
【python】python分词和识别图像中的文字
#jieba分词
import jieba #全模式 word = jieba.cut("一人我饮酒醉 醉把佳人成双对 两眼 是独相随 我只求他日能双归", cut_all = True) print("Full Mode:" + "/ ".join(word)) #>>>Full Mode:一/ 人/ 我/ 饮酒/ 酒醉/ / / 醉/ 把/ 佳人/ 成双/ 对/ / / 两眼/ / / 是/ 独/ 相随/ / / 我/ 只求/ 他/ 日/ 能/ 双/ 归 #精确模式 word = jieba.cut("一人我饮酒醉 醉把佳人成双对 两眼 是独相随 我只求他日能双归", cut_all = False) print("Default Mode:" + '/ '.join(word)) #>>>Default Mode:一人/ 我/ 饮酒/ 醉/ / 醉/ 把/ 佳人/ 成双/ 对/ / 两眼/ / 是/ 独/ 相随/ / 我/ 只求/ 他/ 日/ 能/ 双归 #默认是精确模式 word = jieba.cut("一人我饮酒醉 醉把佳人成双对 两眼 是独相随 我只求他日能双归") print(", ".join(word)) #>>>一人, 我, 饮酒, 醉, , 醉, 把, 佳人, 成双, 对, , 两眼, , 是, 独, 相随, , 我, 只求, 他, 日, 能, 双归 #搜索引擎模式 word = jieba.cut_for_search("败帝王斗苍天夺得了皇位已成仙豪情万丈天地间我续写了另类帝王篇") print(", " .join(word)) #>>>败, 帝王, 斗, 苍天, 夺得, 了, 皇位, 已, 成仙, 豪情, 万丈, 豪情万丈, 天地, 天地间, 我, 续写, 了, 另类, 帝王, 篇
自定义词组
import jieba word = jieba.cut("一人我饮酒醉 醉把佳人成双对 两眼 是独相随 我只求他日能双归", cut_all = True) print("Full Mode:" + "/ ".join(word)) #>>>Full Mode:一/ 人/ 我/ 饮酒/ 酒醉/ / / 醉/ 把/ 佳人/ 成双/ 对/ / / 两眼/ / / 是/ 独/ 相随/ / / 我/ 只求/ 他/ 日/ 能/ 双/ 归 #自定义词组 jieba.add_word('一人我') word = jieba.cut("一人我饮酒醉 醉把佳人成双对 两眼 是独相随 我只求他日能双归", cut_all = True) print("Full Mode:" + "/ ".join(word)) #>>>Full Mode:一人我/ 饮酒/ 酒醉/ / / 醉/ 把/ 佳人/ 成双/ 对/ / / 两眼/ / / 是/ 独/ 相随/ / / 我/ 只求/ 他/ 日/ 能/ 双/ 归
词性标注
import jieba.posseg as pseg words = pseg.cut("我爱北京天安门") for word,flag in words: print('%s %s' % (word, flag)) #>>>我 r 爱 v 北京 ns 天安门 ns
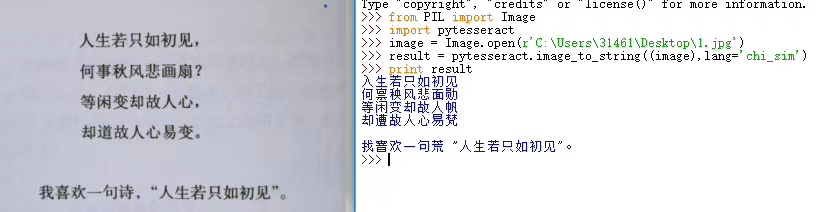
图像识别,由于识别不准确,后期需要训练,来使识别越来越准确

 浙公网安备 33010602011771号
浙公网安备 33010602011771号