存的"中文"这个字符串,VS2008看到的就是"0xd6d0"和"0xcec4"的形式(默认ANSI编码得到).但编译器才不管是不是GBK神马的,它就管那串数字.
区别,MinGW看到的是"0xe4b8ad"和"0xe69687"(gcc默认UTF-8).注意,用MinGW编译的源文件中有中文宽字符必须保存为UTF-8编码.
2)然后,在二进制文件中的存储形式,对传统的字符串(char str[] = "中文";),编译器什么都不做,直接把那串数字(如"0xd6d0","0xcec4")搬过去塞进二进制文件.
但对于宽字符串(wchar_t wstr[] = L"中文";),编译器会将其做转换,转换成Unicode编码格式(在Windows是UTF-16,而Linux下是UTF-32).如"中文"的16位Unicode是"0x4e2d"和"0x6587",然后把这串转换后的数字("0x4e2d","0x6587")塞进二进制文件中.(这里VS和MinGW做的没有区别)
这里有点需要注意,编译器必须知道你的源文件保存的编码!如VS默认是ANSI编码,如果你用UTF-8保存.c源文件去用VS打开看一定是乱码.同理如果你用mingw编译ANSI编码保存的源文件,也会出错!(但可以修改编译选项解决,见文章末尾) 在本文这里这个原因其实很好理解,因为编译器需要知道,如果它要将一个保存在文件中的字符转成宽字符时,是从什么编码转到Unicode.(可见上述VS是GBK->Unicode,而MinGW是UTF-8->Unicode)
来小结下"中""文"的3种编码:
ANSI(GBK): 0xd6d0 0xcec4
UTF-8: 0xe4b8ad 0xe69687
Unicode: 0x4e2d 0x6587
到这里,一切都还正常~
3)控制台的输出是问题关键!在简体中文Windows下的控制台显示环境是ANSI编码(代码页936, GBK),先明确这点.
对于传统字符串输出printf("%s\n", str);程序运行时,直接将二进制文件中存储的那串数字丢进输出流.到这里,你该发现了吧:str保存在文件中是GBK,存储在二进制文件中是GBK,到控制台的输出环境也是GBK!三者一致,自然输出正常.(当然,如果你修改三者中任一的一个编码,输出结果都会不一样)
但对于宽字符串呢,wprintf(L"%s\n", wstr);会怎么做?wprintf会先二进制文件的Unicode编码那串东西转成本地区域编码,然后丢进输出流.哦!这本地区域编码程序是怎么得到就成关键中的关键了.这时咱们来看看setlocale这个函数吧.(看这里看这里>o<)
setlocale是用来程序运行时,设置当前的区域信息. 函数参数格式这里就不介绍了,请看上面链接或Google.
值得注意是: 在所有C程序启动前,locale的默认设置setlocale(LC_ALL,"C");会被执行.
那"C"是什么环境呢?
The "C" locale is the minimal locale. It is a rather neutral locale which has the same settings across all systems and compilers, and therefore the exact results of a program using this locale are predictable. This is the locale used by default on all C programs.
其实这么看咱也没弄懂"C"具体是个啥区域环境,暂且鉴定为是指那个只认128字符的编码环境吧.(反正它不认中文= =)
所以,输出时Unicode编码默认转成这个C环境编码,然后丢进输出流.而控制台的显示环境默认是GBK啊,这不就乱了吗!所以乱码啦~
解决办法就是在程序中加上setlocale(LC_CTYPE, "");
LC_CTYPE表示C字符串相关的处理.而双引号中是对应的locale字符串,如果什么都不写就从当前系统获得默认的环境编码.当然你也可以手动写成setlocale(LC_CTYPE, "chs"); 一样的.
这时候,程序输出时将Unicode编码的字串转成系统的默认编码(Windows下是ANSI),而Windows系统默认编码一般都与控制台环境编码一致,OK~正常输出了.
等等!在加了setlocale函数后的VS2008两个"中文"都输出正确了,而MinGW怎么第一个却还是乱码"涓枃"?! 这是当然啦,忘了吗?MinGW的源文件保存的编码格式是UTF-8啊.并且程序将文本保存的UTF-8编码(0xe4b8ad和0xe69687)塞进二进制文件中,输出时也没做转换,又直接将那串UTF-8编码丢进输出流,在GBK环境的控制台输出,实际过程就相当于UTF-8==>GBK,要知道UTF-8与GBK可不兼容啊,这样输出显示的结果注定是乱码啊!
一切都清晰了是不是~
=============================================================又见分割线
在<浅谈C中的wprintf和宽字符显示>一文中,指出在Linux平台下
wchar_t wstr[] = L"中文";
setlocale(LC_ALL, "zh_CN.UTF-8");
wprintf(L"%s/n",wstr);这样依然存在输出乱码问题.
这个问题的原因在于wprintf的格式化参数%s.应该呢,在标准C中,格式化参数%s表示普通字符串(char*),%ls表示宽字符串(wchar_t*)(貌似%S也可以表示宽字符串,但在C标准中已被抛弃了,回避之)
所以Linux下应该用wprintf(L"%ls/n",wstr);才可以正常输出.
而wprintf(L"%s\n", wstr)的%s是将wstr当作多字节字符串,通过调用mbrtowc()函数转换成Unicode编码,再交给wprintf输出. 可wstr本来就是Unicode编码字符串,被当成MBCS编码再转换成Unicode,这多的一步处理使字符串的内容全乱了.
文章中也说明了Linux下输出宽字符串,未必非要是wprintf,用printf("%ls\n", wstr)也可以. %ls将wstr当作宽字符,通过调用wcrtomb()函数转换成多字节编码(这里是UTF-8),然后交给printf输出.所以最后依然显示正确.
而Windows下用%s和%ls都可以正确输出.其区别我猜想应该是Windows下C运行库(CRT)与Linux下的The GUN C Library(glibc)实现不同所致.
CRT太特立独行,Linux下glibc的实现我觉得应该更符合C标准吧.
=============================================================再见分割线
最后附加:
之前提到过Windows下MinGW编译的源文件有中文宽字符时,必须是UTF-8保存的(没有中文的话就随意啦).否则若源码中有中文的宽字符变量时编译会出错: "converting to execution character set: Illegal byte sequence".(原因之前也说过了,是因为要让编译器知道是从什么编码转到Unicode的)
当然如果你执意要保存ANSI编码,那么可以指定gcc的输入文件的编码参数-finput-charset. (如-finput-charset=GBK)
同样也能指定gcc的输出编码参数-fexec-charset. (如-fexec-charset=GBK 这样之前那个"中文"显示""涓枃"就也能得到正常输出啦)
参考:
为什么printf可以打印中文,而wprintf却一定要setlocale才能正确打印?
解决使用VC运行时库函数wprintf和wcount显示中文不正确的问题
Why printf() does not care of my locale settings ?
简析MinGW编译器以及vc使用wxWidgets的汉字问题
本文转载自:http://www.cnblogs.com/dejavu/archive/2012/09/16/2687586.html
https://my.oschina.net/mickelfeng/blog/144484

 浙公网安备 33010602011771号
浙公网安备 33010602011771号