
转自:http://www.cnblogs.com/ibook360/archive/2011/11/30/2269059.html
大部分人已经见过自动完成(autocomplete)的功能了(见下图),solr提供了构建这个功能的机制。今天,我将给你展示如何使用facet的方式来添加自动完成机制。 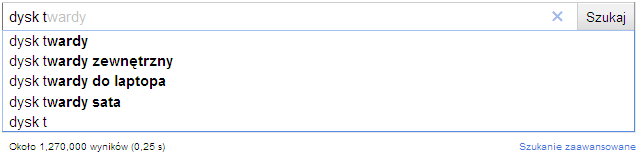
索引
设想你想在你的在线商店中,给用户一些提示,比如商品的名称。假设我们的索引构建如下:
<field name="id" type="string" indexed="true" stored="true" multiValued="false" required="true"/>
<field name="name" type="text" indexed="true" stored="true" multiValued="false" />
<field name="description" type="text" indexed="true" stored="true" multiValued="false" />
text类型的定义为:

<fieldType name="text" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="1" catenateNumbers="1" catenateAll="0" splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
配置
开始前,首先考虑你要实现的功能:是要实现一个名字的提示,还是全名的提示。这都依赖于我们的选择,我们必须为需要引导的地方设置适当的域。
单词提示
在单词的情况下,我们使用的域也即一个token。在这种情况下,域名为name就足够了。但是,这属于一个词干,analysis的操作都在词干上,因此,我们最好换一个其他的类型。
全名提示
我们使用一个不同的域配置来定义全名提示--最好一个未被定义的域。但是我们不能使用基于类似string这种类型的域,基于这个原因,我们定义为一下的域:
<field name="name_auto" type="text_auto" indexed="true" stored="true" multiValued="false" />
text_auto类型的定义为:
<fieldType name="text_auto" class="solr.TextField">
<analyzer>
<tokenizer class="solr.KeywordTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
为了不影响原有数据的格式,将原数据进行拷贝:
<copyField source="name" dest="name_auto" />
如何使用
为了使用这个数据,我们准备了一个简单的查询语句:
q=*:*&facet=true&facet.field=FIELD&facet.mincount=1&facet.prefix=USER_QUERY
需要替换的地方:
FIELD:我们打算提供建议的域,在本例中域名为name 或name_auto
USER_QUERY:用户输入的字符
这里可以设置rows=0,这样可以只返回facet的结果,而没有查询结果。当然这不是必须的。
查询的一个例子可以这样写:
fl=id,name&rows=0&q=*:*&facet=true&facet.field=name_auto&facet.mincount=1&facet.prefix=har
查询结果会返回这样的结果:
<response>
<lst name="responseHeader">
<int name="status">0</int>
<int name="QTime">0</int>
</lst>
<result name="response" numFound="4" start="0"/>
<lst name="facet_counts">
<lst name="facet_queries"/>
<lst name="facet_fields">
<lst name="name_auto">
<int name="hard disk">1</int>
<int name="hard disk samsung">1</int>
<int name="hard disk seagate">1</int>
<int name="hard disk toshiba">1</int>
</lst>
</lst>
<lst name="facet_dates"/></lst>
</response>
扩展功能
这里说一下他的一些常用的功能。
第一个是显示用户的一些额外的信息,比如当你选择某个提示词时,显示的结果的数量。这是一个很有意思的特性。
另一个是使用facet.sort参数进行排序。这依赖于你的需求,我们可以按文档的数量排序(默认方式,设参数为true即可),或者按字母序排序(设为false)。
我们也可以通过设置facet.mincount来显示比指定的数量更多的提示词。
另外一个很好的特性是提示词不仅可以通过用户的类型获取,还可以通过其他的属性获取,这类似于类别。举个例子,我们想给用户展示家庭用品相关的商品,我们假设现在用户对DVD类型的商品并不感兴趣,这样我们添加一个参数: fq=department:homeApplications(假设有这个department)。通过这样的一个查询,你就不需要在所有的索引中匹配了,而是在我们选择的department里选择。
结尾
跟其他方法一样,它有优点,也有缺点。优点就是易于使用、没有额外的组件依赖,并且能将结果约束在一个很小的范围内来更好的匹配用户的需求;另外一个很大的优点是它对每个提示词都附带了结果的统计。缺点就是需要添加额外的类型和字段;另外由于其facet的机制,对机器性能和load都非常消耗。
PS:我自己测试了一下,由于这个功能是实时请求的(每个字母的输入都是一次请求),如果量很大的时候,统计数量会占用很大的内存,内存过小(我的2G)很容易OOM。所以,这个功能慎用。
网上有个哥们建议使用facet.prefix,由于目前没有这方面的强烈需求,故在此搁下,需要时再从这里起步。
原文:http://java.dzone.com/news/solr-and-autocomplete-part-1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号