
作者:finallyly 出处:博客园(转载,请注明作者和出处)
硕士毕业论文即将开题,两周内就要交开题报告和开题PPT。而且身上还压了一个基于半规则数据库的作者实体识别问题,一个英汉词典自动对照校对的任务。这两个任务从本质上来讲,都涉及到了语义理解的问题,如果搞不好的话,就要人工纯手工识别了,这时这两项工作就变成了一个既费时,又费力,还不讨好的蛋疼工作了。好在工作中发现了一些规律,能够让后续工作者和我并行工作,而不是串行工作。 数据采集任务本来就比较繁琐,时而有噪声存在也是不可避免的,但是不做这个工作的人往往不能有词直观的感受,他们会苛刻的认为“知识库”就应该是perfect的,凡是有一点噪声和冗余的,都会认为是前期工作不到位。也是我以前的工作报告写的不够重点突出,也就促成了一些细腻的摩擦和不愉快。从我个人的角度来说,项目所有的采集工作(全自动化的也好,半自动化的也罢),都有我的心血融入其中。虽说助研,理应做些事情,但是并不是直接聘请的工作人员,也有学习任务压在身上的。我个人认为,工作上的任务我会在学习之余极力做好,做完美,但这是最大的极限。反之,如果牺牲学习,研究的时间,舍本逐末,一味在一些细节上苛求精益求精,那是一种资源的浪费。硕士毕业之后,找了一个本科生的工作,拿了份本科生的薪水,驳的不仅仅是自己的面子,更是给老师脸上抹黑!(殊知:虎父本应无犬子,强将手下无弱兵。)
当一个人欠债欠的过于离谱,而或是心理承受能力过于单薄的话,他往往会采取破罐子破摔的策略。现在的我,似乎有些“异曲同工之妙”。 由于压力过大,导致我精神上些点涣散和迷离,集中不了注意力。特整理一下思绪,吸取一下经验教训。
毕设开题工作之所以难办,直接原因是我对题目的理解和把握不够到位,相关方面的调研不够充分。归根揭底是我在老师给我布置这项任务的时候,自己定位没有定位准。在此前所做的工作都是“督导式”的,即别人指派给你工程任务,自己用程序实现了相关功能,就算是做完了。而这个任务确实探索性的。此前有的时候有些小埋怨,觉得自己做的东西太偏工程了,可是当老师真真正正地把一个研究任务指派给我的时候,我却茫然不知。 从一开误以为老师要让我把汉语词典的文本敲到电脑里,到后来从的词典里的找释义元语言,走了很多南辕北辙的冤枉路(我的理解能力也太差了,汗了 )。直到最近做密集型文献调研,我才知道我导师的真正用意是什么。我现在的研究题目是《汉语的词典义理解》,所属NLP领域的语义计算以及语料库语言学之间的交叉领域。旨在建立一个词汇知识库,用以辅助计算机理解词义,能够进行简单的词义排岐,进而具有理解语义的能力。词汇知识库的建立,都会有哲学溯源和体系。我们导师从事人工智能方面的研究二十余年,参与过很多具体的军用以及民用专家系统的设计与开发,也拥有大量经验。这一次他是想把他的设计专家系统的哲学和思想理念在语义理解领域做些尝试。而我所做的工作就是首先要了解他的那天理论框架,然后了解语料素材,进而将语料素材按照他的理论框架形式化。
)。直到最近做密集型文献调研,我才知道我导师的真正用意是什么。我现在的研究题目是《汉语的词典义理解》,所属NLP领域的语义计算以及语料库语言学之间的交叉领域。旨在建立一个词汇知识库,用以辅助计算机理解词义,能够进行简单的词义排岐,进而具有理解语义的能力。词汇知识库的建立,都会有哲学溯源和体系。我们导师从事人工智能方面的研究二十余年,参与过很多具体的军用以及民用专家系统的设计与开发,也拥有大量经验。这一次他是想把他的设计专家系统的哲学和思想理念在语义理解领域做些尝试。而我所做的工作就是首先要了解他的那天理论框架,然后了解语料素材,进而将语料素材按照他的理论框架形式化。
但这其中就有不少问题。 从我自身来讲,上课的时候把学习精力的侧重点放在了具有深刻统计学印记的计算智能方法学上面。之前做过的一些分词,文本分类的工作也是基于统计学方法的。 对于符号智能体系框架下的一些基本理论,如形式语言、数理逻辑、编译原理等等,虽然也有学习,但是学得不深入,更重要的是学不懂。总之,就是我的领悟能力有待提高。从学习环境来讲,我所在的部门, 隶属于工程中心。工程项目指标和任务都比较重,很多师兄师姐包括我导师都是身兼数值,要写程序,要跑项目,同时还有指导学生。所以,不可能面面俱到的去提点某个学生,只能靠自己根据一些资料线索,按图索骥地去摸索。但是知识库建设有自己的特性。这一点董振东老先生在 《knowledge discription:what,how,who》中也有提到过:人工智能研究者或知识工程师的任务是找出一种建立知识系统的可行的方法,知识库的填充是由后续工作者(其他领域的专家,或普通人)完成的。 而我的师兄,师姐们在做毕设论文的时候和我一样都是扮演着知识工程师的角色。换句话说,他们所做的实际系统只是一种框架或模式,我根本不可能从对某种框架或模式的详细研究中获得启迪。这和我公布的那个文本分类框架是完全不同的,我的分类框架是具有可操作性和启迪性的,可以辅助初学者更快结识文本分类这位朋友。再者说,知识库不仅要有知识,还要有推理规则。对于规则的指定也是仁者见仁,智者见智的问题。综上,我不可能通过观察揣摩某一个现成的系统而入门。
间接入门的方式就是要通过看很多书,然后期待”摄入的知识发生了连锁反应”从而理解了以前未理解的问题。 我给自己开了个长药方:理解语言和语义,要看 吴蔚天的《汉语计算语义学》;词汇学要看 苏新春的《汉语释义元语言研究》、葛本仪的《现代汉语词汇学》。理解符号逻辑要读《形式语言》,《数理逻辑》,加深实践理解,要看《编译原理》。知识表示方面要看《Knowledge Representatin, logical philosophical, and Computational Foundations》。
上述的这些都是浅层背景知识,没有这些背景,那么不可能从根本意义上深入理解课题,但是如果一直纠结于这些浅尝知识,那么直接的研究工作和工程工作就没法开展。
和课题直接相关的内容要看宗成庆,刘群课程中和语义计算相关的片子,董老《知网》的相关设计方案,以及基于知网的语义计算的一些相关文章。Fillmore的framenet也是可参考的对象。另外,Fillmore的 case grammer(格语法),以及基于格语法的framenet,Quillian的semantic network, schank的concept dependence 可以说是国内相关领域工作者的灵感源泉,所以这些大牛们的论文要仔细观摩,反复咀嚼。
以上两段给出的背景工作是长久的工作和学习计划。对于这个开题工作,最好的办法就是建立“在理解的理解”的基础之上。摘录和转述国内相关著作对某些有影响力的理论的总结和说明,形成自己的东西。这样一来可以加深理解,而来也会使自己在看文献的时候对文献作者驾驭语言的方式有所侧重,从而对自己真正动笔写论文,有所积累和有所启迪。
附上一位同学总结的,高效文档写作方法
第一步、构思
明确写作目的,设计文章形式和大体结构。
第二步、写提纲
着眼于全文结构,提纲写的尽量详细;一定要做到提纲挈领,不必纠结于到底如何来写。这部分工作是最重要的,也应该是最花心思的。
第三步、填充式写作
根据提纲,进行具体内容的写作;此时关注的是表述整体上的连贯性、合理性,不要纠结于具体措辞以及文档格式以致经常打断思路。这一步的目的就是尽可能快速地填充具体内容,保持思维的连续性,注重表述的整体连贯性。
做好这一步是高效文档写作的关键。很多时候文档写作的效率低就在于过度关注文字细节,思维总是被细节问题打断,不能畅快地发挥。
第四步、雕琢式写作
对文章的措辞不当、语法错误、表达不清楚等问题进行修正。然后调整文章的文字和段落格式。
第五步、复审
重新阅读文章,进一步修改。
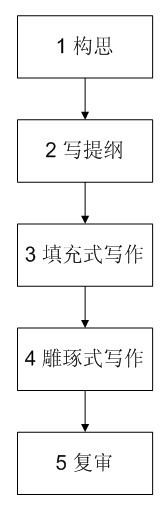
个人觉得,第二步:写提纲最重要。提纲上的具体而微以及详略得当,对于布局谋篇,以及整个写作过程中的效率都有极大的影响。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号