

t_sql中的COUNT函数
1 count函数的定义
count函数的定义可见MSDN。定义如下:
1 | COUNT ( { [ [ ALL | DISTINCT ] expression ] | * } ) |
1 | 那么COUNT 有两种使用方式COUNT(expression)和COUNT(*),它返回一个对一个表按某列计数的值。 |
- 1
COUNT(*)返回表的行数。它不会过滤null和重复的行。 - 1
COUNT(expression)会过滤掉null值,所以值null行不会加入到计数当中,但如果不在expression前面加上distinct关键字,它是会过滤掉重复行的。
1 | 以此可以得出一个结论:count(*)返回值总是大于或等于count(expression)的返回值。 |
1 | 在应用中,好多人喜欢使用COUNT(1),这里面的1其实就是一个expression,因为你的表中没有列名为1的列,那么它的返回结果是和COUNT(*)一模一样的, |
1 | 个人觉得效率也是没有差别的。 |
1 2 3 4 5 6 7 | ;WITH cte1(c1,c2, Description) AS( SELECT 1, 1, 'This is a fox' UNION ALL SELECT 2, NULL, 'Firefox' UNION All SELECT NULL, 2, 'People consider foxes as clever but sly animals' UNION All SELECT NULL, NULL, NULL UNION ALL SELECT 3, NULL, 'This is me' UNION ALL SELECT 3, 3, 'Fox on the run') |
结果如下:

如结果所示,COUNT(*),COUNT(2)和COUNT(3)是一模一样的。而COUNT(c1)显然过滤掉了NULL值。
注意,COUNT 的参数expression可以为常量(像上面的2,3…),表的列,函数,还可以是语句,具体可见MSDN的定义。下面展示了这个应用。
如果想为cte1中列Description中有字符串'fox’进行计数,典型的做法是:
1 2 | SELECT COUNT(*) FROM cte1WHERE PATINDEX('%fox%',cte1.Description) <> 0 |
这种做法是where中过滤,另外一种方式是在expression中定义查找条件:
1 2 | SELECT COUNT(NULLIF(PATINDEX('%fox%', cte1.Description), 0))FROM cte1 |
如果description列中没有字符串'fox'那么PATINDEX函数返回的是0,NULLIF函数因为两个参数相等,那么结果是NULL,因为NULL不会参与计数,所以列中没有'fox’的行不会
参与计数,达到了查找的目的。
当然,我们还可在expression中使用case表达式:
1 2 3 4 | SELECT COUNT(CASE WHEN PATINDEX('%fox%',cte1.Description) <> 0 THEN 1 ELSE <strong>NULL</strong> END)FROM cte1 |
注意ELSE语句后面必须是NULL,如果是非NULL,ELSE语句也会参与COUNT计数的。
2 在count函数后接聚合窗口函数OVER。注意聚合窗口函数中是不能有ORDER BY,ORDER BY只能出现在排名函数的over子句中。OVER字句的定义见MSDN。
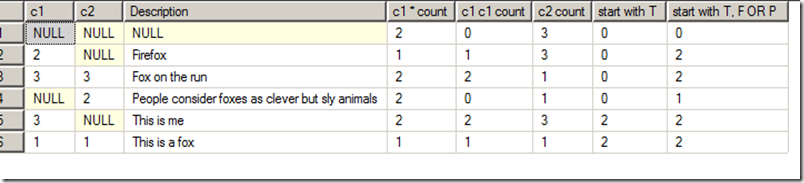
1 2 3 4 5 6 7 8 9 10 | SELECT c.*, COUNT(*) OVER(PARTITION BY c.c1) 'c1 * count', COUNT(c1) OVER(PARTITION BY c.c1) 'c1 c1 count', COUNT(*) OVER(PARTITION BY c.c2) 'c2 count', COUNT(CASE WHEN LEFT(c.Description, 1) IN ('T') THEN 1 ELSE NULL END) OVER(PARTITION BY LEFT(c.Description, 1)) 'start with T', COUNT(CASE WHEN LEFT(c.Description, 1) IN ('T', 'F', 'P') THEN 1 ELSE NULL END) OVER(PARTITION BY LEFT(c.Description, 1)) 'start with T, F OR P'FROM cte1 c |
1 | 注意OVER字句不能为OVER(PARTITION BY c.c1 ORDER BY c.c1),这是因为count不是排名函数。 |
1 | 以上的运行结果为: |
1 | <a href="http://images.cnblogs.com/cnblogs_com/fgynew/WindowsLiveWriter/t_sqlcount_11359/result333_4.png"><img style="border: 0; display: inline" title="result333" border="0" alt="result333" src="https://images.cnblogs.com/cnblogs_com/fgynew/WindowsLiveWriter/t_sqlcount_11359/result333_thumb_1.png" width="804" height="183"></a> |
可以看出,在使用OVER子句时候,COUNT还是遵循了最基本的准则,COUNT(*)会对null行计数,而COUNT(expression)则不会。
以上在COUNT 的expression中设置条件显然不是一种很优化的方式,因为这种方式会首先读取表中的所有数据,是对表进行扫描,而在where子句中设置条件进行过滤是一种很好的方式。因为从逻辑上讲,where先于select执行,所有数据库引擎只会读取部分数据,不是读取所有数据。如果要对以表中c1列的null进行统计,可以有两种方式:
1 2 3 | SELECT COUNT(*)FROM cte1WHERE c1 IS NULL |
或者:
1 2 3 4 | SELECT COUNT(CASE WHEN c1 IS NULL THEN 'x' ELSE NULL END)FROM cte1 |
最后看看执行计划的比较,后面的方式多了一个步骤(过滤):



{kind=link}
{kind=link}
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· .NET周刊【3月第1期 2025-03-02】
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· [AI/GPT/综述] AI Agent的设计模式综述