通过VGG模型迁移学习,利用fine-tune的VGG模型实现“猫狗大战”测试
使用VGG实现猫狗识别
关键代码
- 优化模型:VGG16的 nn.Linear 层由1000类替换为2类,同时为保证只会更新最后一层的参数,需要在训练中冻结前面层的参数。如下图所示

- 训练函数
第一步:创建损失函数和优化器
损失函数 NLLLoss() 的 输入 是一个对数概率向量和一个目标标签.
它不会为我们计算对数概率,适合最后一层是log_softmax()的网络.
'''
criterion = nn.NLLLoss()
# 学习率
lr = 0.001
# 随机梯度下降
optimizer_vgg = torch.optim.SGD(model_vgg_new.classifier[6].parameters(),lr = lr)
'''
第二步:训练模型
'''
def train_model(model,dataloader,size,epochs=1,optimizer=None):
model.train()
for epoch in range(epochs):
running_loss = 0.0
running_corrects = 0
count = 0
for inputs,classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs,classes)
optimizer = optimizer
optimizer.zero_grad()
loss.backward()
optimizer.step()
_,preds = torch.max(outputs.data,1)
# statistics
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
count += len(inputs)
print('Training: No. ', count, ' process ... total: ', size)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print('Loss: {:.4f} Acc: {:.4f}'.format(
epoch_loss, epoch_acc))
# 模型训练
train_model(model_vgg_new,loader_train,size=dset_sizes['train'], epochs=1,
optimizer=optimizer_vgg)
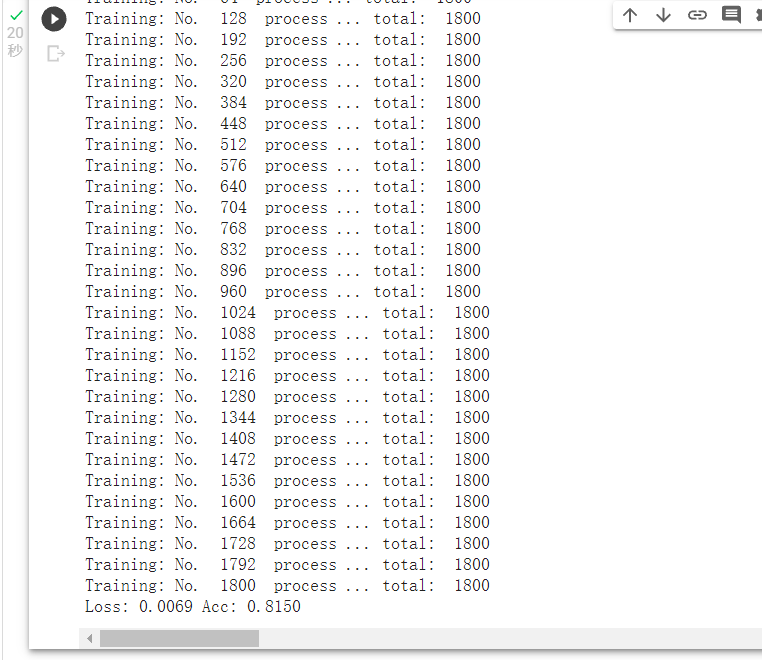
# 第三步:测试模型
def test_model(model,dataloader,size):
model.eval()
predictions = np.zeros(size)
all_classes = np.zeros(size)
all_proba = np.zeros((size,2))
i = 0
running_loss = 0.0
running_corrects = 0
for inputs,classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs,classes)
_,preds = torch.max(outputs.data,1)
# statistics
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
predictions[i:i+len(classes)] = preds.to('cpu').numpy()
all_classes[i:i+len(classes)] = classes.to('cpu').numpy()
all_proba[i:i+len(classes),:] = outputs.data.to('cpu').numpy()
i += len(classes)
print('Testing: No. ', i, ' process ... total: ', size)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print('Loss: {:.4f} Acc: {:.4f}'.format(
epoch_loss, epoch_acc))
return predictions, all_proba, all_classes
# 模型测试
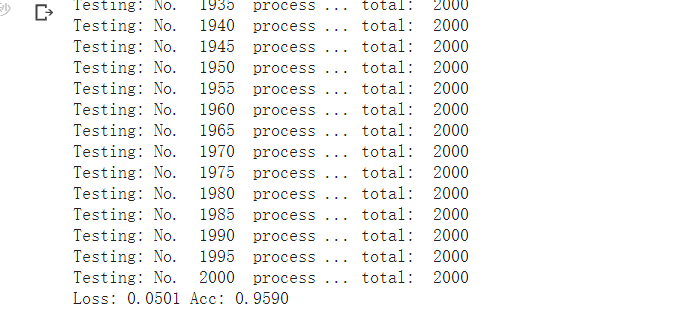
predictions, all_proba, all_classes = test_model(model_vgg_new,loader_valid,size=dset_sizes['val'])
- 模型测试结果,可以看到正确率为95.90%
softmax()
逻辑回归算法预测患者是否有恶性肿瘤的二分类问题中,需要满足p(A|x) + p(~A|x) = 1,A是指是患有恶心肿瘤的概率。之后,需要将结果输出,简单来说各个输出节点的输出值范围映射到[0, 1],并且约束各个输出节点的输出值的和为1。当然可以将输出为两个节点的二分类推广成拥有n个输出节点的n分类问题。
将各个输出节点的输出值范围映射到[0, 1],并且约束各个输出节点的输出值的和为1的函数呢
图片数据处理
梯度归零(optimizer.zero_grad()),然后反向传播计算得到每个参数的梯度值(loss.backward()),最后通过梯度下降执行一步参数更新(optimizer.step())
可以对每一步数据进行归零,反向传播,在更新下一步参数
利用fine-tune的VGG模型实现“猫狗大战”测试
实现过程
经过十次训练,我得到了一个Acc度最高的训练模型, 0.9946,将这个模型作为测试模型使用
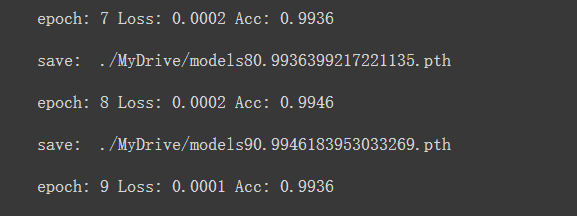
-
写入result.csv 文件,代码如下
-
with open("./data/result.csv", 'a+') as f:
for i in range(2000):
f.write("{},{}\n".format(i, total_preds[i])) -
上传结果

总结:
代码调试后正确率达到98.1%,进一步修改batch_size参数后正确率反而降低了,同时模型的准确度也无法达到0.9946的程度。

通过此次学习可以得知基于VGG16的迁移学习实现逻辑回归是十分有效的,并且可以通过适当调整batch_size和学习率等参数来更改模型的准确率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号