
主程序:
 主程序
主程序

# -*- coding: cp936 -*-
result=[]
delimiter=' '
delimiter2='|'
from Bigramwordsegemtation2 import BygramViterbi
work=BygramViterbi.Viterbi()
import re
p1=re.compile('\d+')
f=file(r'c:\python26\Bigramwordsegemtation2\corpus-test\corpus-test-digit.utf-8.txt')
#sentence=['18038','374','30876','20854','12188','7055','4486','58016','27036','42155','37638','36507','49792','47264','10658','12188','60327']
#sentence=['38622','40887','49847','49847','40119','60327','57002','5047','38814','38583','57002','40887','31388','38406']
#sentence=['45751','61096','45751','45472','42137','63927','12146','40649','25363','10658','42167','45735','49301','25237','36501']
#result=work.Segment(sentence)
#print result
for line in f:
sentence=p1.findall(line)
if len(sentence)>0:
result_single=work.Segment(sentence)
result=result+result_single
print result_single
#s=raw_input('enter this')
else:
continue
s=[]
for m in result:
m=' '+m+' '
s.append(m)
finalresult=delimiter2.join(s)
finalresult=finalresult+'|'#得到了和老师给的数据一致的格式类型
fresult=file(r'c:\python26\Bigramwordsegemtation2\corpus-test\result.txt','w')
fresult.write(finalresult)
fresult.close()
print'final finish congratulations!'
result=[]
delimiter=' '
delimiter2='|'
from Bigramwordsegemtation2 import BygramViterbi
work=BygramViterbi.Viterbi()
import re
p1=re.compile('\d+')
f=file(r'c:\python26\Bigramwordsegemtation2\corpus-test\corpus-test-digit.utf-8.txt')
#sentence=['18038','374','30876','20854','12188','7055','4486','58016','27036','42155','37638','36507','49792','47264','10658','12188','60327']
#sentence=['38622','40887','49847','49847','40119','60327','57002','5047','38814','38583','57002','40887','31388','38406']
#sentence=['45751','61096','45751','45472','42137','63927','12146','40649','25363','10658','42167','45735','49301','25237','36501']
#result=work.Segment(sentence)
#print result
for line in f:
sentence=p1.findall(line)
if len(sentence)>0:
result_single=work.Segment(sentence)
result=result+result_single
print result_single
#s=raw_input('enter this')
else:
continue
s=[]
for m in result:
m=' '+m+' '
s.append(m)
finalresult=delimiter2.join(s)
finalresult=finalresult+'|'#得到了和老师给的数据一致的格式类型
fresult=file(r'c:\python26\Bigramwordsegemtation2\corpus-test\result.txt','w')
fresult.write(finalresult)
fresult.close()
print'final finish congratulations!'
注:数据以及计算准确率的程序来源于刘群老师。只供学习交流使用。
一些资源下载地址
我的分词程序(正向最大匹配,两种O概率平滑框架下的二元词图Viterbi分词方法)
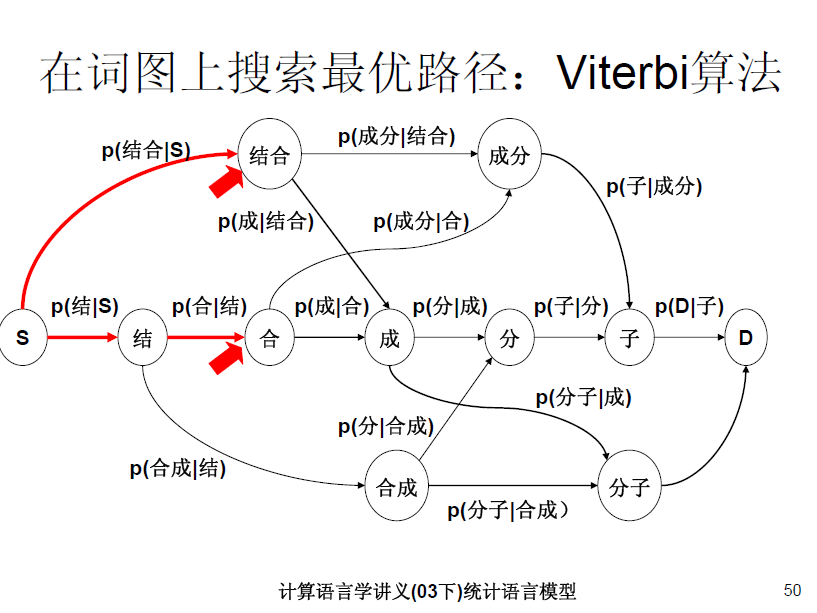
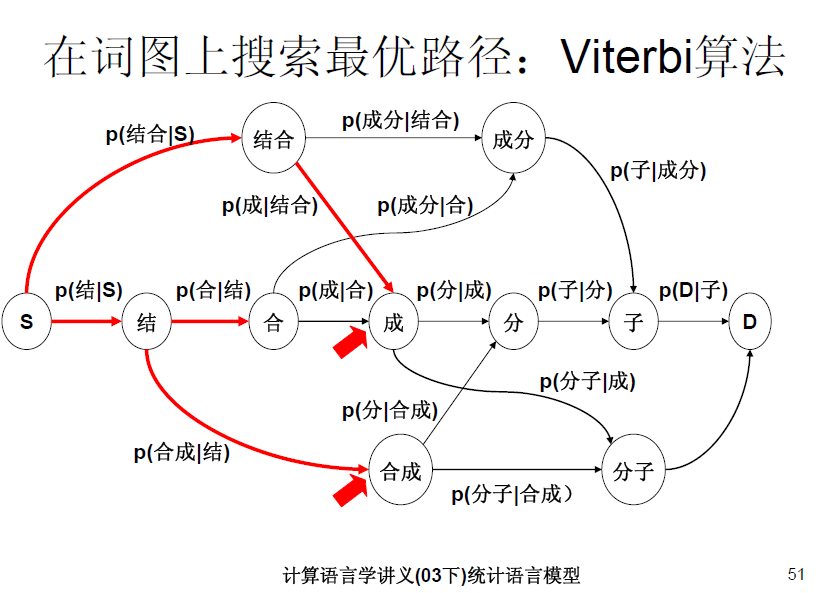
附几张关于二元词图以及Viterbi分词的PPT,做作业的时候,我就是从这几张图中悟出拓扑图的含义的。记得交完作业后,有同学和我交流说Viterbi算法没有什么难得,确实哈,就像图的宽度优先,深度优先等的遍历算法一样,没什么稀奇的。关键点是在于如何给图建立一个拓扑序。当时在课上很多同学都采用了二元词图viterbi算法分词。大家的不同之处也就是在于图的拓扑序的定义。在(一)中,我已经给出了我的拓扑序建立方式,相信还有很多方式,欢迎大家一起交流。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号