
正则相关
简单理解:就是以浏览器可以识别的一种方式去分析对应数据是否符合要求

(1)字符查找,search类似于indexOf,没有则返回-1

(2)字符串截取substring

(3)返回字符串某一位charAt

(4)字符串截取切分split

【缘由/优势】
需求:找出字符串中所有数字
(1)普通原始字符串操作

(2)正则

【定义】


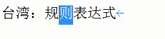
(1)邮箱规则

(2)正则两种写法
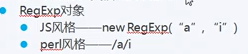
perl为一门比较老版的编程语言,现在应用不太广泛,该语言首次提出正则概念
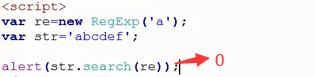
(3)search字符串搜索
RegExp为Reg Expression正则表达式简称

(4)search参数---字符串忽略大小写


(5)match匹配
需求:找到第一个出现的数字???

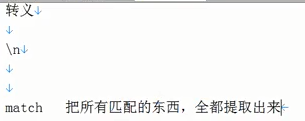
这里需要用到转义\

之前的search只能找到相应字符位置,并不能提取出来,这里便需要用到match
案例:

问题:此时只会获取到3,第一个数字... ...
(6)match参数---g全局匹配
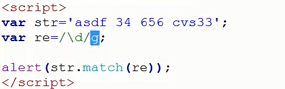
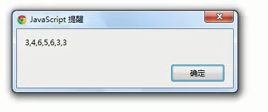
问题:输出结果为分隔切片后的数据... ...
分析:因为/\d/只要了一个数字... ...,验证如下
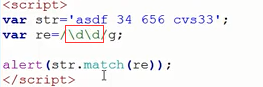

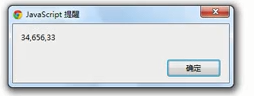
如果3位,则只会输出656
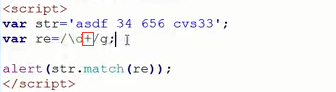
(7)match参数---量词

(8)replace替换

需求:将所有a变为0


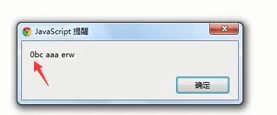
问题:这里只把第一个变为0... ...
接下来结合正则

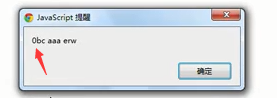
会发现还是无效... ...此时正则里参数--全局匹配g加入即可

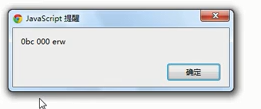
(9)replace替换案例---敏感词过滤
1、功能分析

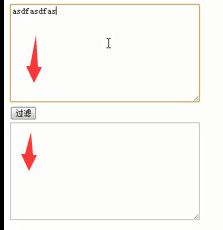
点击过滤后在另一个输入域里显示过滤好的
2、编写脚本
① 获取

②点击绑定

③正则
接下来考虑re正则即可
编写敏感词

测试

④问题。此时发现只替换了第一个,原因:缺少全局匹配参数g


(10)基本组成部分---元字符(开发通常称之为方括号)


1、任意字符

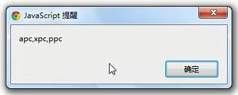
2、范围字符


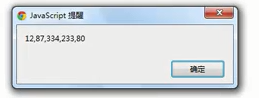
3、排除^

除了字母都可以,即排除字母
4、混合使用
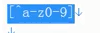
排除英文字母和数字
(11)案例:模拟小说采集器,过滤HTML标签

1、布局

需求:原始HTML转换为纯文本
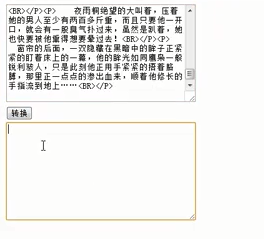
去除HTML标签
2、编写脚本
① 获取及大概思路

转义字符:.代表任意
②分析正则re

测试:
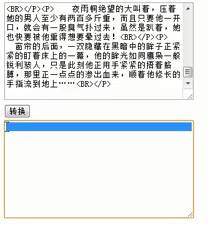
问题:转化成了空行... ...
分析:正则天生具备一个特性“贪婪”

正则将整个过滤了... ...
分析:不能出现任意字符,不能包含尖括号

新规则:

验证如下:

(12)转义字符

space空格
三个孪生兄弟
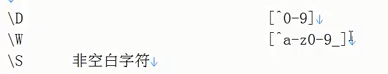
(13)量词

1、{n}电话

2、{n,m}QQ号

3、{n,}

4、?


区号可有可无
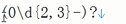
完整如下

5、*

(14)量词*注意
少用*

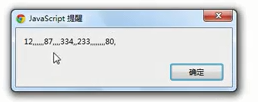
这里*理解为0次或更多次,那么字母或者空格地方可理解为0个数字
(15)量词练习


1、静态布局

2、脚本

3、正则翻译

4、测试

5、问题
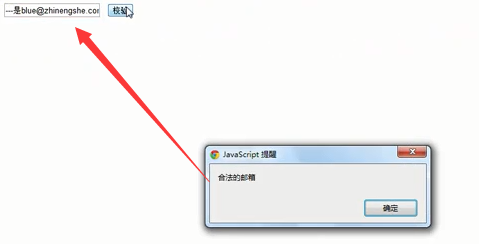
合法邮箱前加些其他数据,发现任然合法
6、分析
test特性:部分符合要求,则返回true

行首和行位优化限制

.
