【Python】【数据分析】简单数据预处理
数据清洗
数据清洗的目的不只是要消除错误、冗余和数据噪音,还要能将按不同的、不兼容的规则所得的各种数据集一致起来。
缺失值处理
找到缺失值:(输出每个列丢失值也即值为NaN的数据和,并从多到少排序)
#输出数量
total = train.isnull().sum().sort_values(ascending=False)
print(total)
#输出百分比
percent =(train.isnull().sum()/train.isnull().count()).sort_values(ascending=False)
missing_data = pd.concat([total, percent], axis=1, keys=['Total', 'Percent'])
missing_data.head(20)
删除法
- (1)删除观测样本
- (2)删除变量:当某个变量缺失值较多且对研究目标影响不大时,可以将整个变量整体删除
- (3)使用完整原始数据分析:当数据存在较多缺失而其原始数据完整时,可以使用原始数据替代现有数据进行分析;
- (4)改变权重:当删除缺失数据会改变数据结构时,通过对完整数据按照不同的权重进行加工,可以降低删除数据带来的偏差。
插补法
在条件允许的情况下,找到缺失值的替代值进行插补,尽可能还原真实数据是更好的方法。常见的方法有均值插补、回归插补、二阶插补、热平台、冷平台等单一变量插补。
- (1)均值法是通过计算缺失值所在变量所有非缺失观测值的均值,使用均值来代替缺失值的插补方法。
- (2)均值法不能利用相关变量信息,因此会存在一定偏差,而回归模型是将需要插补变量作为因变量,其他相关变量作为自变量,通过建立回归模型预测出因变量的值对缺失变量进行插补。
- (3)热平台插补是指在非缺失数据集中找到一个与缺失值所在样本相似的样本(匹配样本),利用其中的观测值对缺失值进行插补。
- (4)在实际操作中,尤其当变量数量很多时,通常很难找到与需要插补样本完全相同的样本,此时可以按照某些变量将数据分层,在层中对缺失值使用均值插补,即采取冷平台插补法。
#使用出现次数最多的值填补
train['Embarked'] = train['Embarked'].fillna('S')
train.product_type[train.product_type.isnull()]=train.product_type.dropna().mode().values
#使用中位数填补
train['Fare'] = train['Fare'].fillna(train['Fare'].median())
#使用平均数填补
train['Age'] = train['Age'].fillna(train['Age'].mean())
train['LotFrontage'].fillna(train['LotFrontage'].mean())
另外一种插补方法:sklearn的Imputer类
#以下代码段演示了如何使用包含缺少值的列(轴0)的平均值替换编码为np.nan的缺失值:
import numpy as np
from sklearn.preprocessing import Imputer
imp = Imputer(missing_values='NaN', strategy='mean', axis=0) # missing_values:integer/“NaN”, strategy:mean/median/most_frequent
imp.fit([[1, 2], [np.nan, 3], [7, 6]])
"""
输出:
Imputer(axis=0, copy=True, missing_values='NaN', strategy='mean', verbose=0)
"""
X = [[np.nan, 2], [6, np.nan], [7, 6]]
imp.transform(X)
"""
输出:
array([[ 4. , 2. ],
[ 6. , 3.66666667],
[ 7. , 6. ]])
"""
#Imputer类还支持稀疏矩阵:
import scipy.sparse as sp
X = sp.csc_matrix([[1, 2], [0, 3], [7, 6]])
imp = Imputer(missing_values=0, strategy='mean', axis=0)
imp.fit(X)
"""
Imputer(axis=0, copy=True, missing_values=0, strategy='mean', verbose=0)
"""
X_test = sp.csc_matrix([[0, 2], [6, 0], [7, 6]])
imp.transform(X_test)
"""
输出:
array([[ 4. , 2. ],
[ 6. , 3.66666667],
[ 7. , 6. ]])
"""
噪声处理
- 噪声检查中比较常见的方法:
null
(1)通过寻找数据集中与其他观测值及均值差距最大的点作为异常
(2)聚类方法检测,将类似的取值组织成“群”或“簇”,落在“簇”集合之外的值被视为离群点。
如:
#bivariate analysis saleprice/grlivarea
var = 'GrLivArea'
data = pd.concat([df_train['SalePrice'], df_train[var]], axis=1)
data.plot.scatter(x=var, y='SalePrice', ylim=(0,800000));

删除偏离值:
train.sort_values(by = 'GrLivArea', ascending = False)[:2]
train= train.drop(train[train['Id'] == 1299].index)
train= train.drop(train[train['Id'] == 524].index)
- 在进行噪声检查后,通常采用分箱、聚类、回归、计算机检查和人工检查结合等方法“光滑”数据,去掉数据中的噪声。
- 分箱:分箱方法是一种简单常用的预处理方法,通过考察相邻数据来确定最终值。所谓“分箱”,实际上就是按照属性值划分的子区间,如果一个属性值处于某个子区间范围内,就称把该属性值放进这个子区间所代表的“箱子”内。把待处理的数据(某列属性值)按照一定的规则放进一些箱子中,考察每一个箱子中的数据,采用某种方法分别对各个箱子中的数据进行处理。在采用分箱技术时,需要确定的两个主要问题就是:如何分箱以及如何对每个箱子中的数据进行平滑处理。
- 分箱的方法:有4种:等深分箱法、等宽分箱法、最小熵法和用户自定义区间法。
数据平滑方法
- 按平均值平滑 :对同一箱值中的数据求平均值,用平均值替代该箱子中的所有数据。
- 按边界值平滑:用距离较小的边界值替代箱中每一数据。
- 按中值平滑:取箱子的中值,用来替代箱子中的所有数据。
数据集成
将多个数据源中的数据合并,并存放到一个一致的数据存储(如数据仓库)中。这些数据源可能包括多个数据库、数据立方体或一般文件。
数据变换
找到数据的特征表示,用维度变换来减少有效变量的数目或找到数据的不变式,包括规格化、规约、切换和投影等操作。
- 光滑:去掉噪声;
- 属性构造:由给定的属性构造出新属性并添加到数据集中。例如,通过“销售额”和“成本”构造出“利润”,只需要对相应属性数据进行简单变换即可
- 聚集:对数据进行汇总。比如通过日销售数据,计算月和年的销售数据;
- 规范化:把数据单按比例缩放,比如数据标准化处理;
- 离散化:将定量数据向定性数据转化。比如一系列连续数据,可用标签进行替换(0,1);
数制转换
#浮点型数值转换为整型
train['Age']=train['Age'].astype(int)
#字符串的替换--映射
train['MSZoning']=train['MSZoning'].map({'RL':1,'RM':2,'RR':3,}).astype(int)
train['Embarked'] = train['Embarked'].map( {'S': 0, 'C': 1, 'Q': 2} ).astype(int)
#一般建议将map拿出来
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5}
train['Title'] = train['Title'].map(title_mapping)
train['Title'] = train['Title'].fillna(0)
#将字符串特征列中的内容分别提出来作为新的特征出现,表现为0、1。
train= pd.get_dummies(houseprice)
#将连续型特征值分块,每一块用数字标识
train.loc[ train['Fare'] <= 7.91, 'Fare'] = 0
train.loc[(train['Fare'] > 7.91) & (train['Fare'] <= 14.454), 'Fare'] = 1
train.loc[(train['Fare'] > 14.454) & (train['Fare'] <= 31), 'Fare'] = 2
train.loc[ train['Fare'] > 31, 'Fare'] = 3
train['Fare'] = train['Fare'].astype(int)
#将数值进行log计算,使分布的数值显常态
train['SalePrice'] = np.log(train['SalePrice'])
##而有时这样的log不可行,就需要使用log(x+1)来 处理
#train["SalePrice"] = np.log1p(train["SalePrice"])
#将偏斜度大于0.75的数值列log转换,使之尽量符合正态分布。
skewed_feats = train[numeric_feats].apply(lambda x: skew(x.dropna())) #compute skewness
skewed_feats = skewed_feats[skewed_feats > 0.75]
skewed_feats = skewed_feats.index
all_data[skewed_feats] = np.log1p(all_data[skewed_feats])

标准化
from sklearn import preprocessing
import numpy as np
X = np.array([[ 1., -1., 2.],
[ 2., 0., 0.],
[ 0., 1., -1.]])
X_scaled = preprocessing.scale(X) #数据标准化
X_scaled #输出标准化的结果:
X_scaled.mean(axis=0) #axis指出用于计算均值和标准偏差的轴。如果为0,独立规范每个特征,否则(如果为1)标准化每个样本。#输出归一化后的均值
X_scaled.std(axis=0) #输出标准化后的标准差
计算标准化后的数字特征:
#with_mean 默认为True 表示使用密集矩阵,使用稀疏矩阵则会报错 ,with_mean= False 适用于稀疏矩阵
#with_std 默认为True 如果为True,则将数据缩放为单位方差(单位标准偏差)
scaler = preprocessing.StandardScaler().fit(X)
scaler #输出:StandardScaler(copy=True, with_mean=True, with_std=True)
#StandardScaler()的属性
scaler.mean_ #输出X(原数据)每列的均值:
scaler.scale_ #输出X(原数据)每列的标准差(标准偏差):
scaler.var_ #输出X(原数据)每列的方差:
#StandardScaler()的方法
scaler.transform(X) #输出X(原数据)标准化(z-score):
StandardScaler().fit(X) # 输入数据用于计算以后缩放的平均值和标准差
StandardScaler().fit_transform(X) #输入数据,然后转换它
scaler.get_params() #获取此估计量的参数 #输出:{'copy': True, 'with_mean': True, 'with_std': True}
scaler.inverse_transform(scaler.transform(X))#将标准化后的数据转换成原来的数据
scaler.partial_fit(X) # 在X缩放以后 在线计算平均值和std
scaler.set_params(with_mean=False) # 设置此估计量的参数
归一化
缩放特征到给定的最小值到最大值之间,通常在0到1之间。或则使得每个特征的最大绝对值被缩放到单位大小。这可以分别使用MinMaxScaler或MaxAbsScaler函数实现。
"""
#训练集数据 例如缩放到[0-1]
"""
MinMaxScaler 参数feature_range=(0, 1)数据集的分布范围, copy=True 副本
计算公式如下:
X_std = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))
X_scaled = X_std * (max - min) + min
"""
X_train = np.array([[ 1., -1., 2.],
[ 2., 0., 0.],
[ 0., 1., -1.]])
min_max_scaler = preprocessing.MinMaxScaler()
X_train_minmax = min_max_scaler.fit_transform(X_train)
X_train_minmax
"""
输出训练集:
array([[ 0.5 , 0. , 1. ],
[ 1. , 0.5 , 0.33333333],
[ 0. , 1. , 0. ]])
"""
#测试集数据
X_test = np.array([[ -3., -1., 4.]])
X_test_minmax = min_max_scaler.transform(X_test)
X_test_minmax
"""
输出测试集:
array([[-1.5 , 0. , 1.66666667]])
"""
"""
MaxAbsScaler 通过其最大绝对值来缩放每个特征,范围在[-1,1]。它用于已经以零或稀疏数据为中心的数据,应用于稀疏CSR或CSC矩阵。
X_std = X/每列的最大绝对值
"""
X_train = np.array([[ 1., -1., 2.],
[ 2., 0., 0.],
[ 0., 1., -1.]])
max_abs_scaler = preprocessing.MaxAbsScaler()
X_train_maxabs = max_abs_scaler.fit_transform(X_train)
X_train_maxabs
"""
输出训练集:
array([[ 0.5, -1. , 1. ],
[ 1. , 0. , 0. ],
[ 0. , 1. , -0.5]])
"""
max_abs_scaler.scale_
"""
输出训练集的缩放数据:
array([ 2., 1., 2.])
"""
X_test = np.array([[ -3., -1., 4.]])
X_test_maxabs = max_abs_scaler.transform(X_test)
X_test_maxabs
"""
输出测试集:
array([[-1.5, -1. , 2. ]])
"""
归一化是缩放单个样本以具有单位范数的过程。 如果您计划使用二次形式(如点积或任何其他内核)来量化任何样本对的相似性,则此过程可能很有用。这个假设基于经常被用于文本分类和聚类上下文的空间向量模型上。函数normalize提供了一个快速和简单的方法来在单个数组类数据集上执行此操作,使用L1或L2范数。
X_normalized = preprocessing.normalize(X, norm='l2')
X_normalized # 输出L2归一化
transform(X[, y, copy])将X的每个非零行缩放为单位范数。
normalizer = preprocessing.Normalizer(norm='l1').fit(X) # fit 无用
normalizer.transform(X)
"""
输出:
array([[ 0.25, -0.25, 0.5 ],
[ 1. , 0. , 0. ],
[ 0. , 0.5 , -0.5 ]])
"""
二值化
X = [[ 1., -1., 2.],
[ 2., 0., 0.],
[ 0., 1., -1.]]
binarizer = preprocessing.Binarizer().fit(X) # fit does nothing
binarizer
"""
输出:
Binarizer(copy=True, threshold=0.0)
"""
binarizer.transform(X)
"""
输出:
array([[ 1., 0., 1.],
[ 1., 0., 0.],
[ 0., 1., 0.]])
"""
#可以调整二值化器的阈值
binarizer = preprocessing.Binarizer(threshold=1.1)
binarizer.transform(X)
"""
输出:
array([[ 0., 0., 1.],
[ 1., 0., 0.],
[ 0., 0., 0.]])
"""
数据简单统计
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
train = pd.read_csv('train.csv')
#统计某一列中各个元素值出现的次数
train['MSSubClass'].value_counts()
#
#列出数据的偏斜度
train['MSSubClass'].skew()
#列出数据的峰度
train['MSSubClass'].kurt()
#计算两个列的相关度
train['LotFrontage'].corr(train['LotArea'])
#观察两个列的值的二维图
x = 'GrLivArea'
y = 'SalePrice'
data = pd.concat([train[y], train[x]], axis=1)
data.plot.scatter(x=x, y=y, ylim=(0,800000));#这里800000为y的最大值
#计算所有特征值每两个之间的相关系数,并作图表示。
corrmat = train.corr()#得到相关系数
f,ax = plt.subplots(figsize = (12,9))
sns.heatmap(corrmat, vmax = .8, square = True)#热点图
#取出相关性最大的前十个,做出热点图表示
k = 10 #number of variables for heatmap
cols = corrmat.nlargest(k, 'SalePrice')['SalePrice'].index
cm = np.corrcoef(train[cols].values.T)
sns.set(font_scale=1.25)
hm = sns.heatmap(cm, cbar=True, annot=True, square=True, fmt='.2f', annot_kws={'size': 10}, yticklabels=cols.values, xticklabels=cols.values)
plt.show()

热点图:
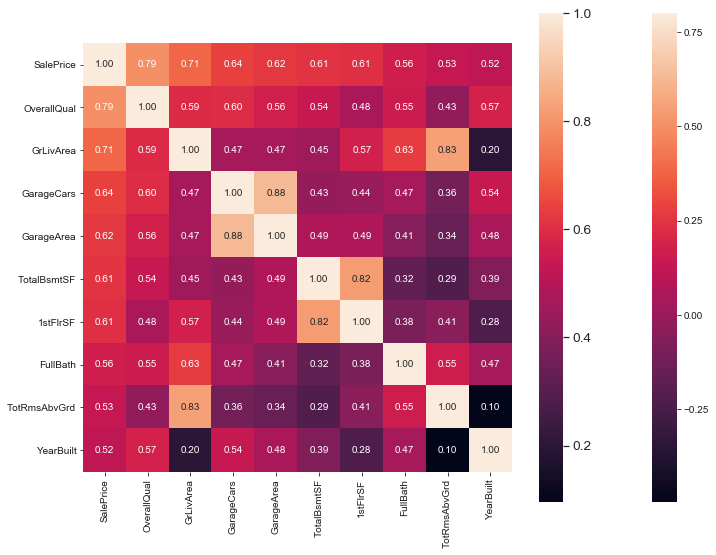
数据规约
是在对发现任务和数据本身内容理解的基础上,寻找依赖于发现目标的表达数据的有用特征,以缩减数据模型,从而在尽可能保持数据原貌的前提下最大限度的精简数据量,主要有两个途径:属性选择和数据抽样,分别针对数据库中的属性和记录。
数据归约通常用维归约、数值归约方法实现。维归约指通过减少属性的方式压缩数据量,通过移除不相关的属性,可以提高模型效率。常见的维归约方法有:分类树、随机森林通过对分类效果的影响大小筛选属性;小波变换、主成分分析通过把原数据变换或投影到较小的空间来降低维数。
特征值合并、连接
在合并连接之前,我们需要了解pandas.groupby这个分组方法,因为很多时候我们是在从几个特征值里挖掘一些值来当作新的特征值,这样子我们这个分组的方法就显得尤为重要了,如按照同一个用户进行分组来计算这个用户的行为次数当作新的特征值等等。
#按照用户分组---------------------一个特征值
train.groupby('userid',as_index=False)
#按照用户与目的地分组---------------两个特征值
train.groupby(['userid','end_loc'],as_index=False)
#用户、起点、目的地-----------------三个特征值
train.groupby(['userid','start_loc','end_loc'],as_index=False)
#跟MSSubClass进行分组,并求分组后的平均值
train[['MSSubClass', 'LotFrontage']].groupby(['MSSubClass'], as_index=False).mean()
#选取特定的属性的某个值然后进行分类
train[train['date']=='2017-1-2'].groupby(['userid'],as_index=False)
#获得分组后,统计分组中'end_loc'的数量返回为一列由‘userid’和‘user_count’组成的新的DataFrame
user_count = train.groupby('userid',as_index=False)['end_loc'].agg({'user_count':'count'})
#将获得的新的DataFrame合并到train,更多的merge参数请查阅文档
train= pd.merge(train,user_count,on=['userid'],how='left')
user_eloc_count = train.groupby(['userid','end_loc'],as_index=False)['userid'].agg({'user_eloc_count':'count'})
train= pd.merge(train,user_eloc_count,on=['userid','end_loc'],how='left')
#讲训练数据与测试数据连接起来,以便一起进行数据清洗。
#这里需要注意的是,如果没有后面的ignore_index=True,那么index的值在连接后的这个新数据中是不连续的,如果要按照index删除一行数据,可能会发现多删一条。
merge_data=pd.concat([train,test],ignore_index=True)
#另一种合并方式,按列名字进行合并。
all_data = pd.concat((train.loc[:,'MSSubClass':'SaleCondition'], test.loc[:,'MSSubClass':'SaleCondition']))
参考链接
- 机器学习-常见的数据预处理:https://blog.csdn.net/yehui_qy/article/details/53791006
- 用Python进行数据挖掘(数据预处理):https://blog.csdn.net/u011094454/article/details/77618604
- Python机器学习库SKLearn:数据预处理:https://blog.csdn.net/qq_29831163/article/details/89888677

 浙公网安备 33010602011771号
浙公网安备 33010602011771号