20214313 实验四《Python程序设计》报告
20214313 实验四《Python程序设计》报告
课程:《Python程序设计》
班级: 2143
姓名: 冯珂
学号:20214313
实验教师:王志强
实验日期:2022年5月27日
必修/选修: 公选课
一.实验内容
Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
我选择了比较实用的爬虫。在学习爬虫之前,只知道这是一个可以快速获取网站内容的东西,抱着好奇试试的心态我开始尝试起学习用python编写爬虫。到这时才知道这里面也有很多学问和坑,需要一步一个脚印。
网络爬虫,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
Python 爬虫架构主要由五个部分组成,分别是调度器、URL管理器、网页下载器、网页解析器、应用程序(爬取的有价值数据)。
二.实验过程及结果
1.准备库模块
主要需要requests和re两个模块爬取网页,json用来字符串格式转换,os模块进行文件操作,time模块查看时间防止重复提取等功能。

2.执行网页抓取(发起请求,获取响应内容)
通过基本url(种子)来获取数据,然后探索由种子url提取数据中的下一个url。重复该过程。

有些网页有反爬取功能,这里伪造了一个请求头,假装正常浏览器浏览。

根据回应不同也有不同对策。
我选择的是王者全英雄皮肤的抓取。所以网址也会根据英雄不同而改变。

我提前找到了英雄的id的网址,通过联系获得各个英雄的网址来逐个爬取皮肤。


3.存储爬取的信息
提示你爬取是否成功,并存放到指定位置。

4.计算爬取时间

5.华为云服务器的调试。
更新pip至最新版本

安装json等库。
5.上传华为云ECS服务器(华为云服务器是之前已经买好的)
运行程序
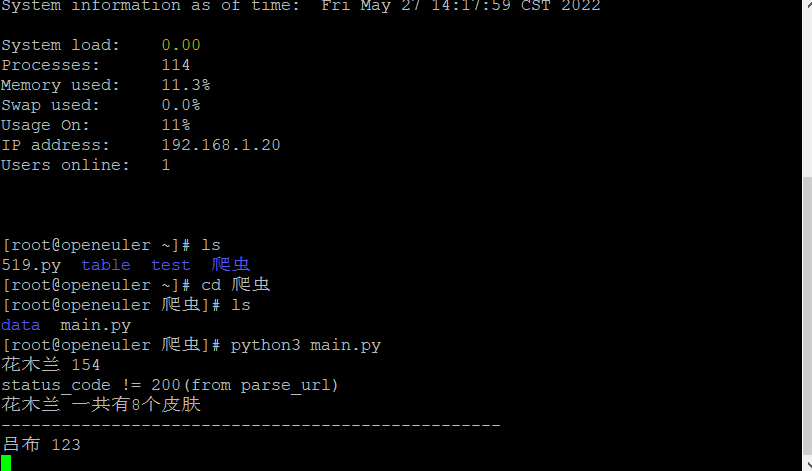
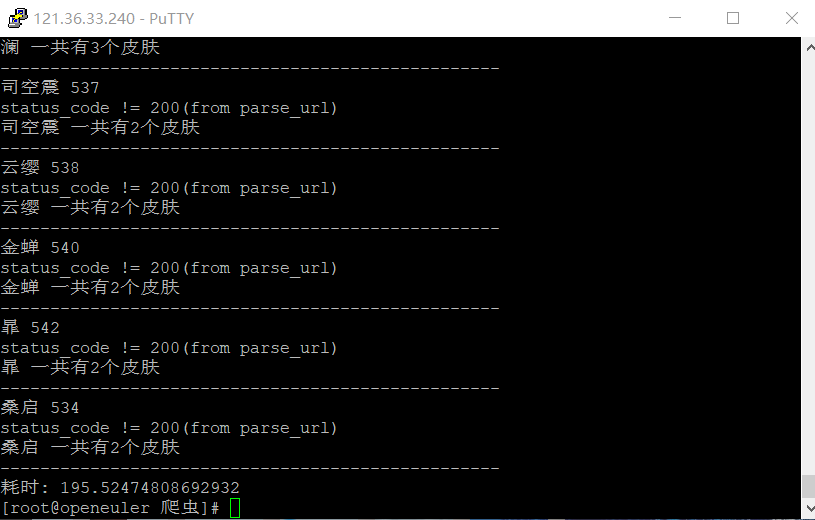
检测结果
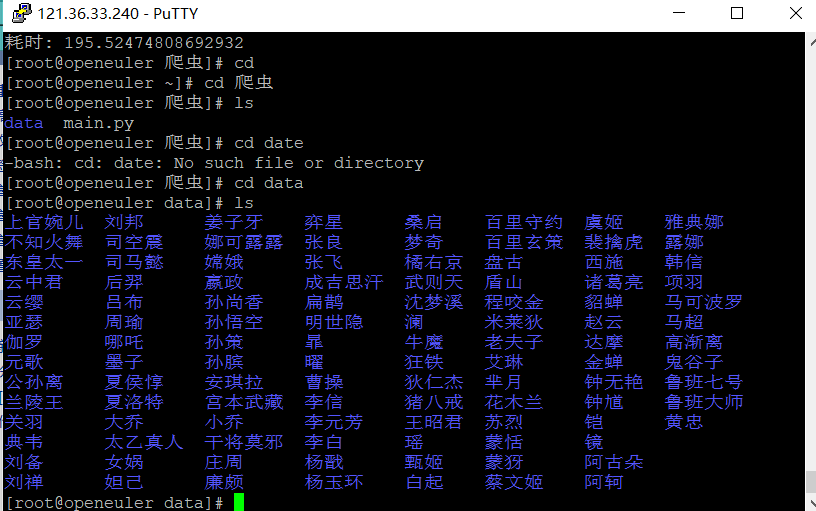
打开一个图片

源代码
`
import requests
import re
import json
import os
import time
# 获取当前时间戳,用于计算爬虫爬取完毕消耗了多少时间
now = lambda: time.time()
# 请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
"Cookie": "pgv_pvid=120529985; pgv_pvi=8147644416; RK=iSx1Z7fSHW; ptcz=d094d0d03f513f6762a4c18a13ddae168782ec153f43b16b604723b27069d0a7; luin=o0894028891; lskey=000100008bc32936da345e2a5268733bf022b5be1613bd2600c10ad315c7559ff138e170f30e0dcd6a325a38; tvfe_boss_uuid=8f47030b9d8237f7; o_cookie=894028891; LW_sid=s116T01788a5f6T2U8I0j4F1K8; LW_uid=Z1q620M7a8E5G6b2m8p0R4U280; eas_sid=m1j6R057x88566P2Z8k074T2N7; eas_entry=https%3A%2F%2Fcn.bing.com%2F; pgv_si=s8425377792; PTTuserFirstTime=1607817600000; isHostDate=18609; isOsSysDate=18609; PTTosSysFirstTime=1607817600000; isOsDate=18609; PTTosFirstTime=1607817600000; pgv_info=ssid=s5339727114; ts_refer=cn.bing.com/; ts_uid=120529985; weekloop=0-0-0-51; ieg_ingame_userid=Qh3nEjEJwxHvg8utb4rT2AJKkM0fsWng; pvpqqcomrouteLine=index_herolist_herolist_herodetail_herodetail_herodetail_herodetail; ts_last=pvp.qq.com/web201605/herolist.shtml; PTTDate=1607856398243",
"referer": "https://pvp.qq.com/"
}
# 解析函数,返回文本或者二进制或者None
def parse_url(url, get_b=False):
try:
response = requests.get(url, headers=headers)
response.encoding = "gbk"
assert response.status_code == 200
if get_b == True:
return response.content
else:
return response.text
except:
print("status_code != 200(from parse_url)")
return None
# 处理单个英雄
def parse_hero_detail(id, name):
# 保存所有皮肤图片的本地路径
path = f"data/{name}"
if not os.path.exists(path):
os.makedirs(path, exist_ok=True)
# 因为不确定每个英雄有多少个皮肤,所以假设单个英雄一共请求10张皮肤,这样就不会出现皮肤缺少的情况
for num in range(1, 11):
# 单个英雄皮肤图片的url链接
api_url = f"https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{id}/{id}-bigskin-{num}.jpg"
# 如果返回None,则说明 状态码不是200,即没有这个请求的皮肤
b_data = parse_url(api_url, get_b=True)
if b_data == None:
print(f"{name} 一共有{num - 1}个皮肤")
print("--------------------------------------------------")
# 没有新的皮肤了,退出循环
break
img_path = f"{path}/demo{num}.jpg"
if not os.path.exists(img_path):
try:
download_img(img_path, b_data)
except:
return
print(f"{name} 第{num}张皮肤图片 下载完毕")
# 下载图片
def download_img(path, b_data):
with open(path, "wb") as f:
f.write(b_data)
def main():
# 含有每个英雄对应的id、英雄名称的url
api_url = "https://game.gtimg.cn/images/yxzj/web201706/js/heroid.js"
text = parse_url(api_url)
search_result = re.search('var module_exports = ({.*?})', text, re.S)
hero_info_str = search_result.group(1)
hero_info_str = re.sub("'", '"', hero_info_str)
# 包含 所有英雄以及各自对应的id 的字典
hero_info_dict = json.loads(hero_info_str)
for hero in hero_info_dict:
name, id = hero_info_dict[hero], hero
print(name, id)
parse_hero_detail(id, name)
if __name__ == '__main__':
start = now() # 记录起始时间
main() # 主函数
print(f"耗时: {now() - start}") # 计算爬虫执行完毕消耗的时间
6.实验问题及解决方法。
问题1:pip指令无法正常起作用。
解决方法:更新pip。
问题2:程序上传后无法运行。
解决方法:下载相关库文件以及更新python版本。
三、课程及实验总结
建议 :
1、老师可以在讲课之前,提前发布以下可能讲的知识点,不然真的很难跟上的说,虽然靠课后学习也能掌握,但是还是课前好啊。
2、希望老师能保持自己的讲课风格,这样生动的课堂真的很有意思(不说能不能跟上)!
3、老师还是保重身体重要。
总结及感想:
虽然学习python只有几个月的零碎时间,但是从我开始接触到这门语言开始,我就知道这是一个简洁又灵活的语言。
从开始的打出第一个句子hello world,到逐渐了解python的变量类型及使用,字典,集合,元组,列表等的用法,再到自己编写猜数游戏,写出自己的第一个socket。
我开始对这门语言有了越来越深的兴趣。在这几个月里,虽然课程不多,但是我学习到的知识,却感觉非常充实,python有无数的东西可以实现,我几乎可以用python报体温,自动回复。
这太酷了不是吗?对于一个男生来说。
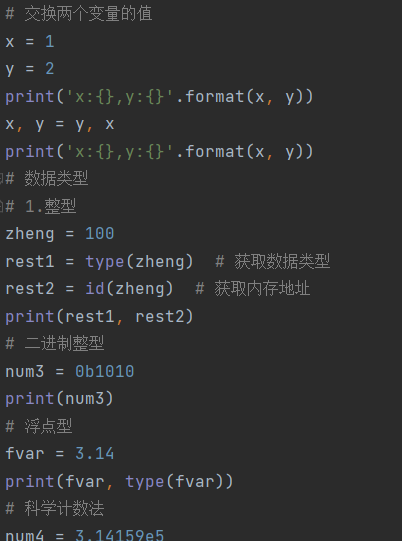
上图是在练习基础变量和语法,虽然是基础,但是真的记住也很困难的,中间好多挫折。
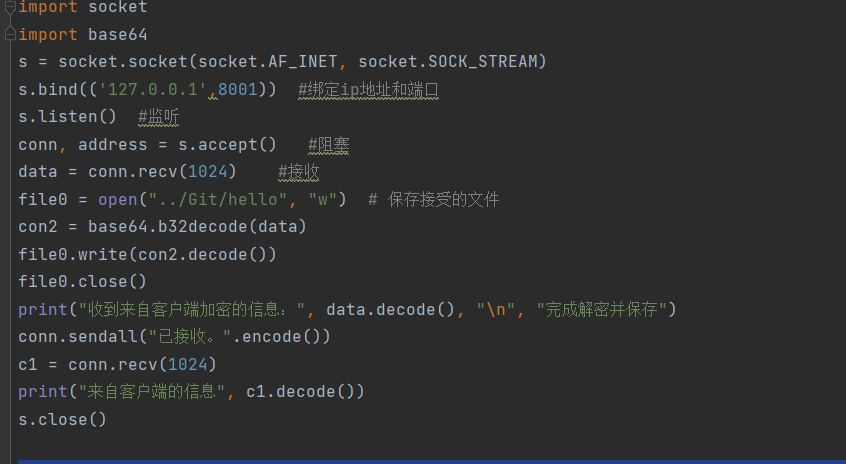
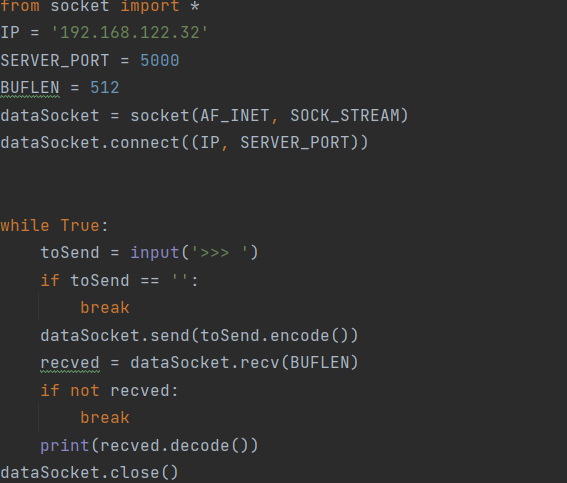
上图是一个简单的socket。
后来,老师讲到了爬虫,也是我当时对python最好奇的地方,尽管听的磕磕绊绊,但是通过不断练习,测试,自己在b站学习,我终于也可以自己写一个爬虫了。
最后一次作业,我也用所学,写了一个爬取王者皮肤的爬虫,以此来表示我对python的兴趣的开始,始于爬虫。
希望在接下来的时间里也能继续对编程语言的兴趣,多多学习,碰撞出思维的火花!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号