

 ,而且图片格式不是光改后缀就行的,必须要用格式转换器转换。之所以这样做的原因是因为在接下来的多图片转换成一个pdf文件时,往往是不能确保每张图片的长宽比例是一样的,为了确保每张图片都能完整的显示,所以只能调整图片的大小。可以看到ppt内容已经展示完整了,到此其实ppt转pdf功能已经基本实现了,但是显示效果依然不算完美毕竟我们其实想要的是在pdf里和在ppt看的是一样的效果,而且每页ppt的长宽其实都是一样的,所以我就在想能不能设置pdf每页的长宽,把pdf每页的长宽设置成和ppt的长宽一样。
,而且图片格式不是光改后缀就行的,必须要用格式转换器转换。之所以这样做的原因是因为在接下来的多图片转换成一个pdf文件时,往往是不能确保每张图片的长宽比例是一样的,为了确保每张图片都能完整的显示,所以只能调整图片的大小。可以看到ppt内容已经展示完整了,到此其实ppt转pdf功能已经基本实现了,但是显示效果依然不算完美毕竟我们其实想要的是在pdf里和在ppt看的是一样的效果,而且每页ppt的长宽其实都是一样的,所以我就在想能不能设置pdf每页的长宽,把pdf每页的长宽设置成和ppt的长宽一样。
@
之前在写文档在线预览时留下了一个小坑,当时比较推荐的做法是将各种类型的文档都由后端统一转成pdf格式再由前端进行展示,但是当时并没有提供将各种类型的文档转pdf的方法,这次就来填一下这个坑。
前端在线预览pdf文件的实现方式可以参考这篇文章:《文档在线预览(四)使用js前端实现word、excel、pdf、ppt 在线预览》中 PDF文件实现前端预览 部分。
事前准备
代码基于 aspose-words(用于word、txt转pdf),itextpdf(用于ppt、图片、excel转pdf),poi(用于word转pdf),spire(用于word、excel转pdf)所以事先需要在项目里下面以下依赖
1、需要的maven依赖
<!-- 不使用 aspose-words方式可不引用 -->
<dependency>
<groupId>com.luhuiguo</groupId>
<artifactId>aspose-words</artifactId>
<version>23.1</version>
</dependency>
<!-- poi -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>5.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>5.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-scratchpad</artifactId>
<version>5.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-excelant</artifactId>
<version>5.2.0</version>
</dependency>
<!-- itextpdf -->
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itextpdf</artifactId>
<version>5.5.13.2</version>
</dependency>
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itext-asian</artifactId>
<version>5.2.0</version>
</dependency>
添加spire依赖(商用,有免费版,但是存在页数和字数限制,不采用spire方式可不添加)
spire在添加pom之前还得先添加maven仓库来源
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.cn/repository/maven-public/</url>
</repository>
接着在项目的pom文件里添加如下依赖
免费版:
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.office.free</artifactId>
<version>5.3.1</version>
</dependency>
付费版版:
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.office</artifactId>
<version>5.3.1</version>
</dependency>
2、后面用到的工具类代码:
package com.fhey.service.common.utils.file;
import cn.hutool.core.util.StrUtil;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
/**
* @author fhey
* @date 2023-04-20 11:15:58
* @description: 文件工具类
*/
public class FileUtil {
private static final Logger logger = LoggerFactory.getLogger(FileUtil.class);
//获取新文件的全路径
public static String getNewFileFullPath(String sourceFilePath, String destFilePath, String ext) {
File destFile = new File(destFilePath);
if (destFile.isFile()) {
return destFilePath;
}
File sourceFile = new File(sourceFilePath);
String sourceFileName = sourceFile.getName();
if (sourceFile.isFile()) {
return destFilePath + File.separator + sourceFileName.substring(0, sourceFileName.lastIndexOf(StrUtil.DOT)) + StrUtil.DOT + ext;
}
return destFilePath + File.separator + sourceFileName + StrUtil.DOT + ext;
}
//判断文件是否是图片
public static boolean isImage(File file) throws IOException {
FileInputStream is = new FileInputStream(file);
byte[] bytes = new byte[8];
is.read(bytes);
is.close();
String type = bytesToHexString(bytes).toUpperCase();
if (type.contains("FFD8FF") //JPEG(jpg)
|| type.contains("89504E47") //PNG
|| type.contains("47494638") //GIF
|| type.contains("49492A00") //TIFF(tif)
|| type.contains("424D") //Bitmap(bmp)
) {
return true;
}
return false;
}
//将文件头转换成16进制字符串
public static String bytesToHexString(byte[] src) {
StringBuilder builder = new StringBuilder();
if (src == null || src.length <= 0) {
return null;
}
for (int i = 0; i < src.length; i++) {
int v = src[i] & 0xFF;
String hv = Integer.toHexString(v);
if (hv.length() < 2) {
builder.append(0);
}
builder.append(hv);
}
return builder.toString();
}
}
一、word文件转pdf文件(支持doc、docx)
1、使用aspose方式
验证代码:
word转pdf的方法比较简单,aspose-words基本都被帮我们搞定了,doc、docx都能支持。
代码:
public static void wordToPdf(String wordPath, String pdfPath) throws Exception {
pdfPath = FileUtil.getNewFileFullPath(wordPath, pdfPath, "pdf");
File file = new File(pdfPath);
FileOutputStream os = new FileOutputStream(file);
Document doc = new Document(wordPath);
doc.save(os, com.aspose.words.SaveFormat.PDF);
}
验证代码:
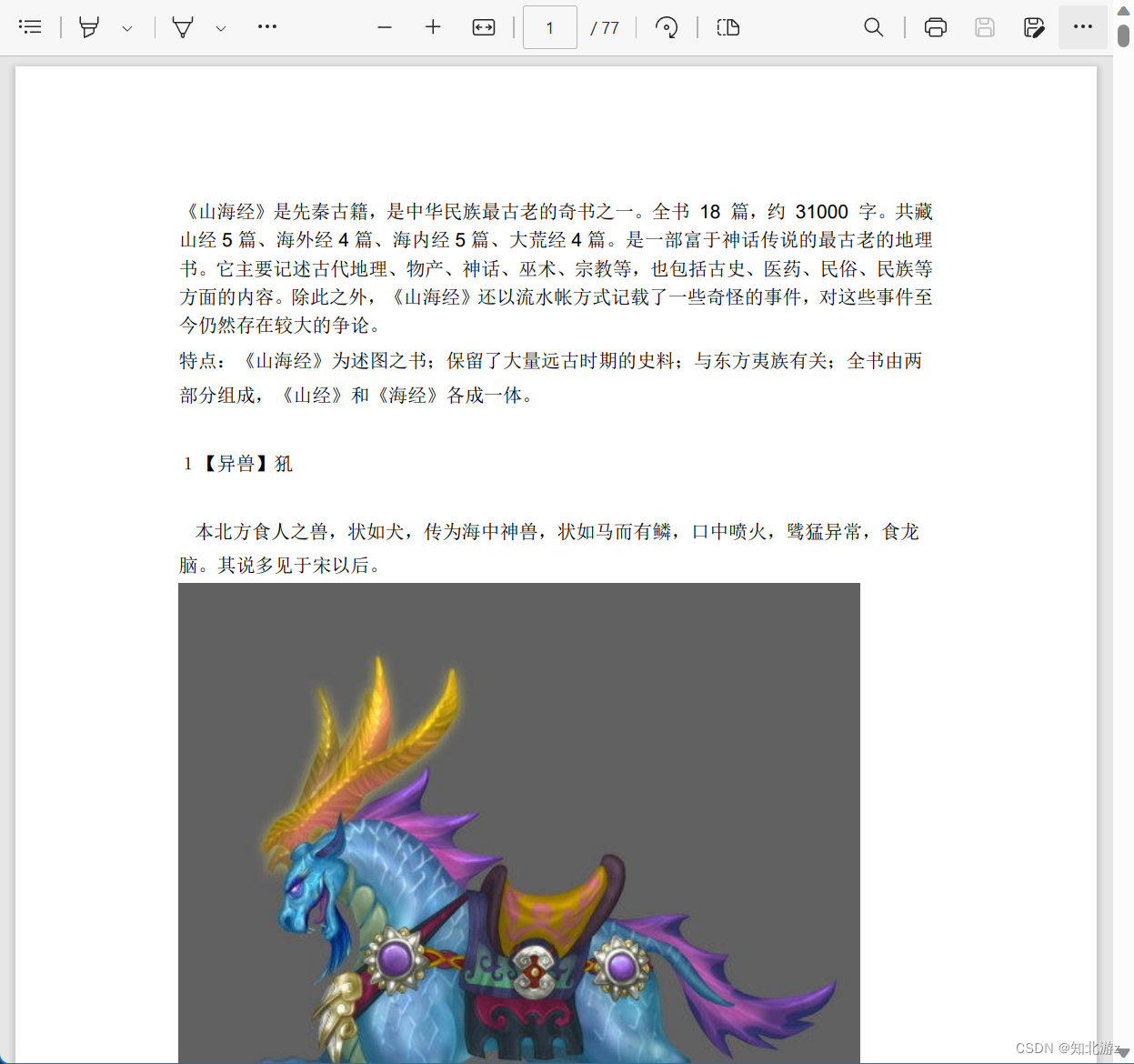
public static void main(String[] args) throws Exception {
wordToPdf("D:\\书籍\\电子书\\其它\\《山海经》异兽图.docx", "D:\\test");
}
转换效果如下,格式、图文都没什么问题,doc、docx经过验证也都能转换成功
2、使用poi方式
代码:
public void wordToPdf(String wordPath, String pdfPath) throws Exception {
pdfPath = FileUtil.getNewFileFullPath(wordPath, pdfPath, "pdf");
try(FileInputStream fileInputStream = new FileInputStream(wordPath);
FileOutputStream fileOutputStream = new FileOutputStream(pdfPath)){
String ext = wordPath.substring(wordPath.lastIndexOf("."));
XWPFDocument document = null;
if (".docx".equals(ext)) {
document = new XWPFDocument(fileInputStream);
} else if (".doc".equals(ext)) {
HWPFDocument hwpfDocument = new HWPFDocument(fileInputStream);
document = hwPFDocumentToXWPFDocument(hwpfDocument);//有问题
} else {
throw new Exception("文件格式不正确");
}
document.write(new FileOutputStream("D:\\test\\test.docx"));
PdfOptions pdfOptions = PdfOptions.create();
PdfConverter.getInstance().convert(document, fileOutputStream, pdfOptions);
document.close();
}
}
public XWPFDocument hwPFDocumentToXWPFDocument(HWPFDocument hwpfDocument) throws Exception {
XWPFDocument xwpfDocument = new XWPFDocument();
xwpfDocument.createStyles();
Range range = hwpfDocument.getRange();
for (int i = 0; i < range.numParagraphs(); i++) {
Paragraph paragraph = range.getParagraph(i);
XWPFParagraph xwpfParagraph = xwpfDocument.createParagraph();
if (paragraph.isInTable()) {
Table table = range.getTable(paragraph);
if (table != null && table.numRows() > 0) {
int rows = table.numRows();
int cols = table.getRow(0).numCells();
XWPFTable xwpfTable = xwpfDocument.createTable(rows, cols);
for (int r = 0; r < rows; r++) {
TableRow tableRow = table.getRow(r);
if (tableRow != null && tableRow.numCells() > 0) {
for (int c = 0; c < cols; c++) {
TableCell tableCell = tableRow.getCell(c);
if (tableCell != null) {
XWPFTableCell xwpfTableCell = xwpfTable.getRow(r).getCell(c);
xwpfTableCell.setText(tableCell.text());
}
}
}
}
}
} else {
List<Picture> allPictures = hwpfDocument.getPicturesTable().getAllPictures();
int d = 0;
for (int j = 0; j < paragraph.numCharacterRuns(); j++) {
CharacterRun run = paragraph.getCharacterRun(j);
Picture picture = hwpfDocument.getPicturesTable().extractPicture(run, false);
if (picture != null) {
byte[] pictureBytes = picture.getContent();
String pictureType = picture.getMimeType();
String fileName = picture.suggestFullFileName();
int pictureType1 = getPictureType(pictureType);
if (pictureType1 == 0) {
continue;
}
if (d > 0) {
continue;
}
InputStream inputStream = new ByteArrayInputStream(pictureBytes);
XWPFParagraph pictureParagraph = xwpfDocument.createParagraph();
XWPFRun pictureRun = pictureParagraph.createRun();
pictureRun.addPicture(inputStream, pictureType1, fileName, Units.toEMU(picture.getWidth()), Units.toEMU(picture.getHeight()));
// 重新设置字体和格式设置
int size = xwpfParagraph.getRuns().size();
if (size == 0) {
continue;
}
XWPFRun previousRun = xwpfParagraph.getRuns().get(size - 1);
pictureRun.setFontFamily(previousRun.getFontFamily());
pictureRun.setFontSize(previousRun.getFontSize());
pictureRun.setBold(previousRun.isBold());
pictureRun.setItalic(previousRun.isItalic());
// 可根据需要设置其他格式设置
xwpfParagraph.addRun(pictureRun);
d++;
} else {
XWPFRun xwpfRun = xwpfParagraph.createRun();
xwpfRun.setText(run.text());
}
}
}
}
hwpfDocument.close();
return xwpfDocument;
}
public static int getPictureType(String mimeType) {
if (mimeType.equals("image/jpeg")) {
return Document.PICTURE_TYPE_JPEG;
} else if (mimeType.equals("image/png")) {
return Document.PICTURE_TYPE_PNG;
} else if (mimeType.equals("image/gif")) {
return Document.PICTURE_TYPE_GIF;
} else if (mimeType.equals("image/bmp")) {
return Document.PICTURE_TYPE_BMP;
} else {
return 0;
//throw new RuntimeException("Unsupported picture: " + mimeType + ". Expected emf|wmf|pict|jpeg|png|dib|gif|tiff|eps|bmp|wpg");
}
}
验证代码:
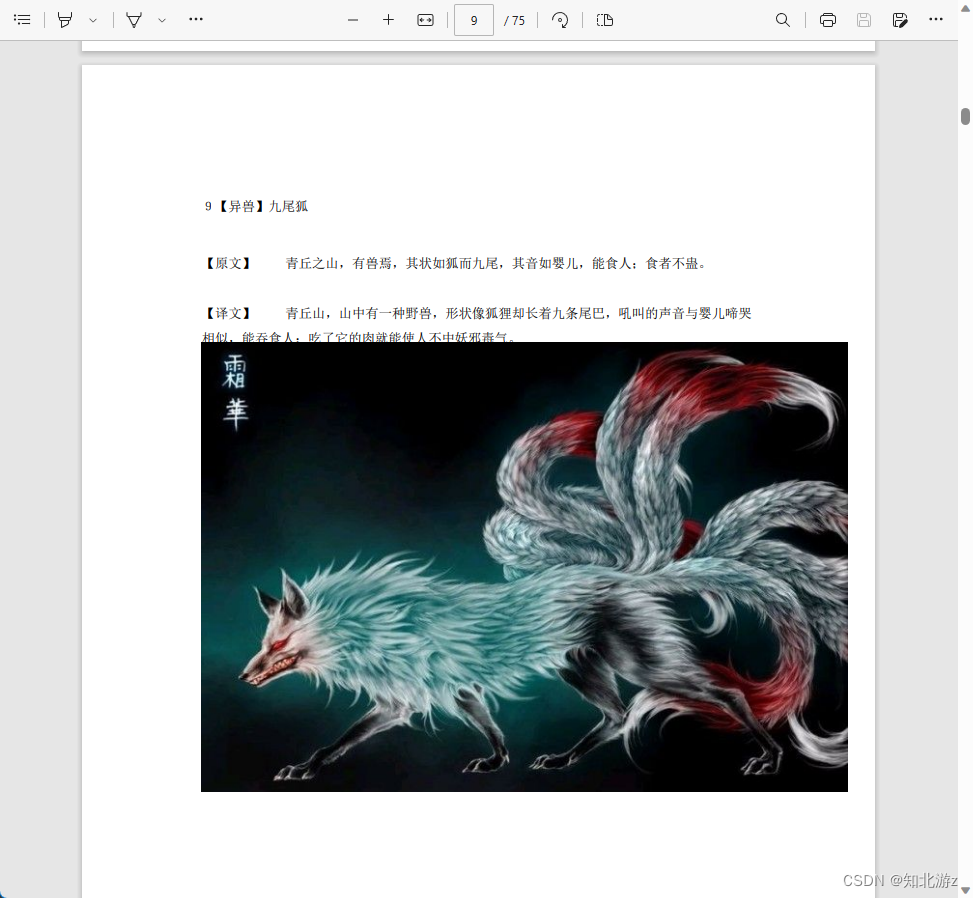
3、使用spire方式
代码:
public void wordToPdf(String wordPath, String pdfPath) throws Exception {
pdfPath = FileUtil.getNewFileFullPath(wordPath, pdfPath, "pdf");
try(FileInputStream fileInputStream = new FileInputStream(wordPath);
FileOutputStream fileOutputStream = new FileOutputStream(pdfPath)){
String ext = wordPath.substring(wordPath.lastIndexOf("."));
XWPFDocument document = null;
if (".docx".equals(ext)) {
document = new XWPFDocument(fileInputStream);
} else if (".doc".equals(ext)) {
HWPFDocument hwpfDocument = new HWPFDocument(fileInputStream);
document = hwPFDocumentToXWPFDocument(hwpfDocument);
} else {
throw new Exception("文件格式不正确");
}
document.write(new FileOutputStream("D:\\test\\test.docx"));
PdfOptions pdfOptions = PdfOptions.create();
PdfConverter.getInstance().convert(document, fileOutputStream, pdfOptions);
document.close();
}
}
public XWPFDocument hwPFDocumentToXWPFDocument(HWPFDocument hwpfDocument) throws Exception {
XWPFDocument xwpfDocument = new XWPFDocument();
xwpfDocument.createStyles();
Range range = hwpfDocument.getRange();
for (int i = 0; i < range.numParagraphs(); i++) {
Paragraph paragraph = range.getParagraph(i);
XWPFParagraph xwpfParagraph = xwpfDocument.createParagraph();
if (paragraph.isInTable()) {
Table table = range.getTable(paragraph);
if (table != null && table.numRows() > 0) {
int rows = table.numRows();
int cols = table.getRow(0).numCells();
XWPFTable xwpfTable = xwpfDocument.createTable(rows, cols);
for (int r = 0; r < rows; r++) {
TableRow tableRow = table.getRow(r);
if (tableRow != null && tableRow.numCells() > 0) {
for (int c = 0; c < cols; c++) {
TableCell tableCell = tableRow.getCell(c);
if (tableCell != null) {
XWPFTableCell xwpfTableCell = xwpfTable.getRow(r).getCell(c);
xwpfTableCell.setText(tableCell.text());
}
}
}
}
}
} else {
List<Picture> allPictures = hwpfDocument.getPicturesTable().getAllPictures();
int d = 0;
for (int j = 0; j < paragraph.numCharacterRuns(); j++) {
CharacterRun run = paragraph.getCharacterRun(j);
Picture picture = hwpfDocument.getPicturesTable().extractPicture(run, false);
if (picture != null) {
byte[] pictureBytes = picture.getContent();
String pictureType = picture.getMimeType();
String fileName = picture.suggestFullFileName();
int pictureType1 = getPictureType(pictureType);
if (pictureType1 == 0) {
continue;
}
if (d > 0) {
continue;
}
InputStream inputStream = new ByteArrayInputStream(pictureBytes);
XWPFParagraph pictureParagraph = xwpfDocument.createParagraph();
XWPFRun pictureRun = pictureParagraph.createRun();
pictureRun.addPicture(inputStream, pictureType1, fileName, Units.toEMU(picture.getWidth()), Units.toEMU(picture.getHeight()));
// 重新设置字体和格式设置
int size = xwpfParagraph.getRuns().size();
if (size == 0) {
continue;
}
XWPFRun previousRun = xwpfParagraph.getRuns().get(size - 1);
pictureRun.setFontFamily(previousRun.getFontFamily());
pictureRun.setFontSize(previousRun.getFontSize());
pictureRun.setBold(previousRun.isBold());
pictureRun.setItalic(previousRun.isItalic());
// 可根据需要设置其他格式设置
xwpfParagraph.addRun(pictureRun);
d++;
} else {
XWPFRun xwpfRun = xwpfParagraph.createRun();
xwpfRun.setText(run.text());
}
}
}
}
hwpfDocument.close();
return xwpfDocument;
}
public static int getPictureType(String mimeType) {
if (mimeType.equals("image/jpeg")) {
return Document.PICTURE_TYPE_JPEG;
} else if (mimeType.equals("image/png")) {
return Document.PICTURE_TYPE_PNG;
} else if (mimeType.equals("image/gif")) {
return Document.PICTURE_TYPE_GIF;
} else if (mimeType.equals("image/bmp")) {
return Document.PICTURE_TYPE_BMP;
} else {
return 0;
//throw new RuntimeException("Unsupported picture: " + mimeType + ". Expected emf|wmf|pict|jpeg|png|dib|gif|tiff|eps|bmp|wpg");
}
}
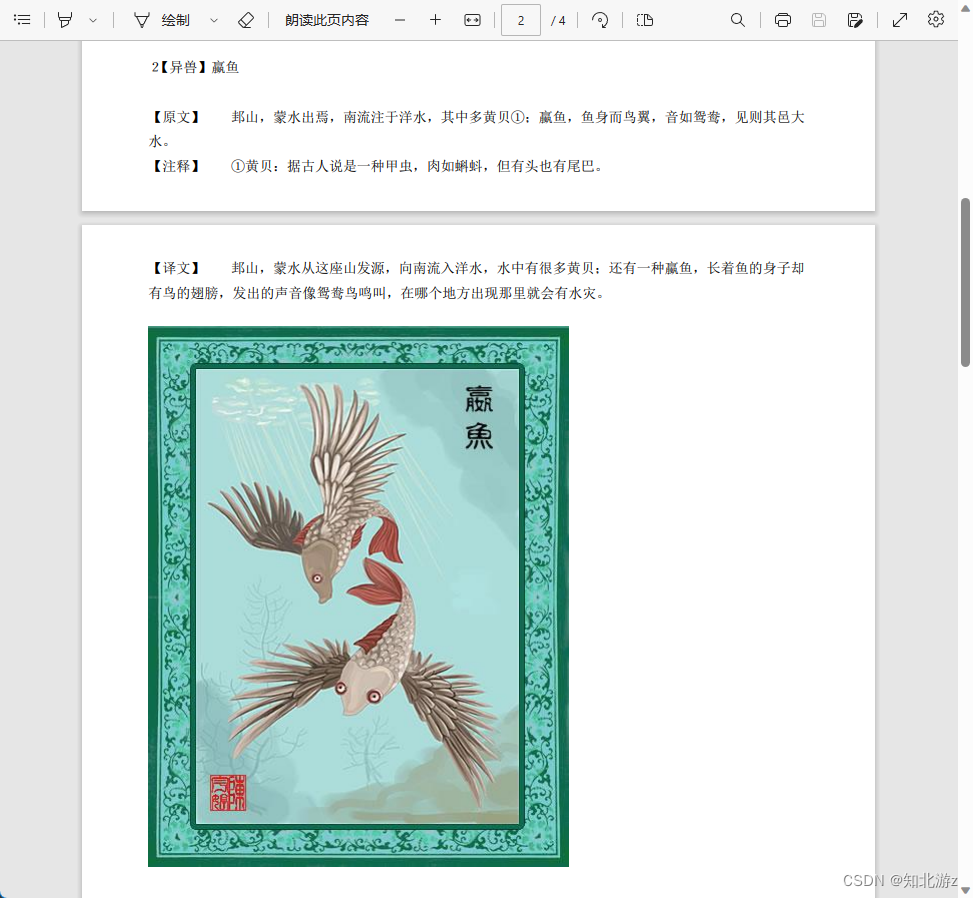
验证代码:
因为使用的是免费版,所以只能生成前三页。。。有超过三页需求的可以选择付费版本。
二、txt文件转pdf文件
txt文件转pdf文件代码直接复用word的即可
代码:
public static void txtToPdf(String txtPath, String pdfPath) throws Exception {
wordToPdf(txtPath, pdfPath);
}
验证代码:
public static void main(String[] args) throws Exception {
txtToPdf("D:\\书籍\\电子书\\国外名著\\君主论.txt", "D:\\test");
}
转换效果如下

三、PPT文件转pdf文件(支持ppt、pptx)
PPT文件转pdf文件,听说你们公司不让用ppt,那就让我们把ppt转成pdf再用吧。其实从这里开始代码就开始复杂起来了,这里用到了Apache poi、itextpdf、Graphics2D三个库,于是我结合这三个库同时兼容ppt、pptx写出了第一版代码
ppt转pdf第一版代码
public static void pptToPdf(String pptPath, String pdfPath) throws IOException {
pdfPath = FileUtil.getNewFileFullPath(pptPath, pdfPath, "pdf");
com.itextpdf.text.Document document = null;
FileOutputStream fileOutputStream = null;
PdfWriter pdfWriter = null;
try {
InputStream inputStream = Files.newInputStream(Paths.get(pptPath));
SlideShow<?, ?> slideShow;
String ext = pptPath.substring(pptPath.lastIndexOf("."));
if (ext.equals(".pptx")) {
slideShow = new XMLSlideShow(inputStream);
} else {
slideShow = new HSLFSlideShow(inputStream);
}
Dimension dimension = slideShow.getPageSize();
fileOutputStream = new FileOutputStream(pdfPath);
//document = new com.itextpdf.text.Document(new com.itextpdf.text.Rectangle((float) dimension.getWidth(), (float) dimension.getHeight()));
document = new com.itextpdf.text.Document();
pdfWriter = PdfWriter.getInstance(document, fileOutputStream);
document.open();
for (Slide<?, ?> slide : slideShow.getSlides()) {
// 设置字体, 解决中文乱码
setPPTFont(slide, "宋体");
BufferedImage bufferedImage = new BufferedImage((int) dimension.getWidth(), (int) dimension.getHeight(), BufferedImage.TYPE_INT_RGB);
Graphics2D graphics2d = bufferedImage.createGraphics();
graphics2d.setPaint(Color.white);
graphics2d.setFont(new java.awt.Font("宋体", java.awt.Font.PLAIN, 12));
slide.draw(graphics2d);
graphics2d.dispose();
com.itextpdf.text.Image image = com.itextpdf.text.Image.getInstance(bufferedImage, null);
image.scaleToFit((float) dimension.getWidth(), (float) dimension.getHeight());
document.add(image);
document.newPage();
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (document != null) {
document.close();
}
if (fileOutputStream != null) {
fileOutputStream.close();
}
if (pdfWriter != null) {
pdfWriter.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
private static void setPPTFont(Slide<?, ?> slide, String fontFamily) {
// 设置字体, 解决中文乱码
for (Shape<?, ?> shape : slide.getShapes()) {
if (shape instanceof TextShape) {
TextShape textShape = (TextShape) shape;
List<TextParagraph> textParagraphs = textShape.getTextParagraphs();
for (TextParagraph textParagraph : textParagraphs) {
List<TextRun> textRuns = textParagraph.getTextRuns();
for (TextRun textRun : textRuns) {
textRun.setFontFamily(fontFamily);
}
}
}
}
}
验证代码:
public static void main(String[] args) throws Exception {
pptToPdf("C:\\Users\\jie\\Desktop\\预览\\web\\files\\河西走廊见闻录.pptx", "D:\\test");
}
转换效果如下
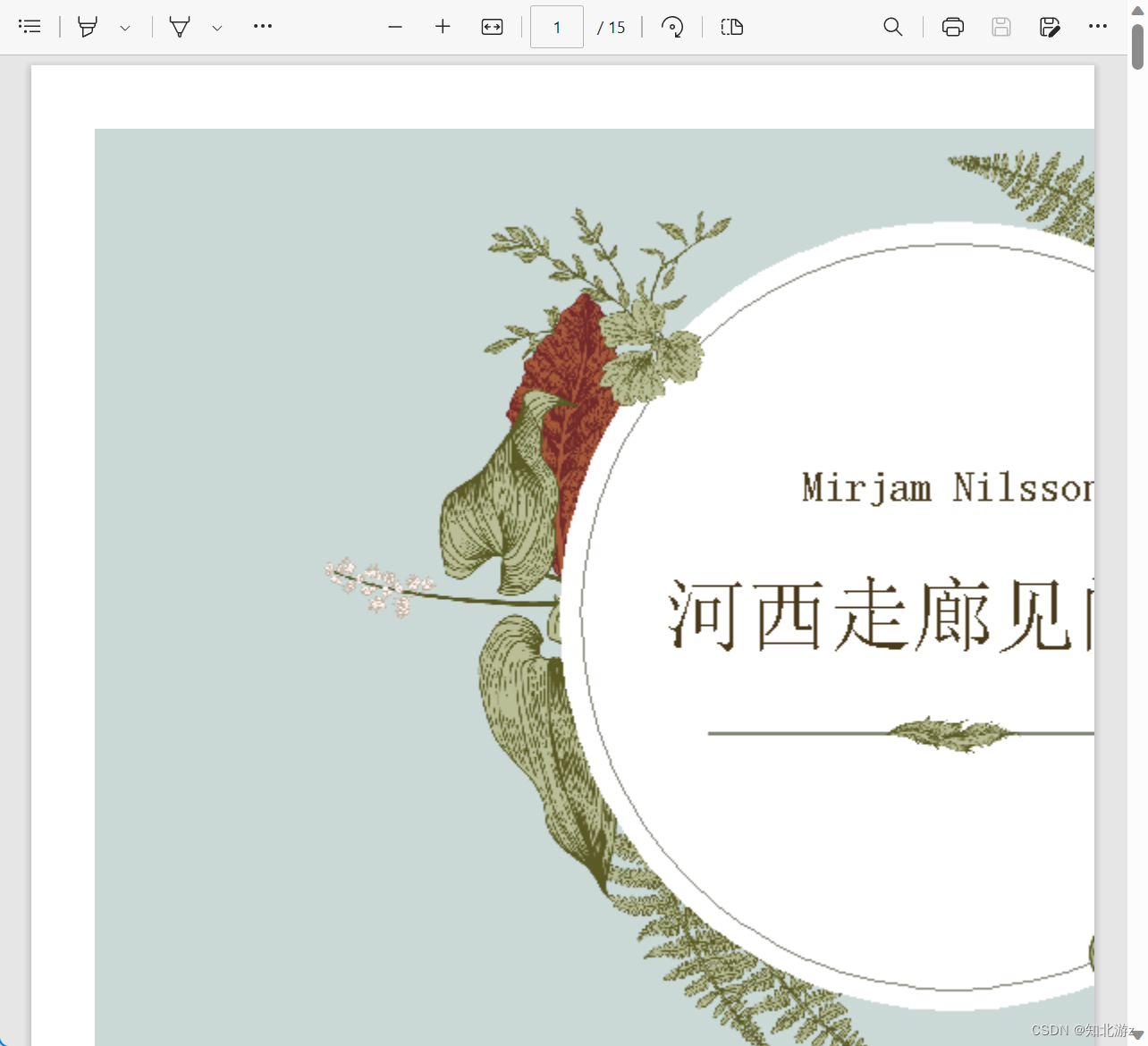
可以看到转换效果并不怎么好,ppt的内容展示不全。于是我开始在网上找解决方案,结果找到了一个很神奇的解决方案,就绘制的图片先写在一个PdfPTable对象上,再把PdfPTable对象放到document离去,于是我根据这个改了改代码写出了第二版代码
ppt转pdf第二版代码
public static void pptToPdf(String pptPath, String pdfPath) throws IOException {
pdfPath = FileUtil.getNewFileFullPath(pptPath, pdfPath, "pdf");
com.itextpdf.text.Document document = null;
FileOutputStream fileOutputStream = null;
PdfWriter pdfWriter = null;
try {
InputStream inputStream = Files.newInputStream(Paths.get(pptPath));
SlideShow<?, ?> slideShow;
String ext = pptPath.substring(pptPath.lastIndexOf("."));
if (ext.equals(".pptx")) {
slideShow = new XMLSlideShow(inputStream);
} else {
slideShow = new HSLFSlideShow(inputStream);
}
Dimension dimension = slideShow.getPageSize();
fileOutputStream = new FileOutputStream(pdfPath);
//document = new com.itextpdf.text.Document(new com.itextpdf.text.Rectangle((float) dimension.getWidth(), (float) dimension.getHeight()));
document = new com.itextpdf.text.Document();
pdfWriter = PdfWriter.getInstance(document, fileOutputStream);
document.open();
PdfPTable pdfPTable = new PdfPTable(1);
for (Slide<?, ?> slide : slideShow.getSlides()) {
// 设置字体, 解决中文乱码
setPPTFont(slide, "宋体");
BufferedImage bufferedImage = new BufferedImage((int) dimension.getWidth(), (int) dimension.getHeight(), BufferedImage.TYPE_INT_RGB);
Graphics2D graphics2d = bufferedImage.createGraphics();
graphics2d.setPaint(Color.white);
graphics2d.setFont(new java.awt.Font("宋体", java.awt.Font.PLAIN, 12));
slide.draw(graphics2d);
graphics2d.dispose();
com.itextpdf.text.Image image = com.itextpdf.text.Image.getInstance(bufferedImage, null);
image.scaleToFit((float) dimension.getWidth(), (float) dimension.getHeight());
// 写入单元格
pdfPTable.addCell(new PdfPCell(image, true));
document.add(pdfPTable);
pdfPTable.deleteBodyRows();
document.newPage();
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (document != null) {
document.close();
}
if (fileOutputStream != null) {
fileOutputStream.close();
}
if (pdfWriter != null) {
pdfWriter.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
转换效果如下

可以看到ppt内容已经展示完整了,到此其实ppt转pdf功能已经基本实现了,但是显示效果依然不算完美毕竟我们其实想要的是在pdf里和在ppt看的是一样的效果,而且每页ppt的长宽其实都是一样的,所以我就在想能不能设置pdf每页的长宽,把pdf每页的长宽设置成和ppt的长宽一样。于是我开始看初始化pdf document的源码配置
com.itextpdf.text.Document document = new com.itextpdf.text.Document();
然后发现com.itextpdf.text.Document除了默认的构造函数外还有这这样一个构造函数:
public Document(Rectangle pageSize) {
this(pageSize, 36.0F, 36.0F, 36.0F, 36.0F);
}
然后com.itextpdf.text.Rectangle类点进去就发现了可以设置长宽的构造函数:
public Rectangle(float urx, float ury) {
this(0.0F, 0.0F, urx, ury);
}
于是我代码中的初始化Document进行如下调整(根据第一版代码改,第二版的PdfPTable可以不用了)
document = new com.itextpdf.text.Document();
//改成如下
document = new com.itextpdf.text.Document(new com.itextpdf.text.Rectangle((float) dimension.getWidth(), (float) dimension.getHeight()));
ppt转pdf第三版代码(最终版)
public void pptToPdf(String pptPath, String pdfPath) throws IOException, DocumentException {
List<BufferedImage> images = pptToBufferedImages(pptPath);
if(CollectionUtils.isEmpty(images)){
return;
}
pdfPath = FileUtil.getNewFileFullPath(pptPath, pdfPath, "pdf");
try (FileOutputStream fileOutputStream = new FileOutputStream(pdfPath)){
BufferedImage firstImage = images.get(0);
com.itextpdf.text.Rectangle rectangle = new com.itextpdf.text.Rectangle((float) firstImage.getWidth(), (float) firstImage.getHeight());
com.itextpdf.text.Document document = new com.itextpdf.text.Document(rectangle, 0, 0, 0, 0);
PdfWriter pdfWriter = PdfWriter.getInstance(document, fileOutputStream);
document.open();
for (BufferedImage bufferedImage : images) {
com.itextpdf.text.Image image = com.itextpdf.text.Image.getInstance(bufferedImage, null);
//image.scaleToFit((float) image.getWidth(), (float) image.getHeight());
document.add(image);
document.newPage();
}
document.close();
pdfWriter.close();
}
}
private static List<BufferedImage> pptToBufferedImages(String pptPath) {
List<BufferedImage> images = new ArrayList<>();
try (SlideShow<?, ?> slideShow = SlideShowFactory.create(new File(pptPath));) {
Dimension dimension = slideShow.getPageSize();
for (Slide<?, ?> slide : slideShow.getSlides()) {
// 设置字体, 解决中文乱码
setPPTFont(slide, "宋体");
BufferedImage bufferedImage = new BufferedImage((int) dimension.getWidth(), (int) dimension.getHeight(), BufferedImage.TYPE_INT_RGB);
Graphics2D graphics2d = bufferedImage.createGraphics();
graphics2d.setPaint(Color.white);
graphics2d.setFont(new java.awt.Font("宋体", java.awt.Font.PLAIN, 12));
slide.draw(graphics2d);
graphics2d.dispose();
images.add(bufferedImage);
}
return images;
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
//设置ppt字体
private static void setPPTFont(Slide<?, ?> slide, String fontFamily) {
// 设置字体, 解决中文乱码
for (Shape<?, ?> shape : slide.getShapes()) {
if (shape instanceof TextShape) {
TextShape textShape = (TextShape) shape;
List<TextParagraph> textParagraphs = textShape.getTextParagraphs();
for (TextParagraph textParagraph : textParagraphs) {
List<TextRun> textRuns = textParagraph.getTextRuns();
for (TextRun textRun : textRuns) {
textRun.setFontFamily(fontFamily);
}
}
}
}
}
转换效果如下
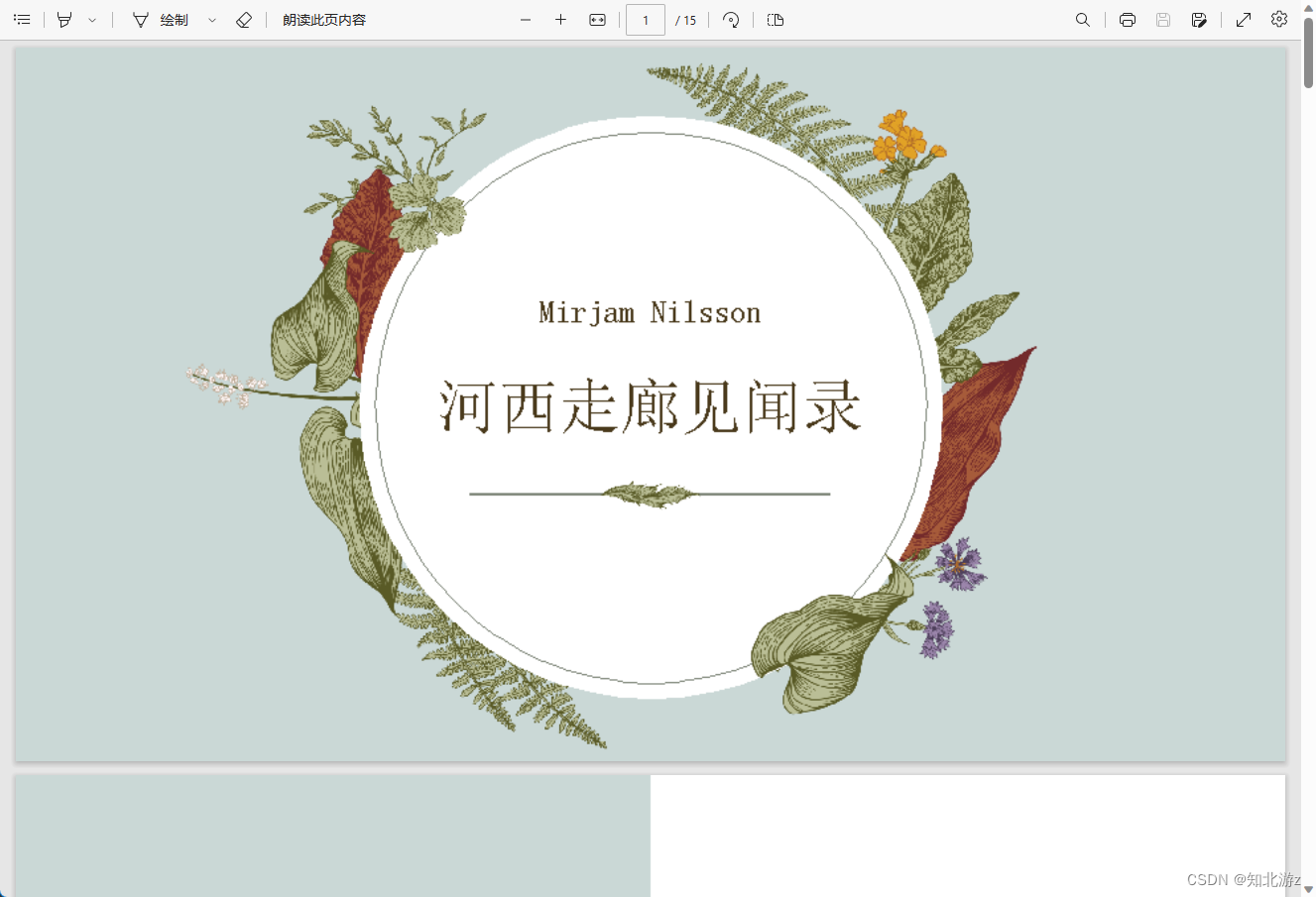
现在展示的效果已经和ppt上一样了,而且经过验证ppt和pptx都是可以转换成功的。
四、图片转pdf文件
图片转pdf用到了用到了Apache poi、itextpdf两个库,因为itextpdf支持解析的图片有限,点开c读取图片的方法com.itextpdf.text.Image.getInstance,我们可以看到这样一段源码:
Image img;
if (c1 == 71 && c2 == 73 && c3 == 70) {
GifImage gif = new GifImage(url);
img = gif.getImage(1);
img = img;
return img;
}
if (c1 == 255 && c2 == 216) {
Jpeg var39 = new Jpeg(url);
return var39;
}
Jpeg2000 var38;
if (c1 == 0 && c2 == 0 && c3 == 0 && c4 == 12) {
var38 = new Jpeg2000(url);
return var38;
}
if (c1 == 255 && c2 == 79 && c3 == 255 && c4 == 81) {
var38 = new Jpeg2000(url);
return var38;
}
if (c1 == PngImage.PNGID[0] && c2 == PngImage.PNGID[1] && c3 == PngImage.PNGID[2] && c4 == PngImage.PNGID[3]) {
var12 = PngImage.getImage(url);
return var12;
}
if (c1 == 215 && c2 == 205) {
ImgWMF var37 = new ImgWMF(url);
return var37;
}
if (c1 != 66 || c2 != 77) {
RandomAccessFileOrArray ra;
String file;
if (c1 == 77 && c2 == 77 && c3 == 0 && c4 == 42 || c1 == 73 && c2 == 73 && c3 == 42 && c4 == 0) {
ra = null;
try {
if (url.getProtocol().equals("file")) {
file = url.getFile();
file = Utilities.unEscapeURL(file);
ra = new RandomAccessFileOrArray(randomAccessSourceFactory.createBestSource(file));
} else {
ra = new RandomAccessFileOrArray(randomAccessSourceFactory.createSource(url));
}
img = TiffImage.getTiffImage(ra, 1);
img.url = url;
img = img;
return img;
} catch (RuntimeException var32) {
if (recoverFromImageError) {
img = TiffImage.getTiffImage(ra, recoverFromImageError, 1);
img.url = url;
Image var15 = img;
return var15;
}
throw var32;
} finally {
if (ra != null) {
ra.close();
}
}
}
if (c1 == 151 && c2 == 74 && c3 == 66 && c4 == 50 && c5 == 13 && c6 == 10 && c7 == 26 && c8 == 10) {
ra = null;
try {
if (url.getProtocol().equals("file")) {
file = url.getFile();
file = Utilities.unEscapeURL(file);
ra = new RandomAccessFileOrArray(randomAccessSourceFactory.createBestSource(file));
} else {
ra = new RandomAccessFileOrArray(randomAccessSourceFactory.createSource(url));
}
img = JBIG2Image.getJbig2Image(ra, 1);
img.url = url;
img = img;
return img;
} finally {
if (ra != null) {
ra.close();
}
}
}
由此可以可知itextpdf支持解析的图片只有gif、jpeg、png、bmp、wmf、tiff、 jbig2这几种,这些其实已经基本包含了所有主流的图片格式(百度图片:所以我用的webp格式是非主流格式?),而且图片格式不是光改后缀就行的,必须要用格式转换器转换。比如下面这张图虽然后缀是jpeg,但通过查看图片信息可知实际格式是webg格式itextpdf一样无法解析
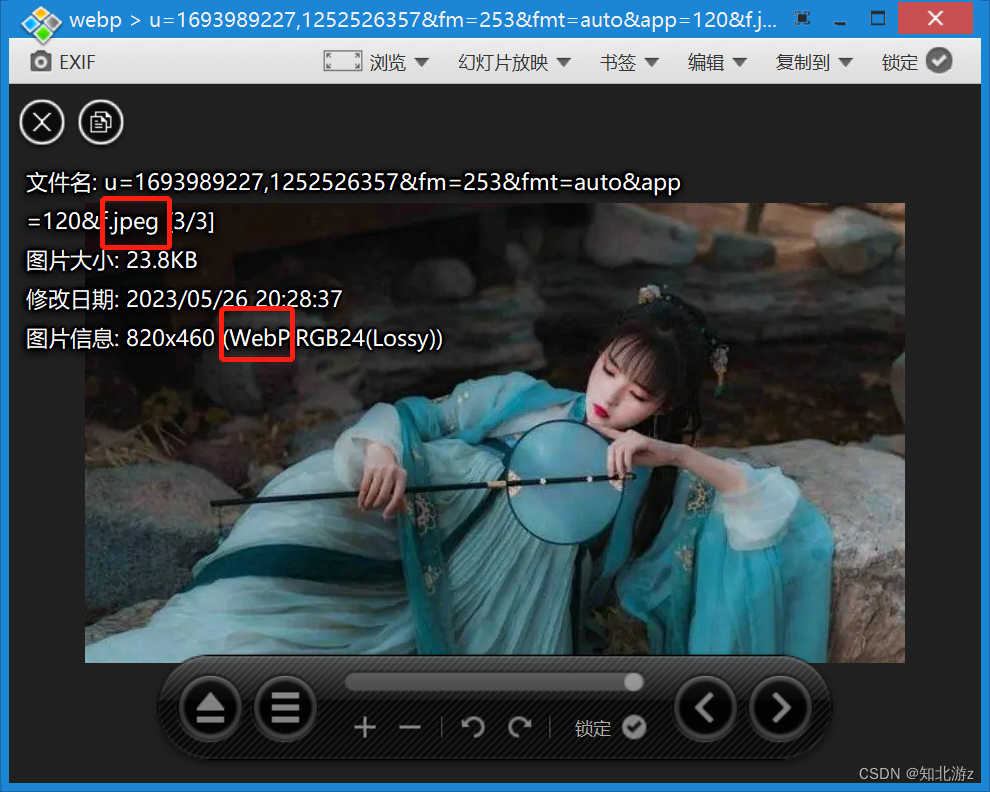
话不多说我们先结合Apache poi、itextpdf两个库简单协议版基本的图片转换pdf代码
单图片转pdf第一版代码
public static void imageToPdf(String imgPath, String pdfPath) throws Exception {
pdfPath = FileUtil.getNewFileFullPath(imgPath, pdfPath, "pdf");
com.itextpdf.text.Document document = new com.itextpdf.text.Document();
PdfWriter.getInstance(document, Files.newOutputStream(Paths.get(pdfPath)));
document.open();
com.itextpdf.text.Image image = com.itextpdf.text.Image.getInstance(imgPath);
image.setAlignment(com.itextpdf.text.Image.ALIGN_CENTER);
document.add(image);
document.close();
}
验证代码:
public static void main(String[] args) throws Exception {
imageToPdf("D:\\picture\\美女\\aa37a7be4196c07f43a3f776801d1b46.jpg", "D:\\test");
}
转换效果如下
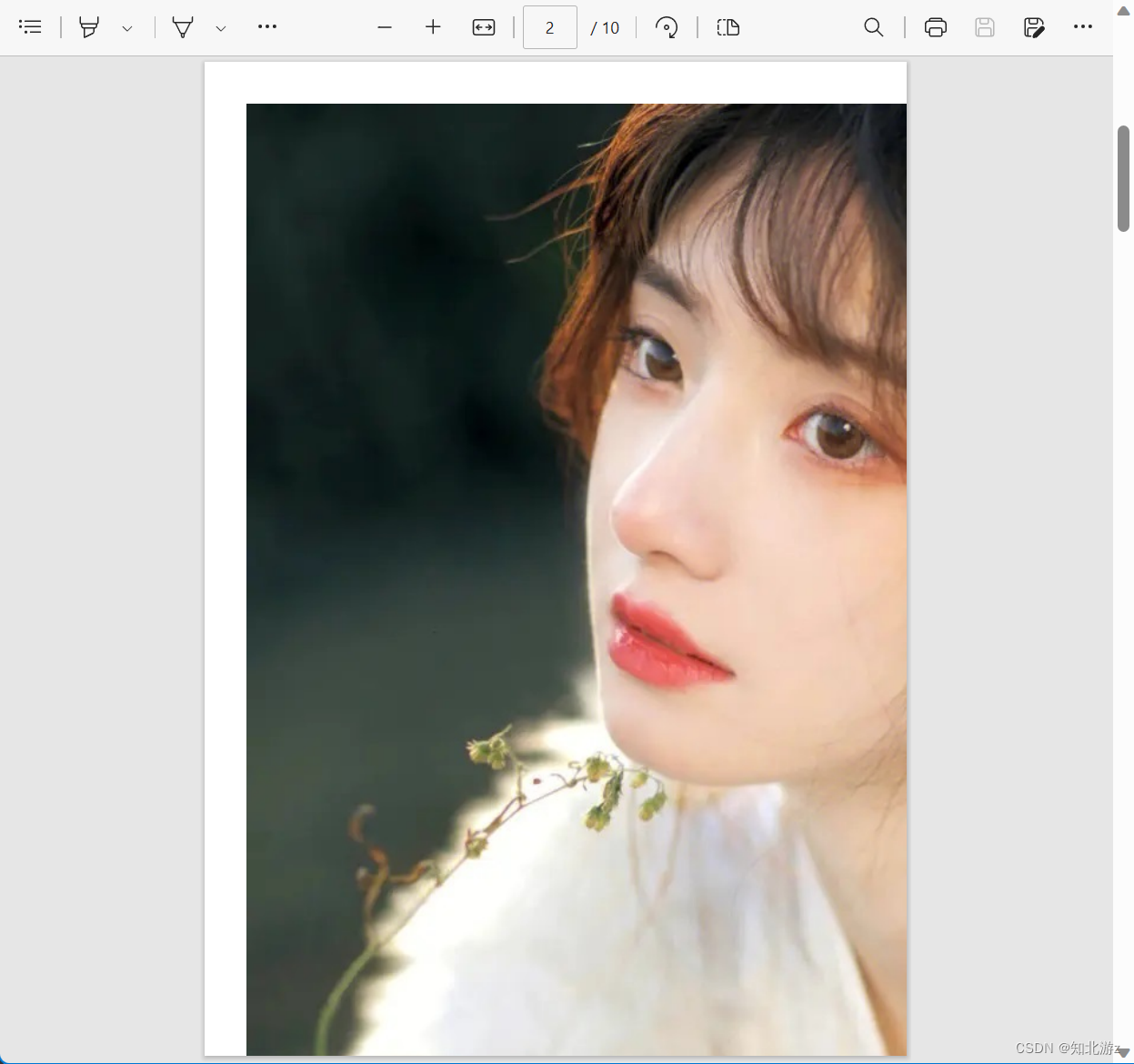
从效果可以我们可以看到这个图片其实是没有显示完全的, 其实小一点的图片是没什么问题的,但是因为pdf设置的每页都是A4大小,所以在图片过大时会显示不完整,所以我们在图片过大时需要对图片进行一些调整,调整后的代码如下:
单图片转pdf第二版代码
public static void imageToPdf(String imgPath, String pdfPath) throws Exception {
pdfPath = FileUtil.getNewFileFullPath(imgPath, pdfPath, "pdf");
com.itextpdf.text.Document document = new com.itextpdf.text.Document();
PdfWriter.getInstance(document, Files.newOutputStream(Paths.get(pdfPath)));
document.open();
com.itextpdf.text.Image image = com.itextpdf.text.Image.getInstance(imgPath);
float width = image.getWidth();
float height = image.getHeight();
float space = 50f;
if (width > PageSize.A4.getWidth() - space || height > PageSize.A4.getHeight() - space) {
image.scaleToFit(PageSize.A4.getWidth() - space, PageSize.A4.getHeight() - space);
}
image.setAlignment(com.itextpdf.text.Image.ALIGN_CENTER);
document.add(image);
document.close();
}
转换效果如下
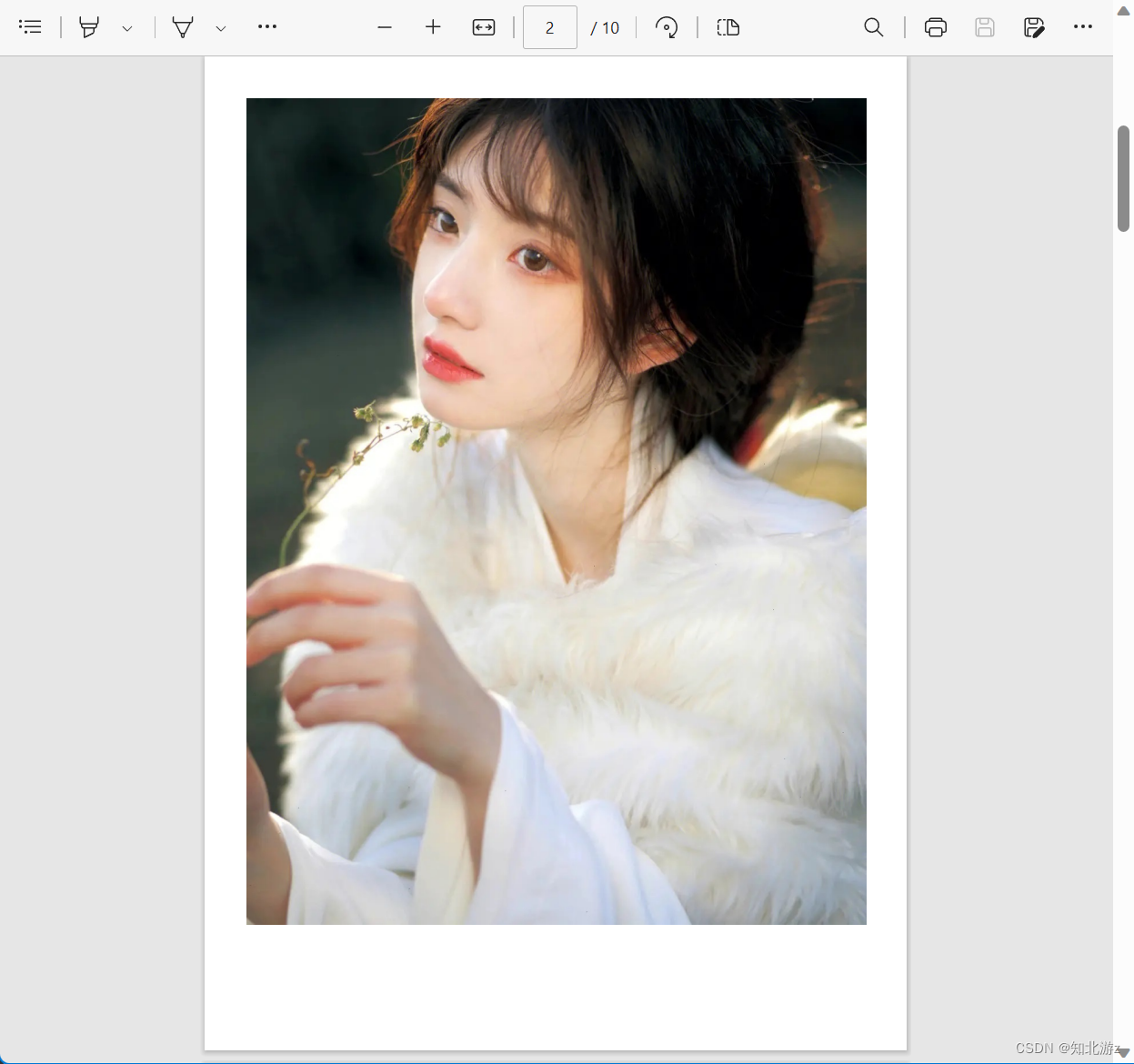
可以看到现在图片已经完整的显示在pdf的页面中了,到这里你可能会有一个疑惑,为什么这次不想上面ppt转换pdf一样把pdf的页面长宽设置成和图片一样,而且去调整图片的大小呢。之所以这样做的原因是因为在接下来的多图片转换成一个pdf文件时,往往是不能确保每张图片的长宽比例是一样的,为了确保每张图片都能完整的显示,所以只能调整图片的大小。
将文件夹下的所有图片导成一个pdf
将图片一张一张的导成pdf毕竟很麻烦,比如我一个文件夹下面有很多张图片,我想将该文件夹下的所有图片都导入pdf中做个《美人谱》,我该怎么做呢?安排!于是代码调整成了下面这样
支持多图片转pdf代码:
public static void imageToPdf(String imagePath, String pdfPath) throws Exception {
pdfPath = FileUtil.getNewFileFullPath(imagePath, pdfPath, "pdf");
File imageFile = new File(imagePath);
File[] files;
if (imageFile.isDirectory()) {
files = imageFile.listFiles();
} else {
files = new File[]{imageFile};
}
imageToPdf(files, pdfPath);
}
public static void imageToPdf(File[] imageFiles, String pdfPath) throws Exception {
com.itextpdf.text.Document document = new com.itextpdf.text.Document();
PdfWriter.getInstance(document, Files.newOutputStream(Paths.get(pdfPath)));
document.open();
for (File file : imageFiles) {
if (file.isFile() && FileUtil.isImage(file)) {
try {
com.itextpdf.text.Image image = com.itextpdf.text.Image.getInstance(file.getAbsolutePath());
float width = image.getWidth();
float height = image.getHeight();
float space = 10f;
if (width > PageSize.A4.getWidth() - space || height > PageSize.A4.getHeight() - space) {
image.scaleToFit(PageSize.A4.getWidth() - space, PageSize.A4.getHeight() - space);
}
image.setAlignment(com.itextpdf.text.Image.ALIGN_CENTER);
//document.setMargins(50, 150, 50, 50);
//document.setPageSize(new com.itextpdf.text.Rectangle(width, height));
document.newPage();
document.add(image);
} catch (Exception e) {
logger.error("图片转换失败", e);
}
}
}
document.close();
}
验证代码:
public static void main(String[] args) throws Exception {
imageToPdf("D:\\picture\\美女", "D:\\test\\美人谱.pdf");
}
转换效果如下
五、excel文件转pdf文件
其实excel转pdf在实际的应用场景中应该比较罕见,但是前面也说了这么多文件转pdf的方式了,那excel转pdf也就一并说说吧。
1、 使用itextpdf方式
代码如下:
public static void excelToPdf(String excelPath, String pdfPath) throws DocumentException, IOException {
pdfPath = FileUtil.getNewFileFullPath(excelPath, pdfPath, "pdf");
try (Workbook workbook = WorkbookFactory.create(new File(excelPath))) {
com.itextpdf.text.Document document = new com.itextpdf.text.Document();
PdfWriter.getInstance(document, new FileOutputStream(pdfPath));
document.open();
BaseFont chineseFont = BaseFont.createFont("STSong-Light", "UniGB-UCS2-H", BaseFont.NOT_EMBEDDED);
Font font = new Font(chineseFont, 12, Font.NORMAL);
DecimalFormat df = new DecimalFormat("#");
for (Sheet sheet : workbook) {
PdfPTable table = new PdfPTable(sheet.getRow(0).getPhysicalNumberOfCells());
for (Row row : sheet) {
for (Cell cell : row) {
if (cell.getCellType() == CellType.NUMERIC) {
PdfPCell pdfPCell = new PdfPCell(new Paragraph(df.format(cell.getNumericCellValue()), font));
table.addCell(pdfPCell);
} else {
PdfPCell pdfPCell = new PdfPCell(new Paragraph(cell.toString(), font));
table.addCell(pdfPCell);
}
}
}
table.setHeaderRows(1);
document.add(table);
}
document.close();
}
}
验证代码:
public static void main(String[] args) throws Exception {
excelToPdf("C:\\Users\\jie\\Desktop\\新建 Microsoft Excel 工作表.xlsx", "D:\\test");
}
转换效果如下

2、 使用spiref方式
因为spire不在maven中央仓库里以及阿里云的maven仓库中,所以在使用spire之前需要现在maven中配置新的maven仓库地址,配置如下;
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.cn/repository/maven-public/</url>
</repository>
</repositories>
然后再pom中引入依赖:
收费:
<groupId>e-iceblue</groupId>
<artifactId>spire.office</artifactId>
<version>5.3.1</version>
</dependency>
或者 免费的:
<groupId>e-iceblue</groupId>
<artifactId>spire.office.free</artifactId>
<version>5.3.1</version>
</dependency>
免费版本基础功能都能用
代码:
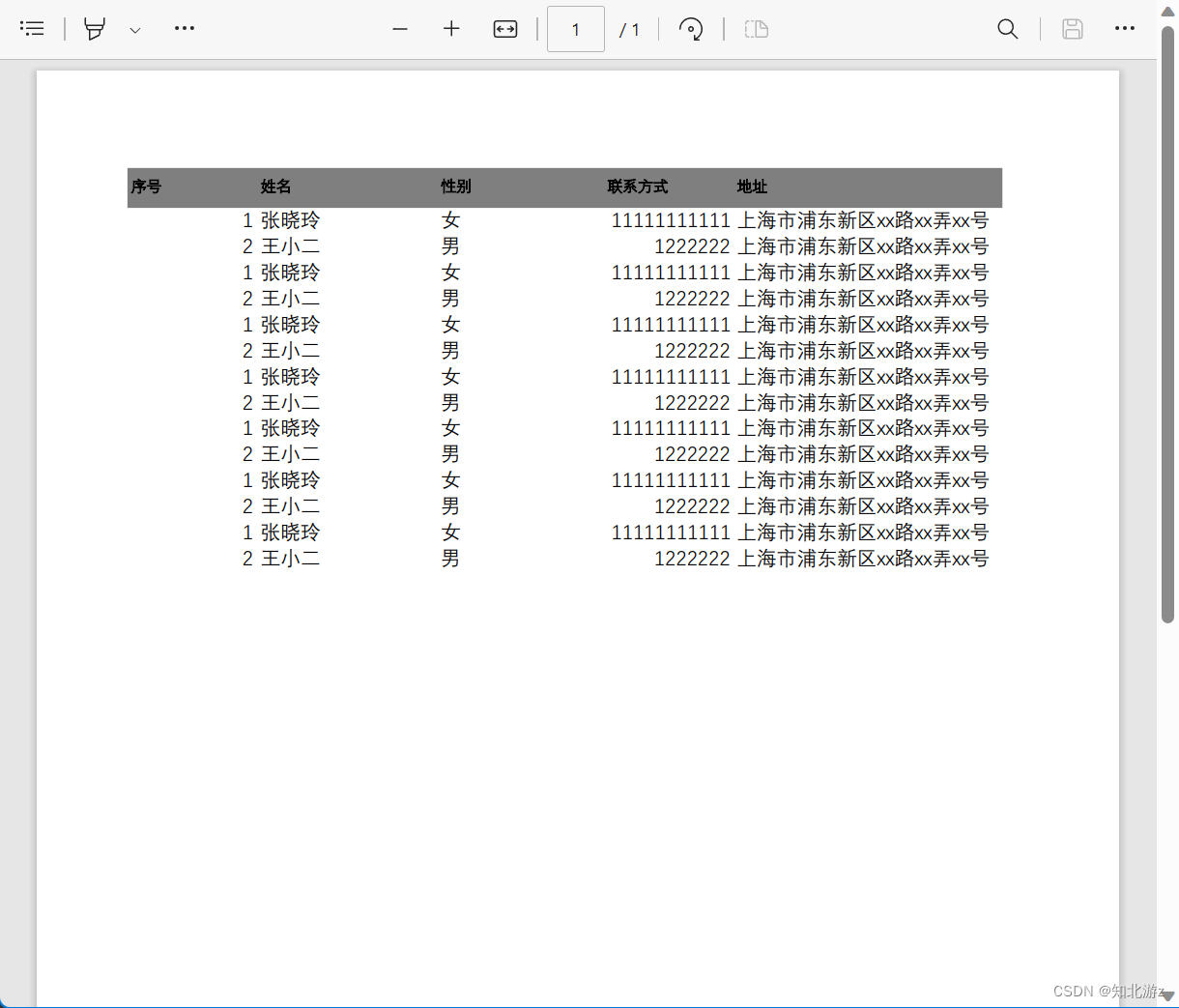
public static void excelToPdf2(String excelPath, String pdfPath) throws DocumentException, IOException, InvalidFormatException {
pdfPath = FileUtil.getNewFileFullPath(excelPath, pdfPath, "pdf");
com.spire.xls.Workbook wb = new com.spire.xls.Workbook();
wb.loadFromFile(excelPath);
wb.saveToFile(pdfPath, com.spire.xls.FileFormat.PDF);
}
验证代码:
public static void main(String[] args) throws Exception {
excelToPdf2("C:\\Users\\jie\\Desktop\\新建 Microsoft Excel 工作表.xlsx", "D:\\test");
}
转换效果如下
六、使用Libreoffice转换word/excel/ppt等文件到pdf
1、安装Libreoffice
1.1 windows:直接下载Libreoffice
下载 LibreOffice | LibreOffice 简体中文官方网站 - 自由免费的办公套件
1.2 centos:使用yum安装:
yum install -y libreoffice
1.3 alpine:使用apk安装:
apk add libreoffice
其他操作系统可以参考官方安装说明或自行搜索安装方法。
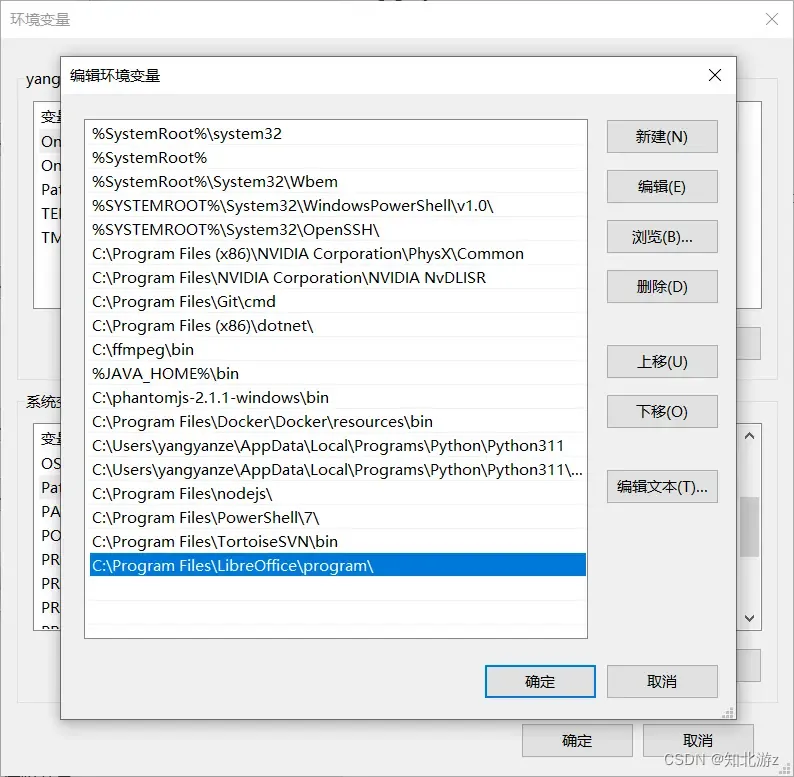
注意,windows在安装完成之后,找到libreoffice安装目录,将对应目录加入PATH参数,一般安装位置在C:\Program Files\LibreOffice\program,添加入PATH和JDK添加PATH一样的操作:
2、Libreoffice转换Office到PDF的命令
soffice --invisible --convert-to pdf --outdir "输出文件夹" "PDF文件所在位置"
3、java代码
添加Commons-exec依赖:
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-exec</artifactId>
<version>${commons-exec.version}</version>
</dependency>
进行转换:
public static File convert(File officeFile) throws Exception {
DefaultExecutor exec = new DefaultExecutor();
File tempFolder = new File(System.getProperty("java.io.tmpdir"), "office2pdf-" + UUID.randomUUID());
// 同步等待
Semaphore semaphore = new Semaphore(1);
semaphore.acquire();
ExecuteResultHandler erh = new ExecuteResultHandler() {
@Override
public void onProcessComplete(int i) {
semaphore.release();
//转换完成逻辑
}
@Override
public void onProcessFailed(ExecuteException e) {
semaphore.release();
//转换失败逻辑
e.printStackTrace();
}
};
String command = "soffice --invisible --convert-to pdf --outdir \"" + tempFolder.getAbsolutePath() + "\" \"" + officeFile.getAbsolutePath() + "\"";
System.out.println("执行office文件转换任务,命令为" + command);
exec.execute(CommandLine.parse(command), erh);
// 等待执行完成
semaphore.acquire();
File file = new File(tempFolder.getAbsolutePath() + File.separator + officeFile.getName().substring(0, officeFile.getName().indexOf(".")) + ".pdf");
if (!file.exists()) {
// 转换失败逻辑
}
return file;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号