

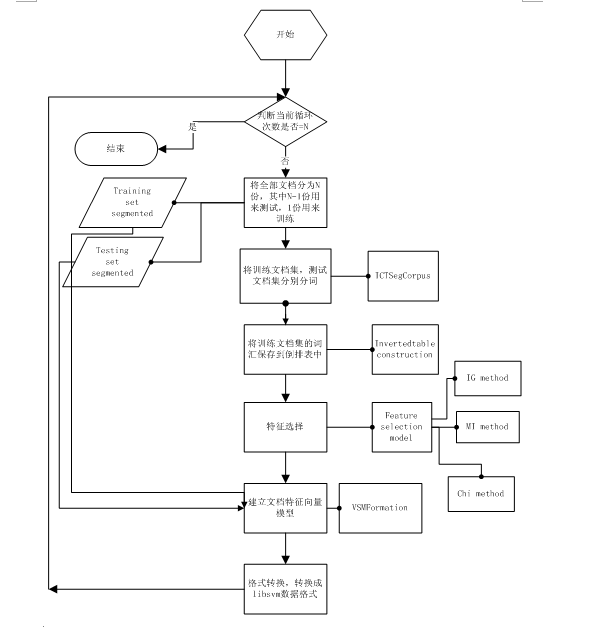
设计如上图所示的文本分类预处理模块。考虑到要研究特征维数的不同选择对分类准确率的影响。也就是在同一个文档集合上面,同一种特征选择方法上面,要多次建立VSM模型。如特征维数为1000的情况下的VSM模型,特征维数为2000情况下的VSM模型。在这种情况下,只需要多次调用VSMFormation模块就行了,因为文档集没有变,所有词袋子模型没有变,因为特征词选择方面没有变,所以词的优先序没有变。这是一个非常简单的道理,可是我最初在设计程序的时候,竟然每个维度都要重新分词,重新建立词袋子模型,重新进行特征值计算。。。好傻瓜。
有的时候"磨刀不误砍柴工"如果我在一开始设计实验编写程序的时候,不是仅仅画了如上的一个框架图,而且把各个模块之间怎样衔接,函数如何命名,如何传递都设计好了,就不会出现对程序改了又改的情况了。有道是“磨刀不误砍柴工”,“慢工出细活”。写程序做实验,不能总持有一种投机的态度:就要能编译通过了就好,今天编译通过了,明天编译不通过,那么明天再改。。应该胸有成竹才对。

