

DataFrame.describe(percentiles=None, include=None, exclude=None)
其物理意义在于观察这一系列数据的范围。大小、波动趋势等等,便于判断后续对数据采取哪类模型更合适。
基础数据:
# 时间
dates = pd.date_range('20200115', periods=7)
# dn表格每个维度
df = pd.DataFrame(np.random.randn(7,5),index=dates,columns=list('ABCDa'))
df.to_excel(r'D:\自动化\web\unittest\DataTest1.xls',sheet_name='Sheet1') #数据输出至Excel

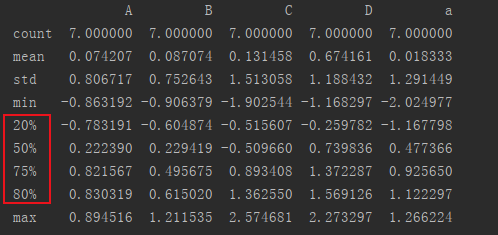
1.第一个percentiles,这个参数可以设定数值型特征的统计量,默认是[.25, .5, .75],也就是返回25%,50%,75%数据量时的数字,但是这个可以修改的,
df['Parch'].describe(percentiles=[.2,.75, .8])默认有5
2.第二个参数:include,这个参数默认是只计算数值型特征的统计量,当输入include=['O'],会计算离散型变量的统计特征,,
举个例子如下:
df.describe(include=‘O’)
df.describe(include=[‘O’])
缺图
df.describe(include=‘all’)
此外传参数是‘all’的时候会把数值型和离散型特征的统计都进行显示。
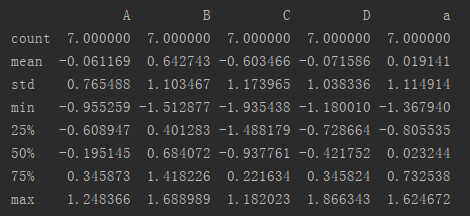
3.第三个参数的设计就更贴心了,第二个参数是你可以指定选那些,第三个参数就是你可以指定不选哪些,人性化设计。这个参数默认不丢弃任何列,相当于无影响。
综述,无法取指定行数,比如只取Min行
print(df.describe().iloc[3]) 暂时只能用这种方式
部分内容转https://blog.csdn.net/fang_qingyi/article/details/102649589
安知我所命也。初心不改,默默耕耘
