
转自:http://www.cnblogs.com/ibook360/archive/2011/11/30/2269077.html
在Solr的自动完成/自动补充实现介绍(第一部分) 中我介绍了怎么用faceting的机制来实现自动完成(autocomplete)的功能,今天我们来看一下如何用Suggester的组件来实现自动完成功能.
开始 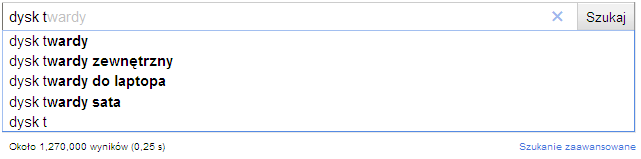
这里有一点需要提醒:Suggest组件在1.4.1或以下版本不可用。要使用这个组件,你需要下载3_x或lucene/solr的主干版本。
配置
在索引配置之前,我们定义一个searchComponent:

<searchComponent name="suggest" class="solr.SpellCheckComponent">
<lst name="spellchecker">
<str name="name">suggest</str>
<str name="classname">org.apache.solr.spelling.suggest.Suggester</str>
<str name="lookupImpl">org.apache.solr.spelling.suggest.tst.TSTLookup</str>
<str name="field">name_autocomplete</str>
</lst>
</searchComponent>
这个组件是基于solr.SpellCheckComponent的,这样我们就可以使用它的一些配置。配置中有3个非常重要的属性:
name:组件名
lookupImpl:绑定这个搜索的对象,目前有两个类可以使用-JasperLookup、TSTLookup,第二个效率更高
field:针对的字段
现在让我们添加合适的handler:
<requestHandler name="/suggest" class="org.apache.solr.handler.component.SearchHandler">
<lst name="defaults">
<str name="spellcheck">true</str>
<str name="spellcheck.dictionary">suggest</str>
<str name="spellcheck.count">10</str>
</lst>
<arr name="components">
<str>suggest</str>
</arr>
</requestHandler>
非常简单的配置,它定义了Search的组件,告诉solr每次建议的最大个数为10,使用上面定义的suggest组件。
索引
假设我们的文档有三个字段:id、name、description。我们想给name字段做自动完成功能,索引配置则为:
<field name="id" type="string" indexed="true" stored="true" multiValued="false" required="true"/>
<field name="name" type="text" indexed="true" stored="true" multiValued="false" />
<field name="name_autocomplete" type="text_auto" indexed="true" stored="true" multiValued="false" />
<field name="description" type="text" indexed="true" stored="true" multiValued="false" />
另外,需要定义一个copyFiled:
<copyField source="name" dest="name_autocomplete" />
单词建议
为了完成单独词的建议,我们需要定义一个 text_autocomplete的类型:
<fieldType class="solr.TextField" name="text_auto" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="1" catenateNumbers="1" catenateAll="0" splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
词组建议
如果实现完整的词组建议,我们的text_autocomplete类型应该定义为:
<fieldType class="solr.TextField" name="text_auto">
<analyzer>
<tokenizer class="solr.KeywordTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
如果使用词组,你需要定义自己的转换类(对于中文如庖丁、iK等)
建立词典
在我们开始使用该组件前,我们需要对它建立索引,可以使用solr命令:
/suggest?spellcheck.build=true
查询
现在终于可以使用这个组件了。使用词组的建议方式,假设查询语句为:
/suggest?q=har
执行该语句后,得到下面的建议:
<?xml version="1.0" encoding="UTF-8"?>
<response>
<lst name="responseHeader">
<int name="status">0</int>
<int name="QTime">0</int>
</lst>
<lst name="spellcheck">
<lst name="suggestions">
<lst name="dys">
<int name="numFound">4</int>
<int name="startOffset">0</int>
<int name="endOffset">3</int>
<arr name="suggestion">
<str>hard drive</str>
<str>hard drive samsung</str>
<str>hard drive seagate</str>
<str>hard drive toshiba</str>
</arr>
</lst>
</lst>
</lst>
</response>
结尾
下一部分我将介绍如何修改配置来使用静态的词典信息以及怎么获得更好的建议。该系列的最后一部分将对会这些方法做一个性能的比较,并选出在不同场景下最快的一个。
原文链接:Solr and Autocomplete (part 2)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号