

作者:finallyliuyu (资料使用,博文引用请您表面出处)
本专题是有关借助于Lucene.Net工具如何对英文文章进行分词,词性标注,词根还原的。如果是借助于Lucene.net框架对中文进行分词,词性标注,那么原理上更简单。我在《也谈贝叶斯分类C#版》中给出了如何在Lucene中嵌入河北理工大学吕震宇老师(根据张华平老师的ICTCLAS分词开源版本改写成)的sharpICT.需要指出但是此段代码并非我原创,好像是参考的 博客园中的“智慧掩盖真相”MS,记不清了,抱歉。但是吕老师的sharpICT中有一个bug.好像是数组的原因造成的。但是具体怎么回事,忘了。上学期做《现代信息检索》课程的大作业,我对用我的新闻正文提取算法提取下来的三万篇新闻用sharpICT做分词,分着分着那个问题就出来了,而且很频繁。好像是数组越界的问题吧。
扯远了,总之是希望这篇针对于英文文章搭起来的平台的方法,能对如何利用Lucence.Net处理汉语文章有所启发。
资源下载链接
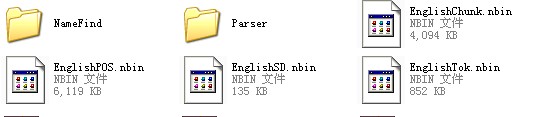
注意:将上面的Part1,Part2,Part3解压构成Models 文件夹。Models文件夹放在工程目录的bin/debug or bin/release目录下。程序就可以正常使用。
Models文件夹下面应该有的东东:
写一点应用关于 Lucene.Net,snowball的重新组装(二)
写一点应用关于 Lucene.Net,snowball的重新组装(三)
写一点应用关于 Lucene.Net,snowball的重新组装(四)
上学期参与到了中国科学院研究生院朱庭劭教授的《网络挖掘》课程的一个开源项目中。项目的名称叫做“GLOSS”。大概就是一个类似知网的东东。我们小组做的子课题是“相似论文推荐”。(注:所有的论文都是英文论文)相似论文推荐可以看做是“聚类”。为了特征词选择和研究算法的便利,要把词汇放在Lucene自己封装的Indexer之外。为此设计了如下格式的数据库。

下面给出部分数据库内容截图

从上面可以看出我们的需求是利用Lucene.Net平台,获得词本身,词的词性(POS part of speech),词根(steming),以及该词在文章中出现的开始位置,结尾位置。(方便计算词的度量簇,度量簇概念见 计算所王斌老师《现代信息检索PPT》的第四章相关反馈及查询扩展)

