移位寄存器的设计
信号处理中,实现数据对齐时,常常对单bit或多bit信号进行打拍操作,这个可以通过移位寄存器实现,SLICEM中的SRL即为移位寄存器。
这里主要记录下不同写法的效果。
1 //同步复位 2 module static_multi_bit_sreg_poor #( 3 parameter DEPTH = 8 , 4 WIDTH = 1 5 ) 6 ( 7 input i_clk , 8 input i_rst , 9 input i_ce , 10 input [WIDTH-1:0] i_d , 11 output [WIDTH-1:0] o_d 12 ); 13 reg [WIDTH-1:0] ri_d [DEPTH]; 14 always @(posedge i_clk) begin 15 if(i_rst) begin 16 for(int i=0; i < DEPTH; i++) begin 17 ri_d[i] <= 'd0; 18 end 19 end 20 else if(i_ce)begin 21 ri_d[0] <= i_d; 22 for(int i=1; i < DEPTH; i++) begin 23 ri_d[i] <= ri_d[i-1]; 24 end 25 end 26 else 27 ri_d <= ri_d; 28 end 29 assign o_d = DEPTH==0 ? i_d : ri_d[WIDTH-1]; 30 endmodule
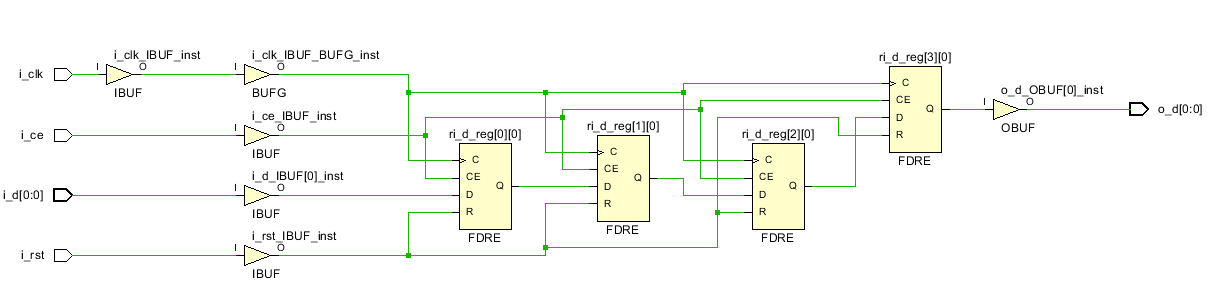
上图显示,并没有生成SRL,而是生成了FDRE,即同步复位触发器,并不符合使用SRL的预期。
而且,代码中在else中写了ri_d<=ri_d的自保持逻辑,如果把自保持的else去掉,综合出的结果会变吗?
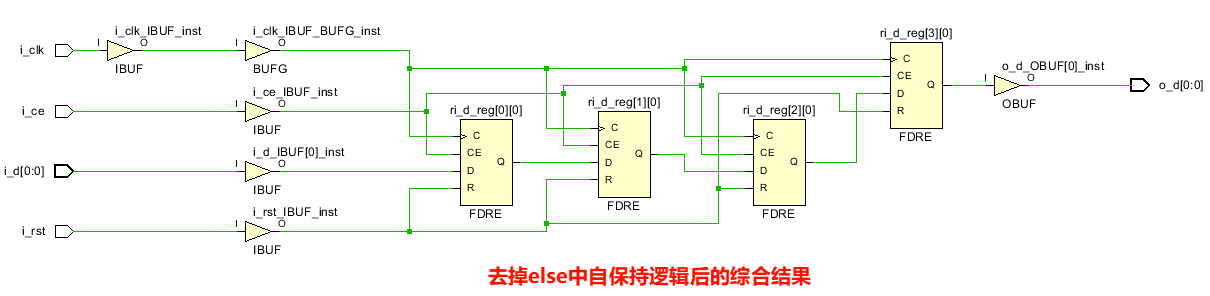
没变。时序逻辑用的触发器,自带自保持功能,不会产生锁存器,所以else中,如果是自保持语句,可以不写,写上的话只是显得逻辑完整,可读性提高。
回到最开始的问题,SRL并没有综合出来,因为其不支持任何复位。修改代码如下,去掉复位。
1 module static_multi_bit_sreg_poor #( 2 parameter DEPTH = 4 , 3 WIDTH = 1 4 ) 5 ( 6 input i_clk , 7 input i_rst , 8 input i_ce , 9 input [WIDTH-1:0] i_d , 10 output [WIDTH-1:0] o_d 11 ); 12 reg [WIDTH-1:0] ri_d [DEPTH]; 13 always @(posedge i_clk) begin 14 if(i_ce)begin 15 ri_d[0] <= i_d; 16 for(int i=1; i < DEPTH; i++) begin 17 ri_d[i] <= ri_d[i-1]; 18 end 19 end 20 end 21 assign o_d = DEPTH==0 ? i_d : ri_d[DEPTH-1]; 22 endmodule
上述代码综合出的结果如下图所示。
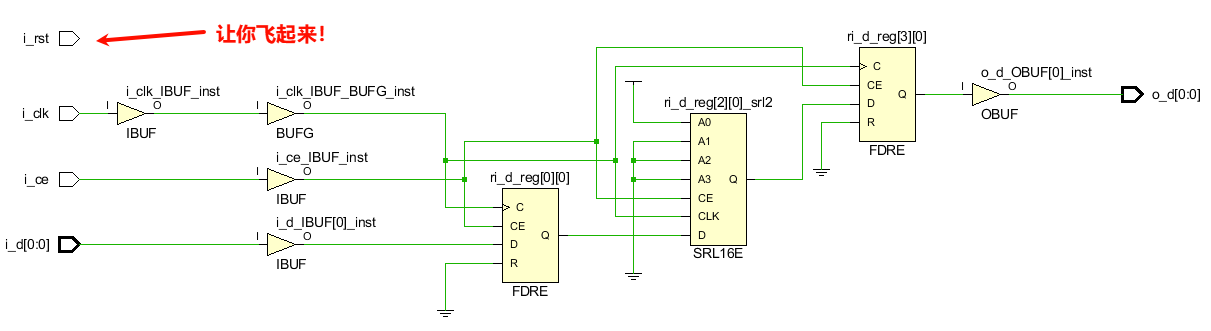
用了一个SRL16E了,如果增加综合约束语句(* SRL_STYLE = "srl" *),就会只使用SRL16E,区别就是A0 A1 A2 A3的值变了,把上面的两个FDRE都免了,直接用SRL移位4位。
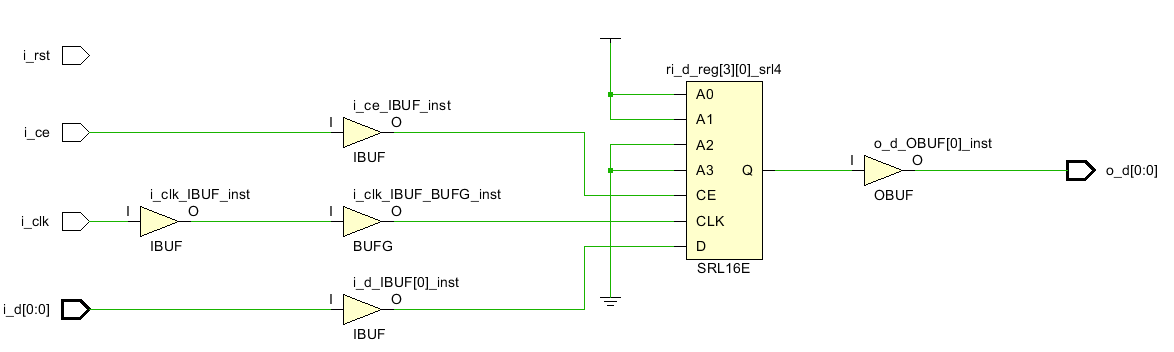
类似的综合约束语句总共有6条,这里列出,就不尝试了。
“SRL_STYLE”属性有六个可选值,分别是:
1、register
使用纯寄存器(Flip-Flops)实现SRL,默认是这个属性。
这种方式通常提供较好的时序性能,因为寄存器的时钟到输出的延迟(Tco)较小。
2、srl
使用查找表(LUT)来实现SRL。
这种方式可以节省寄存器资源,适用于小深度的SRL。
3、srl_reg
使用LUT和触发器的组合来实现SRL,最后一级深度使用触发器。
这种方式结合了LUT和寄存器的优点,适用于中等深度的SRL。
4、reg_srl
同时使用寄存器和LUT资源实现SRL,寄存器放在第一级。
这种方式适用于需要在SRL的输出端提供较好的时序特性的场景。
5、reg_srl_reg
第一级和最后一级深度使用触发器,中间级别使用LUT。
这种方式在SRL的两端使用寄存器,中间使用LUT,适用于需要两端时序保证的SRL。
6、block
使用块RAM(BRAM)来实现SRL。
对于大深度的SRL,这种方式可以有效节省LUT资源,并且提供稳定的存储能力。
现在能按照要求综合出SRL了,还有一个问题,就是Depth这个参数,本意是当其为0时,不进行任何移位,直接输出等于输入。但是设置为0时,综合会报错

数组的深度必须是正整数,为了修改这个问题,可以使用generate for语句,代码如下
module static_multi_bit_sreg_poor #( parameter DEPTH = 0 , WIDTH = 1 ) ( input i_clk , input i_rst , input i_ce , input [WIDTH-1:0] i_d , output [WIDTH-1:0] o_d ); generate if (DEPTH > 0) begin (* srl_style = "srl" *) reg [WIDTH-1:0] sreg [DEPTH]; always @(posedge i_clk) begin if (i_ce) begin sreg[0] <= i_d; for (int i = 1; i < DEPTH; i++) begin sreg[i] <= sreg[i - 1]; end end end assign o_d = sreg[DEPTH - 1]; end else begin assign o_d = i_d; end endgenerate endmodule
当DEPTH等于0时,不会生成sreg[DEPTH]的代码,因此不会让综合器报错。
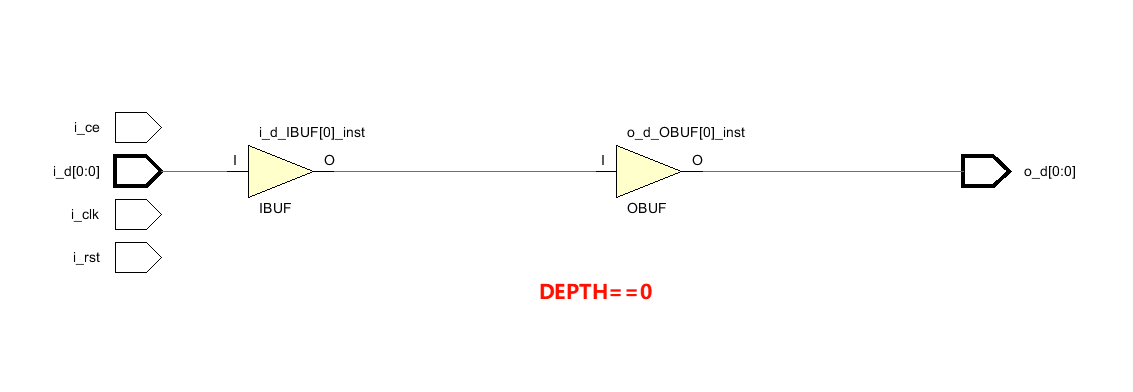
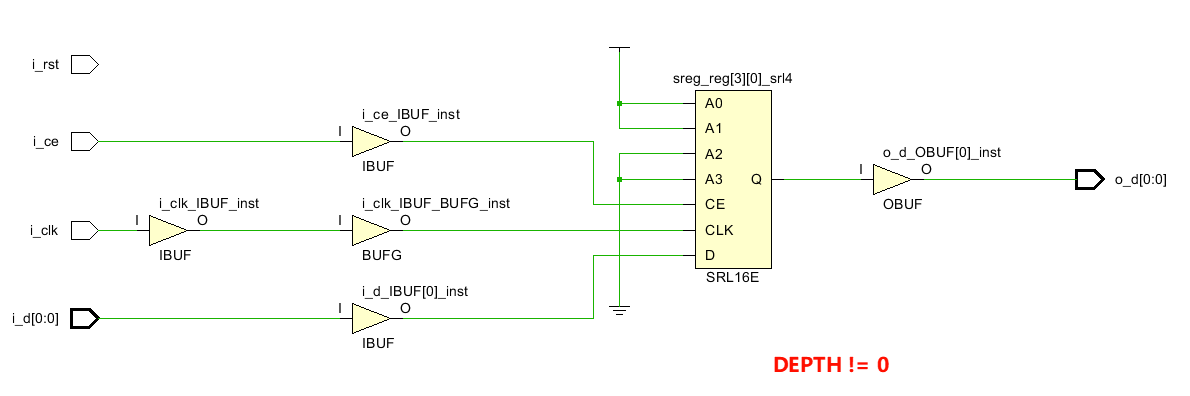
总结
- 想使用SRL就不能用复位,否则无法综合出SRL器件。(流水的移位寄存器复位没有意义)
- 使用约束语句可以调整移位寄存器的资源使用,根据需求选择。
- 使用generate if 语句,可以实现选择生成不同的代码,不满足if条件的会被综合器忽略。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号