Python爬虫入门:爬取pixiv
终于想开始爬自己想爬的网站了。于是就试着爬P站试试手。
我爬的图的目标网址是: http://www.pixiv.net/search.php?word=%E5%9B%9B%E6%9C%88%E3%81%AF%E5%90%9B%E3%81%AE%E5%98%98,目标是将每一页的图片都爬下来。
一开始以为不用登陆,就直接去爬图片了。
后来发现是需要登录的,但是不会只好去学模拟登陆。
这里是登陆网站 https://accounts.pixiv.net/login?lang=zh&source=pc&view_type=page&ref=wwwtop_accounts_index 的headers,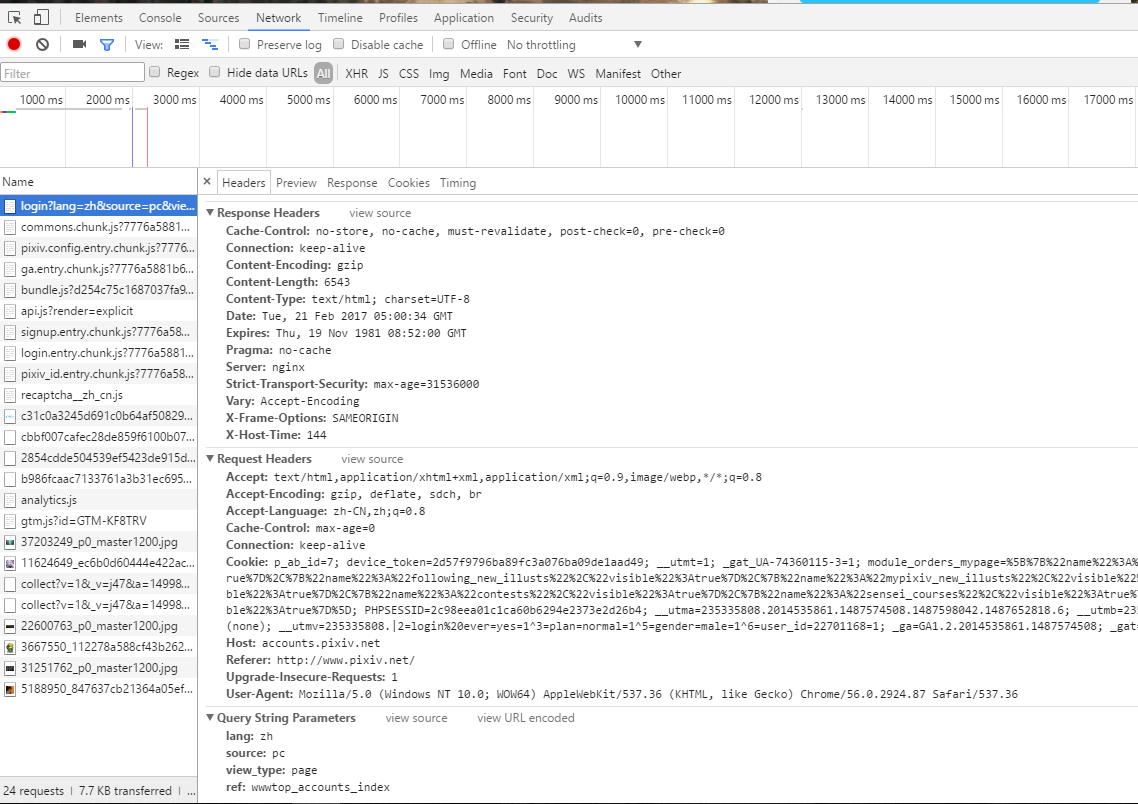
然后还要去获取我们登陆时候需要的data。点住上面的presevelog,找到登陆的网址,点开查看Form Data就可以知道我们post的时候的data需要什么了。这里可以看到有个postkey,多试几次可以发现这个是变化的,即我们要去捕获它,而不能直接输入。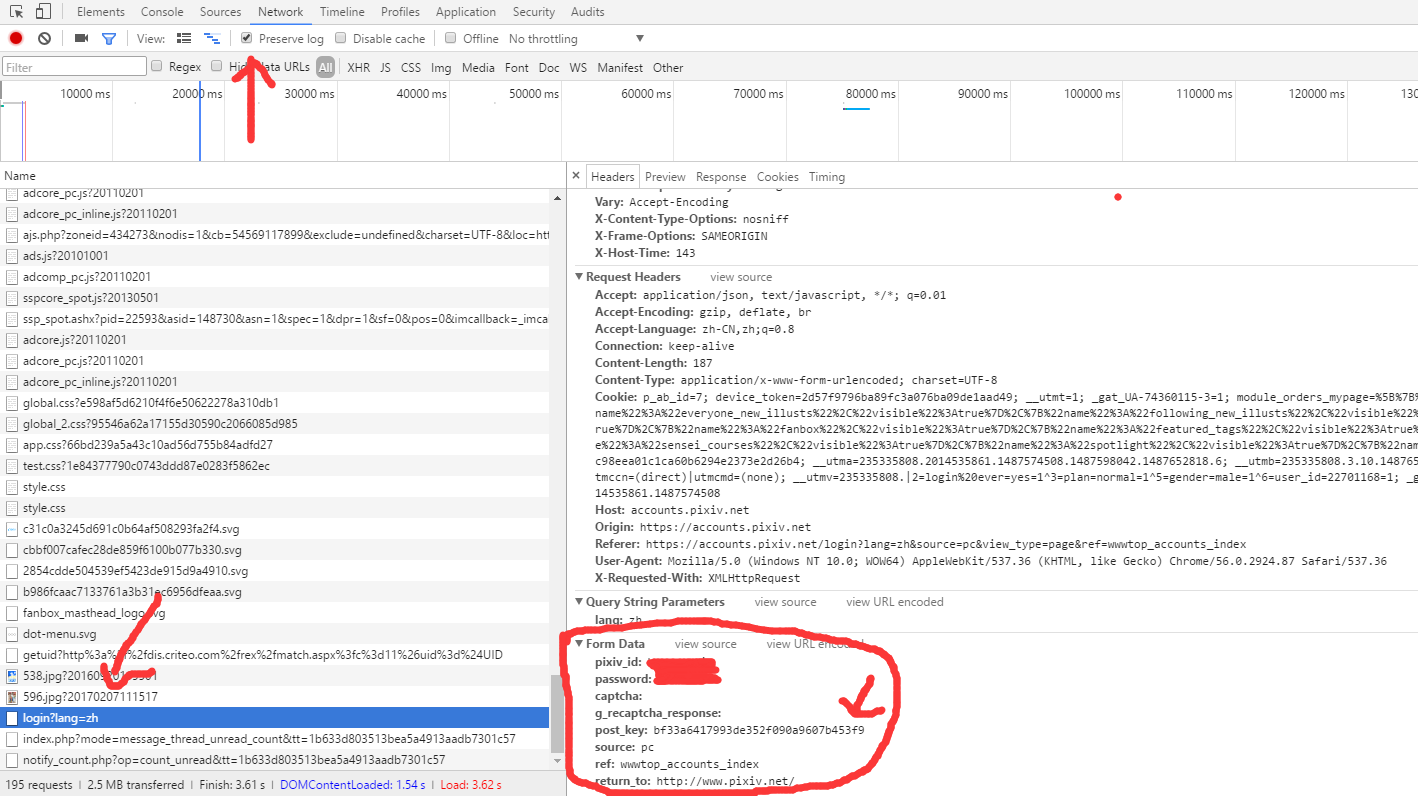
于是退回到登陆界面,F12查看源码,发现有一个postkey,那么我们就可以写一个东西去捕获它,然后把它放到我们post的data里面。
这里给出登陆界面需要的代码:
1 def __init__(self): 2 self.base_url = 'https://accounts.pixiv.net/login?lang=zh&source=pc&view_type=page&ref=wwwtop_accounts_index' 3 self.login_url = 'https://accounts.pixiv.net/api/login?lang=zh' 4 self.target_url = 'http://www.pixiv.net/search.php?' \ 5 'word=%E5%9B%9B%E6%9C%88%E3%81%AF%E5%90%9B%E3%81%AE%E5%98%98&order=date_d&p=' 6 self.main_url = 'http://www.pixiv.net' 7 # headers只要这两个就可以了,之前加了太多其他的反而爬不上 8 self.headers = { 9 'Referer': 'https://accounts.pixiv.net/login?lang=zh&source=pc&view_type=page&ref=wwwtop_accounts_index', 10 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) ' 11 'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36' 12 } 13 self.pixiv_id = 'userid' 14 self.password = '*****' 15 self.post_key = [] 16 self.return_to = 'http://www.pixiv.net/' 17 self.load_path = 'D:\psdcode\Python\pixiv_pic' 18 self.ip_list = [] 19 20 def login(self): 21 post_key_html = se.get(self.base_url, headers=self.headers).text 22 post_key_soup = BeautifulSoup(post_key_html, 'lxml') 23 self.post_key = post_key_soup.find('input')['value'] 24 # 上面是去捕获postkey 25 data = { 26 'pixiv_id': self.pixiv_id, 27 'password': self.password, 28 'return_to': self.return_to, 29 'post_key': self.post_key 30 } 31 se.post(self.login_url, data=data, headers=self.headers)
愉快地解决完登陆问题之后,就可以开始爬图片啦。
进入target_url:上面的目标网址。
点击目标的位置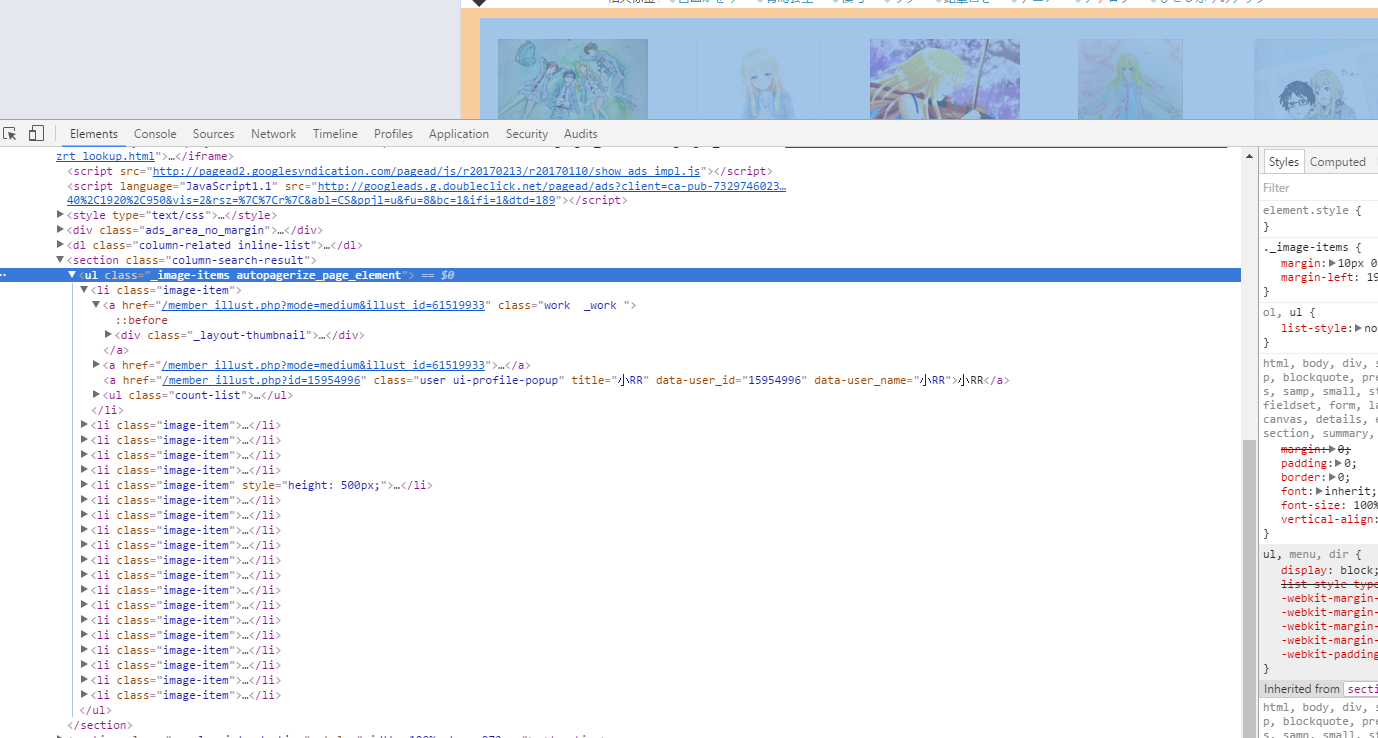
点开ul这个标签,发现图片全部都是在<li class="image-item">这里面的,因为我们要爬大一点的图(爬个小图有什么用啊!),所以还要进入一层第一个链接的网址去获取大图,我们可以发现我们只要在main_url((http://www.pixiv.net)),再加上第一个href,就可以跑到图片所在的网址了,于是我们先跳转到图片网址看看怎么提取图片。
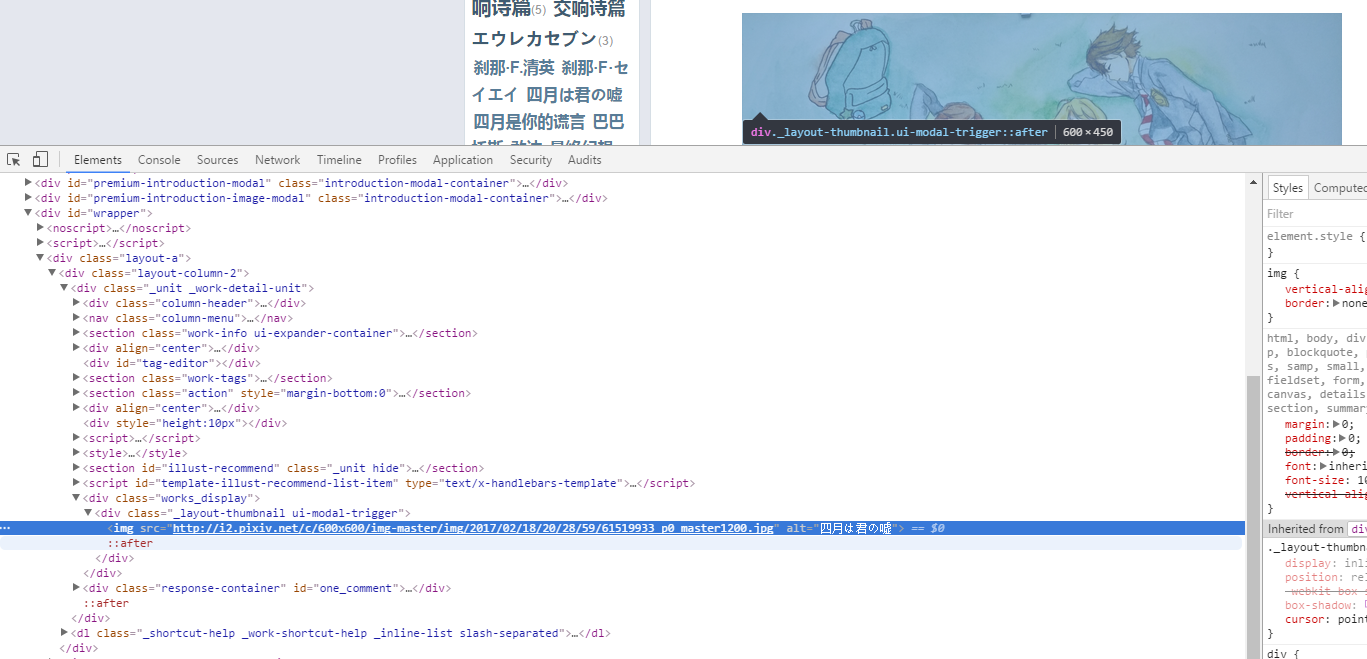
发现图片就躺在这里了,而且连标题都有,直接方便了我们存图的名字了。于是我们就可以直接去提取图片了。
注意我们在请求获取图片的时候要加一个referer,否则会403的。referer的找法就和上面一样。
1 def get_img(self, html, page_num): 2 li_soup = BeautifulSoup(html, 'lxml') # 传入第page_num页的html 3 li_list = li_soup.find_all('li', attrs={'class', 'image-item'}) # 找到li所在位置 4 # print('get_list succeed') 5 # print(li_list) 6 for li in li_list: 7 href = li.find('a')['href'] # 直接提取第一个href 8 # print('get_href succeed') 9 # print(href) 10 jump_to_url = self.main_url + href # 跳转到目标的url 11 # print('get_jump_to_url succeed') 12 jump_to_html = self.get_html(jump_to_url, 3).text # 获取图片的html 13 # print('get_jump_to_html succeed') 14 15 img_soup = BeautifulSoup(jump_to_html, 'lxml') 16 img_info = img_soup.find('div', attrs={'class', 'works_display'})\ 17 .find('div', attrs={'class', '_layout-thumbnail ui-modal-trigger'}) 18 # 找到目标位置的信息 19 if img_info is None: # 有些找不到url,如果不continue会报错 20 continue 21 self.download_img(img_info, jump_to_url, page_num) # 去下载这个图片 22 23 def download_img(self, img_info, href, page_num): 24 title = img_info.find('img')['alt'] # 提取标题 25 src = img_info.find('img')['src'] # 提取图片位置 26 src_headers = self.headers 27 src_headers['Referer'] = href # 增加一个referer,否则会403,referer就像上面登陆一样找 28 try: 29 html = requests.get(src, headers=src_headers) 30 img = html.content 31 except: # 有时候会发生错误导致不能获取图片.直接跳过这张图吧 32 print('获取该图片失败') 33 return False
接下来轮到下载图片了。这个之前还不怎么会,临时学了一下。
首先是创建文件夹,我这里是每一页就开一个文件夹。
1 def mkdir(self, path): 2 path = path.strip() 3 is_exist = os.path.exists(os.path.join(self.load_path, path)) 4 if not is_exist: 5 print('创建一个名字为 ' + path + ' 的文件夹') 6 os.makedirs(os.path.join(self.load_path, path)) 7 os.chdir(os.path.join(self.load_path, path)) 8 return True 9 else: 10 print('名字为 ' + path + ' 的文件夹已经存在') 11 os.chdir(os.path.join(self.load_path, path)) 12 return False
1 def download_img(self, img_info, href, page_num): 2 title = img_info.find('img')['alt'] # 提取标题 3 src = img_info.find('img')['src'] # 提取图片位置 4 src_headers = self.headers 5 src_headers['Referer'] = href # 增加一个referer,否则会403,referer就像上面登陆一样找 6 try: 7 html = requests.get(src, headers=src_headers) 8 img = html.content 9 except: # 有时候会发生错误导致不能获取图片.直接跳过这张图吧 10 print('获取该图片失败') 11 return False 12 13 title = title.replace('?', '_').replace('/', '_').replace('\\', '_').replace('*', '_').replace('|', '_')\ 14 .replace('>', '_').replace('<', '_').replace(':', '_').replace('"', '_').strip() 15 # 去掉那些不能在文件名里面的.记得加上strip()去掉换行 16 17 if os.path.exists(os.path.join(self.load_path, str(page_num), title + '.jpg')): 18 for i in range(1, 100): 19 if not os.path.exists(os.path.join(self.load_path, str(page_num), title + str(i) + '.jpg')): 20 title = title + str(i) 21 break 22 # 如果重名了,就加上一个数字 23 print('正在保存名字为: ' + title + ' 的图片') 24 with open(title + '.jpg', 'ab') as f: 25 f.write(img) 26 print('保存该图片完毕')
这样我们的大体工作就做完了。剩下的是写一个work函数让它开始跑。
1 def work(self): 2 self.login() 3 for page_num in range(1, 51): # 太多页了,只跑50页 4 path = str(page_num) # 每一页就开一个文件夹 5 self.mkdir(path) # 创建文件夹 6 # print(self.target_url + str(page_num)) 7 now_html = self.get_html(self.target_url + str(page_num), 3) # 获取页码 8 self.get_img(now_html.text, page_num) # 获取图片 9 print('第 {page} 页保存完毕'.format(page=page_num)) 10 time.sleep(2) # 防止太快被反
启动!
大概跑了10页之后,会弹出一大堆信息什么requests不行怎么的。问了下别人应该是被反爬了。
于是去搜了一下资料,http://cuiqingcai.com/3256.html,照着他那样写了使用代理的东西。(基本所有东西都在这学的)。
于是第一个小爬虫就好了。不过代理的东西还没怎么懂,到时候看看,50页爬了两个多钟。
对了。可能网站的源代码会有改动的。因为我吃完饭后用吃饭前的代码继续工作的时候出错了,然后要仔细观察重新干。
1 # -*- coding:utf-8 -*- 2 import requests 3 from bs4 import BeautifulSoup 4 import os 5 import time 6 import re 7 import random 8 9 se = requests.session() 10 11 12 class Pixiv(): 13 14 def __init__(self): 15 self.base_url = 'https://accounts.pixiv.net/login?lang=zh&source=pc&view_type=page&ref=wwwtop_accounts_index' 16 self.login_url = 'https://accounts.pixiv.net/api/login?lang=zh' 17 self.target_url = 'http://www.pixiv.net/search.php?' \ 18 'word=%E5%9B%9B%E6%9C%88%E3%81%AF%E5%90%9B%E3%81%AE%E5%98%98&order=date_d&p=' 19 self.main_url = 'http://www.pixiv.net' 20 # headers只要这两个就可以了,之前加了太多其他的反而爬不上 21 self.headers = { 22 'Referer': 'https://accounts.pixiv.net/login?lang=zh&source=pc&view_type=page&ref=wwwtop_accounts_index', 23 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) ' 24 'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36' 25 } 26 self.pixiv_id = 'userid' 27 self.password = '*****' 28 self.post_key = [] 29 self.return_to = 'http://www.pixiv.net/' 30 self.load_path = 'D:\psdcode\Python\pixiv_pic' 31 self.ip_list = [] 32 33 def login(self): 34 post_key_html = se.get(self.base_url, headers=self.headers).text 35 post_key_soup = BeautifulSoup(post_key_html, 'lxml') 36 self.post_key = post_key_soup.find('input')['value'] 37 # 上面是去捕获postkey 38 data = { 39 'pixiv_id': self.pixiv_id, 40 'password': self.password, 41 'return_to': self.return_to, 42 'post_key': self.post_key 43 } 44 se.post(self.login_url, data=data, headers=self.headers) 45 46 def get_proxy(self): 47 html = requests.get('http://haoip.cc/tiqu.htm') 48 ip_list_temp = re.findall(r'r/>(.*?)<b', html.text, re.S) 49 for ip in ip_list_temp: 50 i = re.sub('\n', '', ip) 51 self.ip_list.append(i.strip()) 52 print(i.strip()) 53 54 ''' 会被反爬,改成使用代理 55 def get_tml(self, url): 56 response = se.get(url, headers=self.headers) 57 return response 58 ''' 59 def get_html(self, url, timeout, proxy=None, num_entries=5): 60 if proxy is None: 61 try: 62 return se.get(url, headers=self.headers, timeout=timeout) 63 except: 64 if num_entries > 0: 65 print('获取网页出错,5秒后将会重新获取倒数第', num_entries, '次') 66 time.sleep(5) 67 return self.get_html(url, timeout, num_entries = num_entries - 1) 68 else: 69 print('开始使用代理') 70 time.sleep(5) 71 ip = ''.join(str(random.choice(self.ip_list))).strip() 72 now_proxy = {'http': ip} 73 return self.get_html(url, timeout, proxy = now_proxy) 74 else: 75 try: 76 return se.get(url, headers=self.headers, proxies=proxy, timeout=timeout) 77 except: 78 if num_entries > 0: 79 print('正在更换代理,5秒后将会重新获取第', num_entries, '次') 80 time.sleep(5) 81 ip = ''.join(str(random.choice(self.ip_list))).strip() 82 now_proxy = {'http': ip} 83 return self.get_html(url, timeout, proxy = now_proxy, num_entries = num_entries - 1) 84 else: 85 print('使用代理失败,取消使用代理') 86 return self.get_html(url, timeout) 87 88 def get_img(self, html, page_num): 89 li_soup = BeautifulSoup(html, 'lxml') # 传入第page_num页的html 90 li_list = li_soup.find_all('li', attrs={'class', 'image-item'}) # 找到li所在位置 91 # print('get_list succeed') 92 # print(li_list) 93 for li in li_list: 94 href = li.find('a')['href'] # 直接提取第一个href 95 # print('get_href succeed') 96 # print(href) 97 jump_to_url = self.main_url + href # 跳转到目标的url 98 # print('get_jump_to_url succeed') 99 jump_to_html = self.get_html(jump_to_url, 3).text # 获取图片的html 100 # print('get_jump_to_html succeed') 101 102 img_soup = BeautifulSoup(jump_to_html, 'lxml') 103 img_info = img_soup.find('div', attrs={'class', 'works_display'})\ 104 .find('div', attrs={'class', '_layout-thumbnail ui-modal-trigger'}) 105 # 找到目标位置的信息 106 if img_info is None: # 有些找不到url,如果不continue会报错 107 continue 108 self.download_img(img_info, jump_to_url, page_num) # 去下载这个图片 109 110 def download_img(self, img_info, href, page_num): 111 title = img_info.find('img')['alt'] # 提取标题 112 src = img_info.find('img')['src'] # 提取图片位置 113 src_headers = self.headers 114 src_headers['Referer'] = href # 增加一个referer,否则会403,referer就像上面登陆一样找 115 try: 116 html = requests.get(src, headers=src_headers) 117 img = html.content 118 except: # 有时候会发生错误导致不能获取图片.直接跳过这张图吧 119 print('获取该图片失败') 120 return False 121 122 title = title.replace('?', '_').replace('/', '_').replace('\\', '_').replace('*', '_').replace('|', '_')\ 123 .replace('>', '_').replace('<', '_').replace(':', '_').replace('"', '_').strip() 124 # 去掉那些不能在文件名里面的.记得加上strip()去掉换行 125 126 if os.path.exists(os.path.join(self.load_path, str(page_num), title + '.jpg')): 127 for i in range(1, 100): 128 if not os.path.exists(os.path.join(self.load_path, str(page_num), title + str(i) + '.jpg')): 129 title = title + str(i) 130 break 131 # 如果重名了,就加上一个数字 132 print('正在保存名字为: ' + title + ' 的图片') 133 with open(title + '.jpg', 'ab') as f: # 图片要用b 134 f.write(img) 135 print('保存该图片完毕') 136 137 def mkdir(self, path): 138 path = path.strip() 139 is_exist = os.path.exists(os.path.join(self.load_path, path)) 140 if not is_exist: 141 print('创建一个名字为 ' + path + ' 的文件夹') 142 os.makedirs(os.path.join(self.load_path, path)) 143 os.chdir(os.path.join(self.load_path, path)) 144 return True 145 else: 146 print('名字为 ' + path + ' 的文件夹已经存在') 147 os.chdir(os.path.join(self.load_path, path)) 148 return False 149 150 def work(self): 151 self.login() 152 for page_num in range(1, 51): # 太多页了,只跑50页 153 path = str(page_num) # 每一页就开一个文件夹 154 self.mkdir(path) # 创建文件夹 155 # print(self.target_url + str(page_num)) 156 now_html = self.get_html(self.target_url + str(page_num), 3) # 获取页码 157 self.get_img(now_html.text, page_num) # 获取图片 158 print('第 {page} 页保存完毕'.format(page=page_num)) 159 time.sleep(2) # 防止太快被反 160 161 162 pixiv = Pixiv() 163 pixiv.work()

