ELK(ElasticSearch, Logstash, Kibana)搭建实时日志分析平台
ELK平台介绍
在搜索ELK资料的时候,发现这篇文章比较好,于是摘抄一小段:
以下内容来自:http://baidu.blog.51cto.com/71938/1676798
日志主要包括系统日志、应用程序日志和安全日志。系统运维和开发人员可以通过日志了解服务器软硬件信息、检查配置过程中的错误及错误发生的原因。经常分析日志可以了解服务器的负荷,性能安全性,从而及时采取措施纠正错误。
通常,日志被分散的储存不同的设备上。如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志。这样是不是感觉很繁琐和效率低下。当务之急我们使用集中化的日志管理,例如:开源的syslog,将所有服务器上的日志收集汇总。
集中化管理日志后,日志的统计和检索又成为一件比较麻烦的事情,一般我们使用grep、awk和wc等Linux命令能实现检索和统计,但是对于要求更高的查询、排序和统计等要求和庞大的机器数量依然使用这样的方法难免有点力不从心。
开源实时日志分析ELK平台能够完美的解决我们上述的问题,ELK由ElasticSearch、Logstash和Kiabana三个开源工具组成。官方网站:https://www.elastic.co/products
-
Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
-
Logstash是一个完全开源的工具,他可以对你的日志进行收集、过滤,并将其存储供以后使用(如,搜索)。
-
Kibana 也是一个开源和免费的工具,它Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。
----------------------------摘抄内容结束-------------------------------
画了一个ELK工作的原理图:
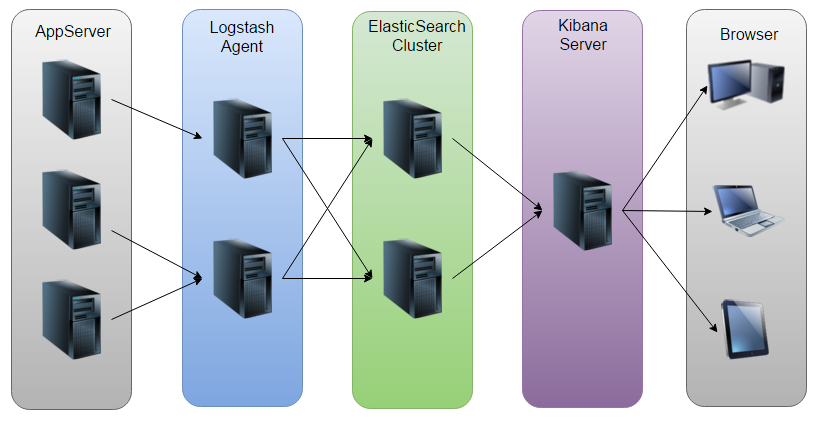
如图:Logstash收集AppServer产生的Log,并存放到ElasticSearch集群中,而Kibana则从ES集群中查询数据生成图表,再返回给Browser。
ELK平台搭建
系统环境
System: Centos release 6.7 (Final)
ElasticSearch: 2.1.0
Logstash: 2.1.1
Kibana: 4.3.0
Java: openjdk version "1.8.0_65"
注:由于Logstash的运行依赖于Java环境, 而Logstash 1.5以上版本不低于java 1.7,因此推荐使用最新版本的Java。因为我们只需要Java的运行环境,所以可以只安装JRE,不过这里我依然使用JDK,请自行搜索安装。
ELK下载:https://www.elastic.co/downloads/
ElasticSearch
配置ElasticSearch:
tar -zxvf elasticsearch-2.1.0.tar.gz
cd elasticsearch-2.1.0
安装Head插件(Optional):
./bin/plugin install mobz/elasticsearch-head
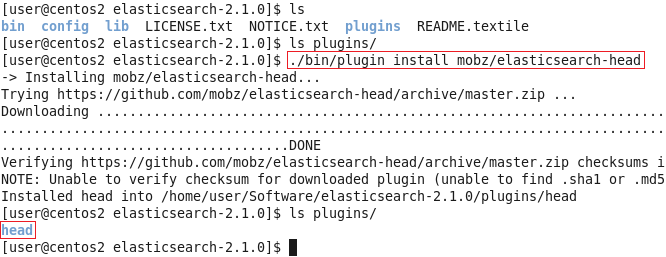
然后编辑ES的配置文件:
vi config/elasticsearch.yml
修改以下配置项:
cluster.name=es_cluster
node.name=node0
path.data=/tmp/elasticsearch/data
path.logs=/tmp/elasticsearch/logs
#当前hostname或IP,我这里是centos2
network.host=centos2
network.port=9200
其他的选项保持默认,然后启动ES:
./bin/elasticsearch
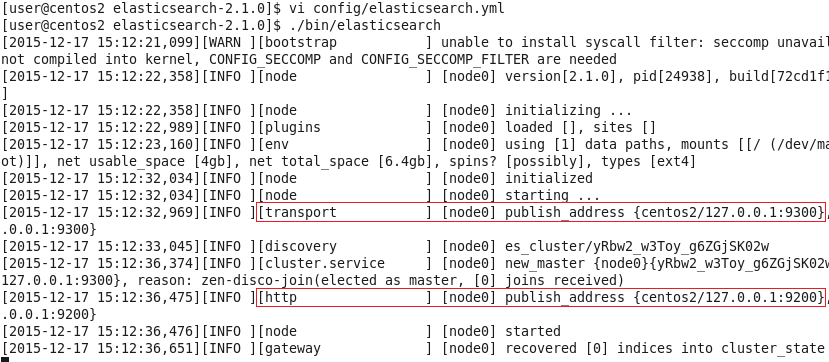
可以看到,它跟其他的节点的传输端口为9300,接受HTTP请求的端口为9200。
使用ctrl+C停止。当然,也可以使用后台进程的方式启动ES:
./bin/elasticsearch &
然后可以打开页面localhost:9200,将会看到以下内容:
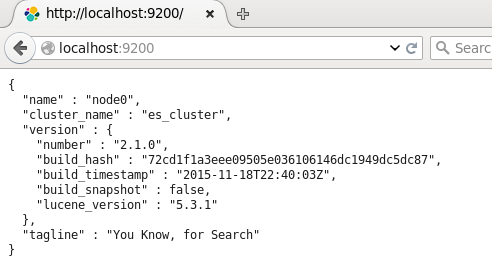
返回展示了配置的cluster_name和name,以及安装的ES的版本等信息。
刚刚安装的head插件,它是一个用浏览器跟ES集群交互的插件,可以查看集群状态、集群的doc内容、执行搜索和普通的Rest请求等。现在也可以使用它打开localhost:9200/_plugin/head页面来查看ES集群状态:

可以看到,现在,ES集群中没有index,也没有type,因此这两条是空的。
Logstash
Logstash的功能如下:
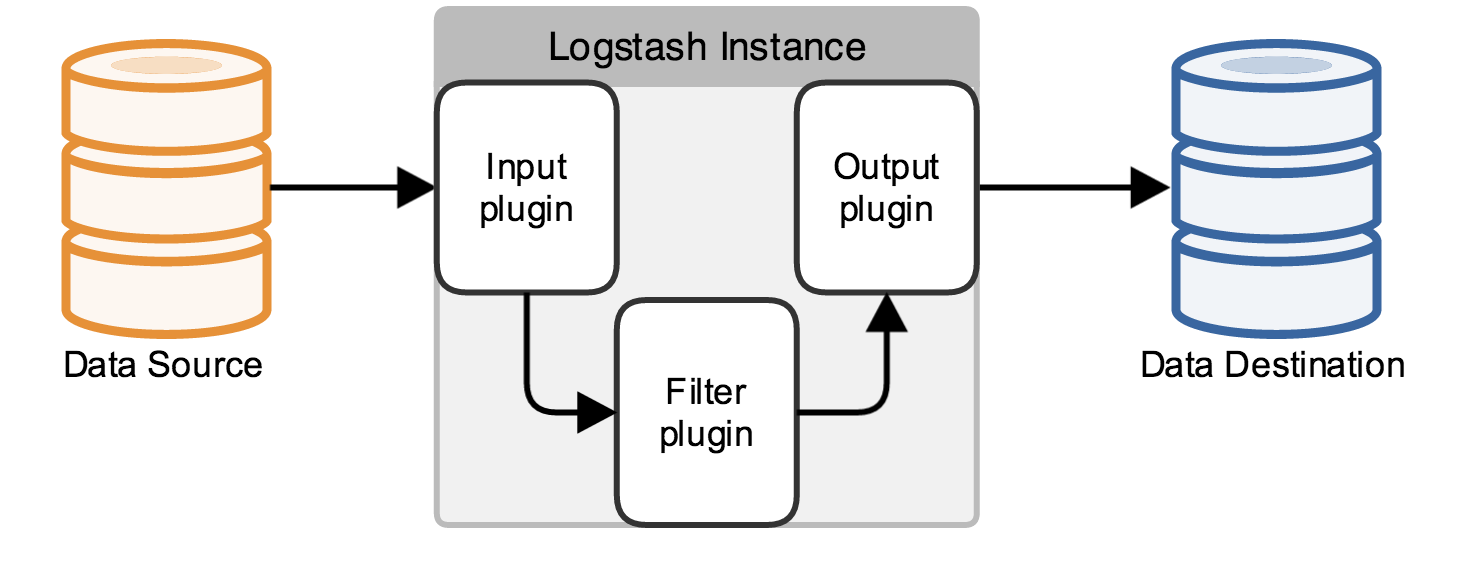
其实它就是一个收集器而已,我们需要为它指定Input和Output(当然Input和Output可以为多个)。由于我们需要把Java代码中Log4j的日志输出到ElasticSearch中,因此这里的Input就是Log4j,而Output就是ElasticSearch。
配置Logstash:
tar -zxvf logstash-2.1.1.tar.gz
cd logstash-2.1.1
编写配置文件(名字和位置可以随意,这里我放在config目录下,取名为log4j_to_es.conf):
mkdir config
vi config/log4j_to_es.conf
输入以下内容:
# For detail structure of this file
# Set: https://www.elastic.co/guide/en/logstash/current/configuration-file-structure.html
input {
# For detail config for log4j as input,
# See: https://www.elastic.co/guide/en/logstash/current/plugins-inputs-log4j.html
log4j {
mode => "server"
host => "centos2"
port => 4567
}
}
filter {
#Only matched data are send to output.
}
output {
# For detail config for elasticsearch as output,
# See: https://www.elastic.co/guide/en/logstash/current/plugins-outputs-elasticsearch.html
elasticsearch {
action => "index" #The operation on ES
hosts => "centos2:9200" #ElasticSearch host, can be array.
index => "applog" #The index to write data to.
}
}
logstash命令只有2个参数:
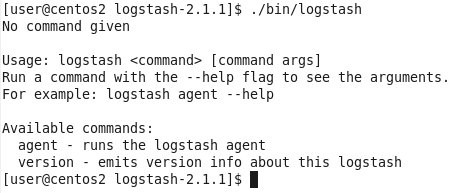
因此使用agent来启动它(使用-f指定配置文件):
./bin/logstash agent -f config/log4j_to_es.conf

到这里,我们已经可以使用Logstash来收集日志并保存到ES中了,下面来看看项目代码。
Java项目
照例先看项目结构图:
pom.xml,很简单,只用到了Log4j库:
<dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.17</version> </dependency>
log4j.properties,将Log4j的日志输出到SocketAppender,因为官网是这么说的:
log4j.rootLogger=INFO,console
# for package com.demo.elk, log would be sent to socket appender.
log4j.logger.com.demo.elk=DEBUG, socket
# appender socket
log4j.appender.socket=org.apache.log4j.net.SocketAppender
log4j.appender.socket.Port=4567
log4j.appender.socket.RemoteHost=centos2
log4j.appender.socket.layout=org.apache.log4j.PatternLayout
log4j.appender.socket.layout.ConversionPattern=%d [%-5p] [%l] %m%n
log4j.appender.socket.ReconnectionDelay=10000
# appender console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d [%-5p] [%l] %m%n
注意:这里的端口号需要跟Logstash监听的端口号一致,这里是4567。
Application.java,使用Log4j的LOGGER打印日志即可:
package com.demo.elk; import org.apache.log4j.Logger; public class Application { private static final Logger LOGGER = Logger.getLogger(Application.class); public static void main(String[] args) throws Exception { for (int i = 0; i < 10; i++) { LOGGER.error("Info log [" + i + "]."); Thread.sleep(500); } } }
用Head插件查看ES状态和内容
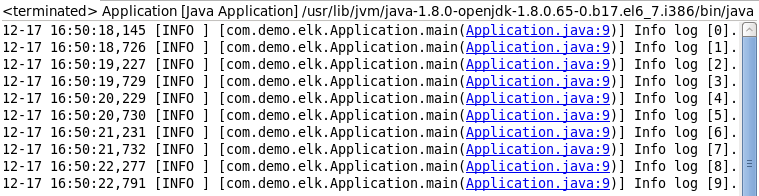
运行Application.java,先看看console的输出(当然,这个输出只是为了做验证,不输出到console也可以的):
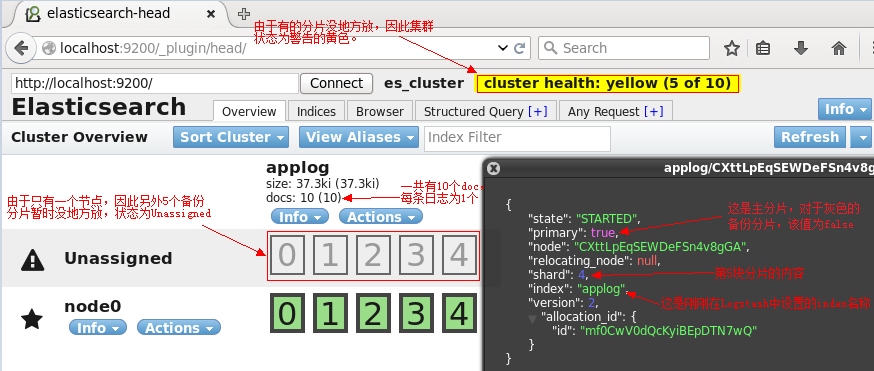
再来看看ES的head页面:
切换到Browser标签:
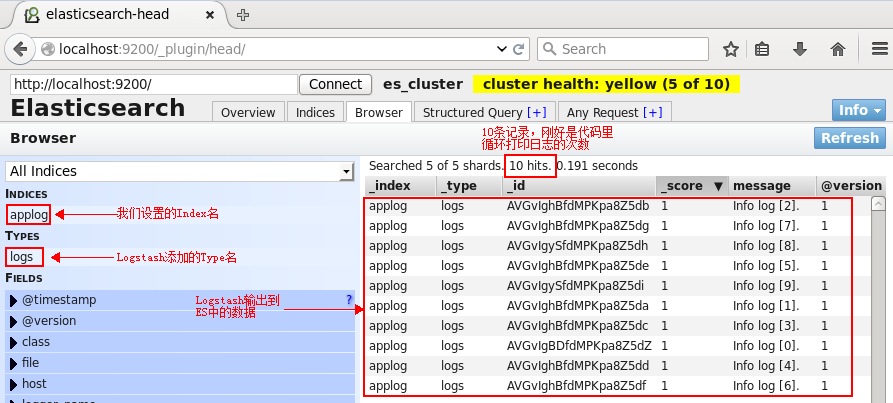
单击某一个文档(doc),则会展示该文档的所有信息:
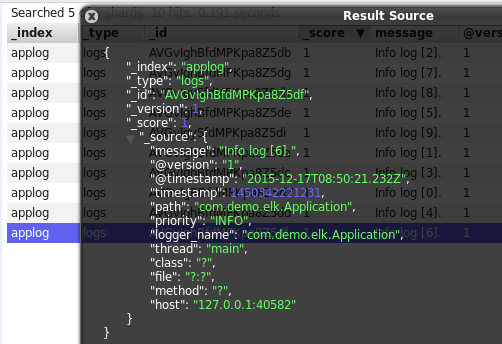
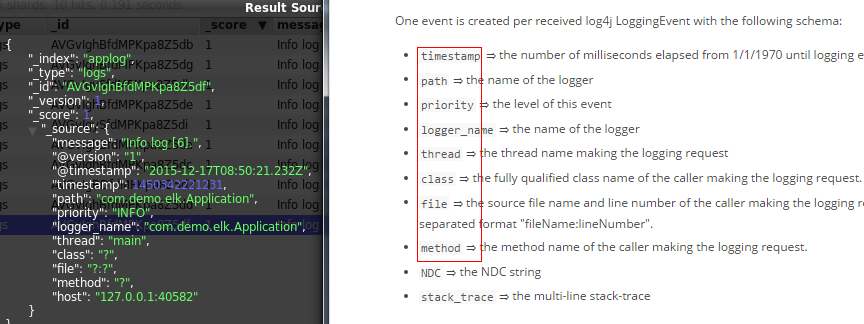
可以看到,除了基础的message字段是我们的日志内容,Logstash还为我们增加了许多字段。而在https://www.elastic.co/guide/en/logstash/current/plugins-inputs-log4j.html中也明确说明了这一点:
上面使用了ES的Head插件观察了ES集群的状态和数据,但这只是个简单的用于跟ES交互的页面而已,并不能生成报表或者图表什么的,接下来使用Kibana来执行搜索并生成图表。
Kibana
配置Kibana:
tar -zxvf kibana-4.3.0-linux-x86.tar.gz
cd kibana-4.3.0-linux-x86
vi config/kibana.yml
修改以下几项(由于是单机版的,因此host的值也可以使用localhost来代替,这里仅仅作为演示):
server.port: 5601
server.host: “centos2”
elasticsearch.url: http://centos2:9200
kibana.index: “.kibana”
启动kibana:
./bin/kibana
用浏览器打开该地址:
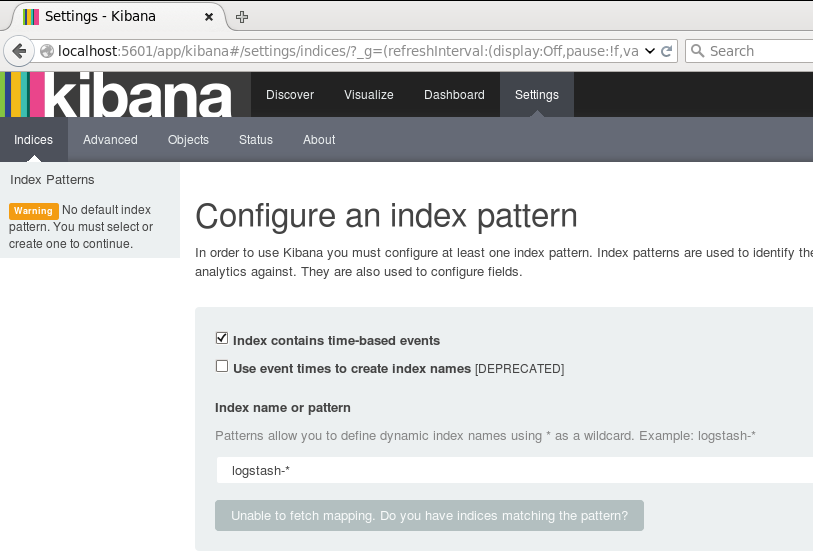
为了后续使用Kibana,需要配置至少一个Index名字或者Pattern,它用于在分析时确定ES中的Index。这里我输入之前配置的Index名字applog,Kibana会自动加载该Index下doc的field,并自动选择合适的field用于图标中的时间字段:
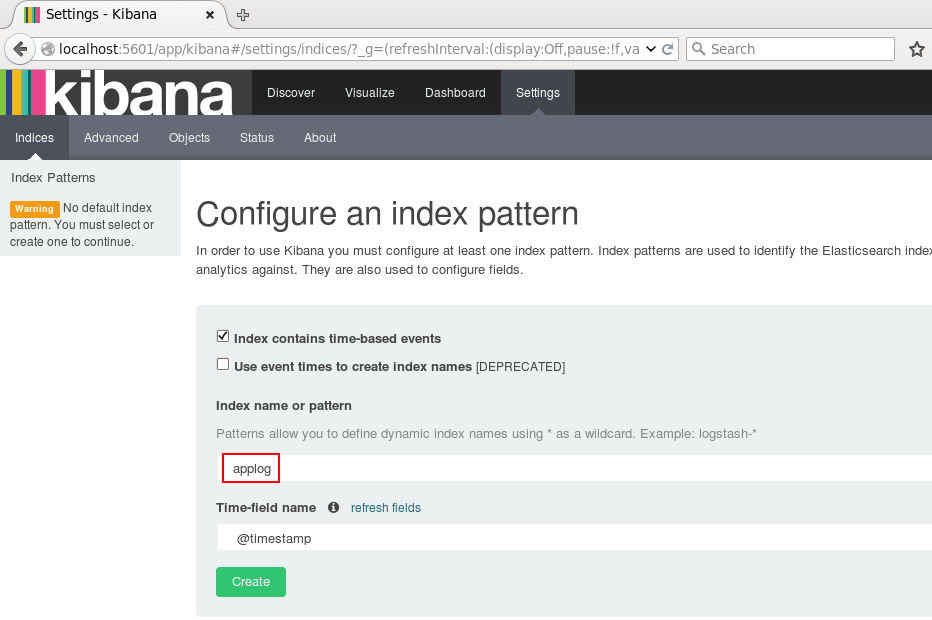
点击Create后,可以看到左侧增加了配置的Index名字:
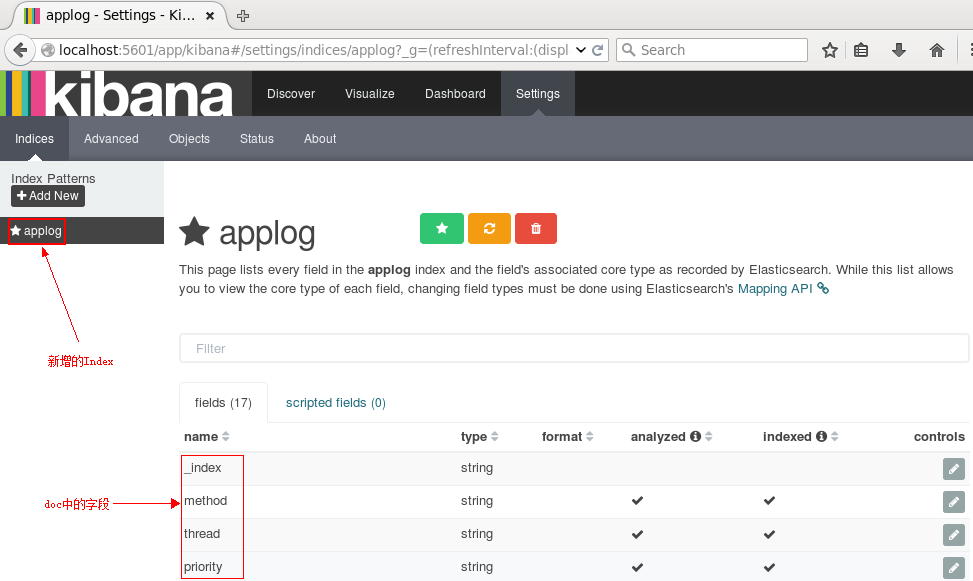
接下来切换到Discover标签上,注意右上角是查询的时间范围,如果没有查找到数据,那么你就可能需要调整这个时间范围了,这里我选择Today:

接下来就能看到ES中的数据了:
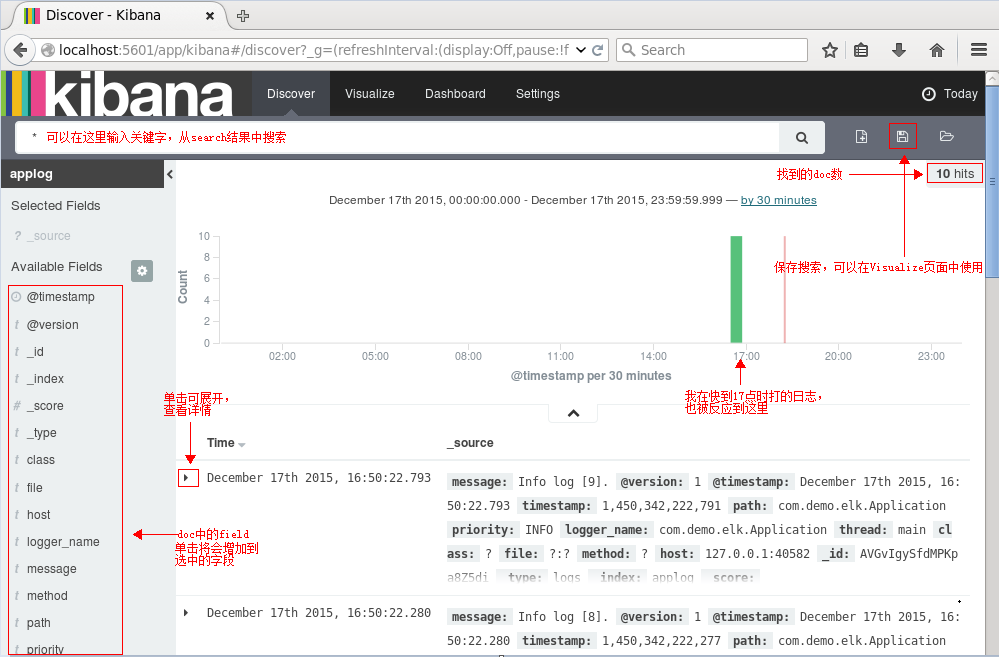
执行搜索看看呢:
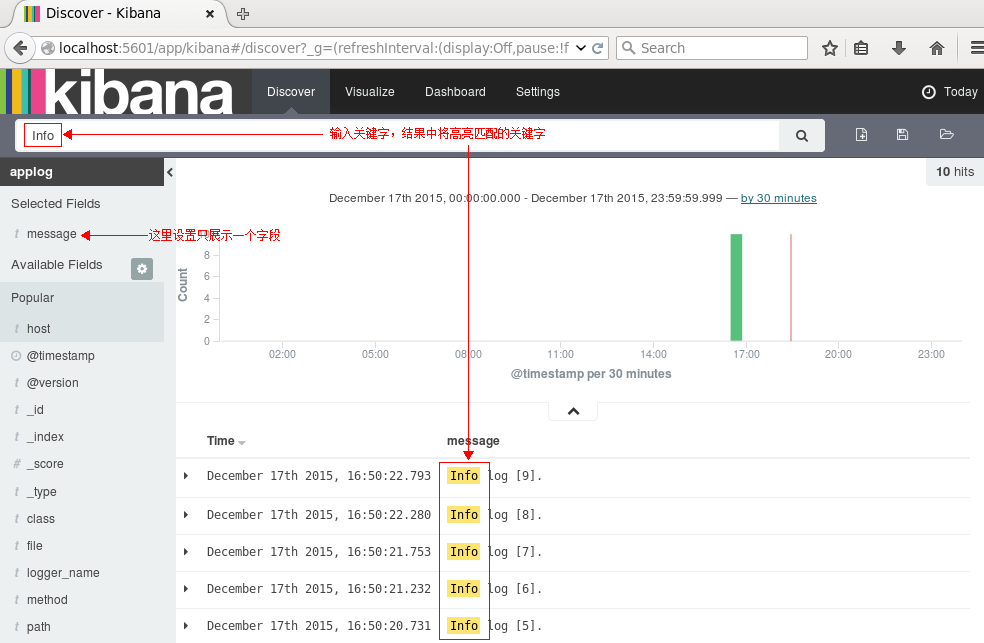
点击右边的保存按钮,保存该查询为search_all_logs。接下来去Visualize页面,点击新建一个柱状图(Vertical Bar Chart),然后选择刚刚保存的查询search_all_logs,之后,Kibana将生成类似于下图的柱状图(只有10条日志,而且是在同一时间段的,比较丑,但足可以说明问题了:) ):
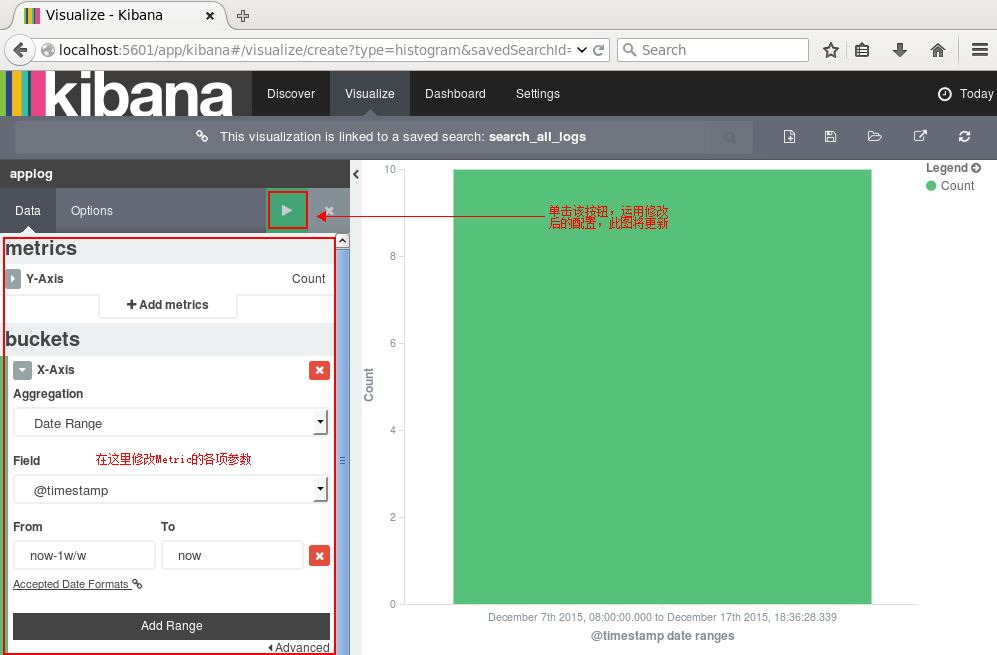
你可以在左边设置图形的各项参数,点击Apply Changes按钮,右边的图形将被更新。同理,其他类型的图形都可以实时更新。
点击右边的保存,保存此图,命名为search_all_logs_visual。接下来切换到Dashboard页面:
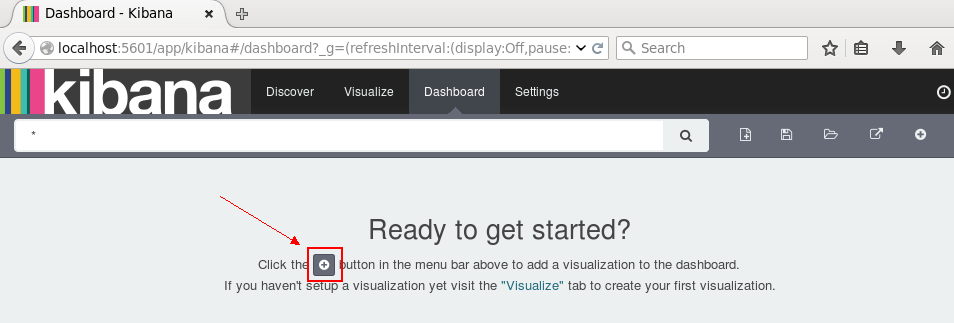
单击新建按钮,选择刚刚保存的search_all_logs_visual图形,面板上将展示该图:
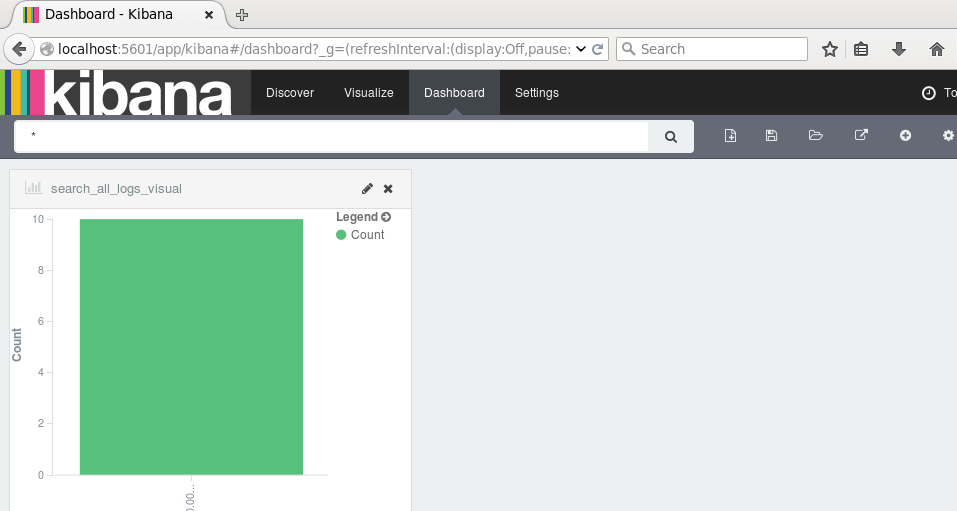
如果有较多数据,我们可以根据业务需求和关注点在Dashboard页面添加多个图表:柱形图,折线图,地图,饼图等等。当然,我们可以设置更新频率,让图表自动更新:
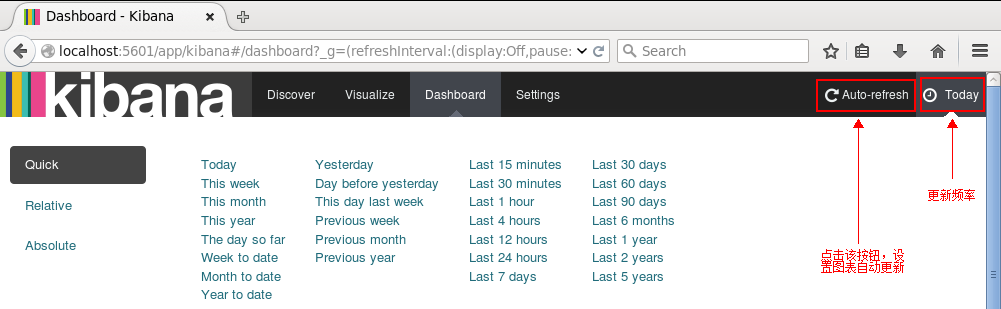
如果设置的时间间隔够短,就很趋近于实时分析了。
到这里,ELK平台部署和基本的测试已完成。
参考:
http://baidu.blog.51cto.com/71938/1676798
http://blog.csdn.net/cnweike/article/details/33736429
评论 (28)



引用来自“daqin32”的评论
请问你的applog是在哪里进行配置的?引用来自“nivance”的评论
同问
引用来自“jack1007”的评论
如果日志刷新比较快,比如一天10G的日志,上百台机器,这套系统分析的过来吗?特别是能分析实时的java报错日志吗?


引用来自“vbs_liuyoung”的评论
楼主,你好,我想问下,你有试过用java代码去查过es中的日志吗
按照你教程一步步做下来,ES的head页面docs显示0.不知道是不是疏漏某些配置!
# for package com.demo.elk, log would be sent to socket appender.
log4j.logger.com.demo.elk=DEBUG, socket
Application放到com.demo.elk包下就可以向logstash 发生日志数据了

引用来自“hong”的评论
是我自己的问题,没有看清楚log4j的配置:# for package com.demo.elk, log would be sent to socket appender.
log4j.logger.com.demo.elk=DEBUG, socket
Application放到com.demo.elk包下就可以向logstash 发生日志数据了



引用来自“jack1007”的评论
如果日志刷新比较快,比如一天10G的日志,上百台机器,这套系统分析的过来吗?特别是能分析实时的java报错日志吗?引用来自“摆渡者”的评论
额,很遗憾的告诉你,我只是在本地环境使用了几台服务器搭建了这个框架,我也没研究过如何使这套系统的性能达到最优,也没研究过这套系统的上限是多大。抱歉引用来自“jack1007”的评论
如果日志刷新比较快,比如一天10G的日志,上百台机器,这套系统分析的过来吗?特别是能分析实时的java报错日志吗?引用来自“摆渡者”的评论
额,很遗憾的告诉你,我只是在本地环境使用了几台服务器搭建了这个框架,我也没研究过如何使这套系统的性能达到最优,也没研究过这套系统的上限是多大。抱歉引用来自“jack1007”的评论
如果日志刷新比较快,比如一天10G的日志,上百台机器,这套系统分析的过来吗?特别是能分析实时的java报错日志吗?引用来自“摆渡者”的评论
额,很遗憾的告诉你,我只是在本地环境使用了几台服务器搭建了这个框架,我也没研究过如何使这套系统的性能达到最优,也没研究过这套系统的上限是多大。抱歉引用来自“痕迹EX”的评论
公司目前的日志系统没有用到ELK方案,整个日志系统架构与ELK相似,但核心也是elasticsearch。实时日志记录都是1秒内查询成功,最近10天,日均日志量在12G左右,一点问题没有引用来自“jack1007”的评论
如果日志刷新比较快,比如一天10G的日志,上百台机器,这套系统分析的过来吗?特别是能分析实时的java报错日志吗?引用来自“摆渡者”的评论
额,很遗憾的告诉你,我只是在本地环境使用了几台服务器搭建了这个框架,我也没研究过如何使这套系统的性能达到最优,也没研究过这套系统的上限是多大。抱歉

引用来自“bill-xu”的评论
楼主大人,我搭建好了之后,打开http://192.168.18.230:5601/,一直显示Configure an index pattern,写上applog也是没有create图标出现,显示:Unable to fetch manpping.Do you have indices matching the passem? 是哪里的问题呢?求帮助


文章摘自:https://my.oschina.net/itblog/blog/547250
https://www.jianshu.com/p/797073c1913f
https://www.cnblogs.com/huangxincheng/p/7918722.html
http://www.178linux.com/71014
https://www.cnblogs.com/yuhuLin/p/7018858.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号