Tungsten Replicator学习总结
之前基于Tungsten Replicator实现了内部使用的分布式数据库的数据迁移工具,此文为当时调研Tungsten Replicator时的学习心得,创建于2015.7.22。
1 概述
1.1 介绍
Tungsten Replicator是数据库集群和复制供应商Continuent推出的高性能、开源的数据复制引擎,是Continuent最先进的集群解决方案的核心组件之一,特别适合作为异构数据库之间数据迁移的解决方案。
Tungsten Replicator最新的稳定版本是tungsten-replicator-oss-4.0.0-18,官网下载地址为:https://code.google.com/p/tungsten-replicator/wiki/Downloads
1.2 特点
Tungsten Replicator所具有的特点主要有以下几点:
1)支持高版本MySQL向低版本复制,如5.1->5.0;
2)支持跨数据库系统的复制,如MySQL->Oracle,并且所支持的数据库不仅包括MySQL、PostgreSQL和Amazon RDS等传统关系型数据库,还包括MongoDB等NoSQL数据库以及Vertica、InfiniDB、Hadoop和Amazon RedShift等数据仓库;
3)支持多种复制拓扑结构,如Master-Slave、Multi-Master、Direct、Fan-In和Star等。
1.3 其他功能
除了核心的数据复制外,Tungsten Replicator还提供了数据备份与恢复以及数据库基准测试工具等其他辅助功能点。
1.4 说明
本文档旨在阐述Tungsten Replicator的流程和实现细节,为方便起见,文中所有的解释与案例都基于源端数据库和目的端数据库均为MySQL的场景,特此说明。
2 部署与安装
2.1 准备
参与复制的所有主机都需要在部署安装前完成必要的准备工作,如增加特定用户、用户组和所需目录、修改相应权限、环境变量设置、网络配置、安装相关依赖、SSH配置和MySQL配置等。详见官方文档相关章节:http://docs.continuent.com/tungsten-replicator-4.0/prerequisite-staging.html
http://docs.continuent.com/tungsten-replicator-4.0/prerequisite-host.html
http://docs.continuent.com/tungsten-replicator-4.0/prerequisite-mysql.html
2.2 配置与部署
下载完Tungsten Replicator二进制包并解压后,可以利用其自带的tpm工具实现复制拓扑结构的配置和环境搭建,提供了Staging和INI两种部署方式:
1)Staging方式
通过一台Staging host(可以是集群中的某台主机,也可以是单独的)配置好一份集群的部署文件,随后使用tpm configure命令根据配置统一向所有参与复制的主机安装和配置相应服务,其部署示意图如图2.1所示。
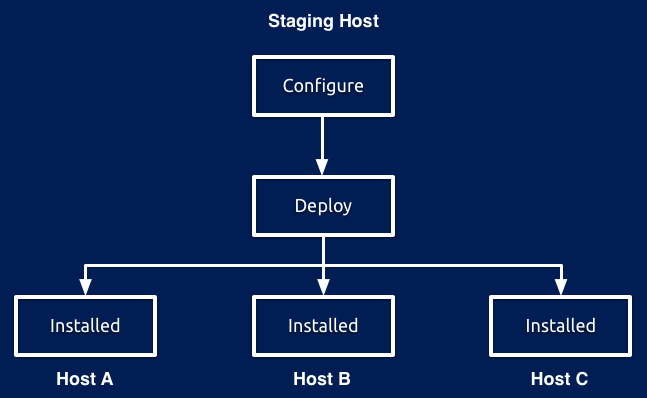
图 2.1
2)INI方式
每台参与复制的主机各自建立并维护一个INI配置文件,分别安装相应的服务,其部署示意图如图2.2所示。
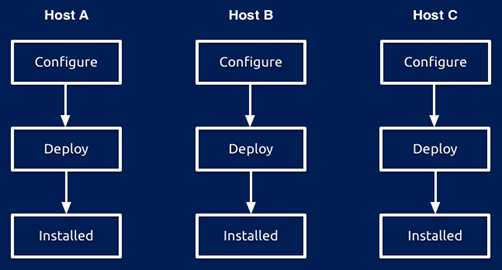
图 2.2
在此,本文以Staging的方式完成后续的部署与安装过程。以最基本的Master-Slave拓扑结构为例,Staging host上的配置命令类似如图2.3:
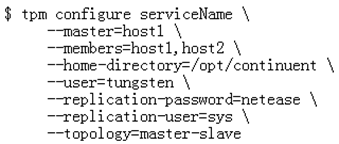
图 2.3
在上述配置中,很多选项和参数都使用了默认值(如端口号、文件路径和命名方式等),因此无需显式指定。在此,指定了host1作为Master,host2作为Slave,serviceName表明了本服务的名字。成功配置后,会在Staging host上生成一个deploy.cfg文件,记录了刚才的配置,可用tpm reverse命令查看。
2.3 安装
在Staging host上使用tpm install命令实现所有主机的安装与配置,此过程由Staging host负责统一完成,若途中安装失败,则回滚此次操作,命令如下:
$ tpm install serviceName–v
此过程,Staging host利用之前配置的SSH无密码连通向每台主机完成所需文件的拷贝和服务配置,若SSH的端口不是默认的22,则需加入选项--net-ssh-option=port=XXX指定。成功安装后,每台主机相应的目录中会生成若干目录和文件。
2.4 启动与监控
安装完成后,需要使用replicator start命令启动Tungsten Replicator服务,同时所配置的所有服务也同时会随之上线,启动命令为:
$ replicator start
如果成功启动,则所配置的服务进入可用状态,复制工作可正常进行。
可使用replicator status命令查看当前运行状态:
$ replicator status
2.5 服务上下线与停止
若希望将某服务下线,则使用trepctl offline命令实现:
$ trepctl -service serviceName offline
若希望将某服务重新上线,则使用trepctl online命令实现:
$ trepctl -service serviceName online
若想停止Tungsten Replicator服务,则需使用replicator stop命令,此时所有运行着的服务均会自动下线:
$ replicator stop
3 Tungsten Replicator复制引擎
3.1组件
3.1.1 角色
角色主要包括Master和Slave等,即运行该Tungsten Replicator实例的主机在复制集群中扮演的角色。
3.1.2 组件
1)ReplicatorPlugin
Tungsten Replicator采用了插件式编程的方式,几乎所有核心部件都是以插件的形式存在的,因此具备高度的可插拔性,用户只需将所需插件设置在配置文件中,并且用户自定义的插件也可轻松集成进系统。所有插件都实现了该接口,包括configure()和prepare()阶段,分别完成初始化和预处理过程。
2)ReplicatorRuntime
整个系统运行的上下文,包括了所有加载的插件和配置文件信息。
3)Pipeline
系统运行的工作流,每个Pipeline根据其角色(Master/Slave)确定不同的业务处理阶段(Stage),每个Stage之间存在先后依赖关系,还可以设置各类PipelineService和Store。
4)PipelineService
Pipeline中设置的服务,包括ChannelAssignmentService和DataSourceService,其中ChannelAssignmentService用于并行复制,而DataSourceService指明了该Pipeline获取数据的来源,如MySQL等。
5)Stage
Tungsten
Replicator中的核心概念,业务流程被拆分为若干Stage先后执行,每个Stage由一个StageTaskGroup来执行,而StageTaskGroup由多个SingleThreadStageTask组成(默认1个,即不开启并行复制),每个SingleThreadStageTask设置一个Extractor、多个Filter和一个Applier。
6)Store
数据存储的组件,包括THL和QueueStore,分别代表Tungsten统一数据格式化日志和内存队列,前后Stage之间的数据交换就是依靠Store完成的。
7)THL
其中一种Store,以一系列只可追加写的THL文件形式存在,从不同数据源抽取来的数据经过格式化后以一种统一的数据存储格式存放于THL中,是Tungsten Replicator实现异构数据库复制的核心部件,其特点包括:
A. THL的记录单元称为一个事件,是顺序记录的;
B. THL的事件是不可变的,不能修改或删除,除非整个THL文件删除;
C. 每个THL事件对应一个数据库事务,被分配一个全局唯一的ID作为标识,称为seqno,从0开始记录
8)Extractor
数据抽取器,用于从数据源或Store中获取所需数据,解析处理并生成相应的ReplDBMSEvent实例,如MySQLExtractor等,核心方法为extract()。
9)Filter
数据过滤器,可以根据需要设置零到多个,Extractor抽取后生成的ReplDBMSEvent会依次经过所有Filter的过滤处理,如ReplicateFilter等,核心方法为filter()。
10)Applier
过滤后的ReplDBMSEvent会交给Applier最终处理,将结果作用于目的端,如MySQLApplier等,核心方法为apply()。
3.2 元数据库表
默认每个服务会在源端和目的端数据库中于启动时自动创建一个用于存放关键服务信息的元数据库(Catalog schema),其命名默认为tungsten_serviceName,其中会创建五张元数据表(Catalog tables),分别为consistency、heartbeat、trep_commit_seqno、trep_shard和trep_shard_channel,其中最重要的就是trep_commit_seqno表,里面维护了最近一条复制信息(如启动了并行复制,则每个channel会维护各自的一条记录),当服务重启时需要读取该信息用于确定数据同步的起始点。
3.3 服务配置信息
除了Tungsten Replicator全局的配置信息外,每个服务都有其各自独立的配置信息,并且根据主机担任的角色不同,配置文件的内容也有所差异,包括三类配置文件,均在安装目录的conf目录下存放:
1)静态配置文件(核心):static-serviceName.properties
2)动态配置文件(非必须):dynamic-serviceName.properties
3)动态角色文件(非必须):dynamic-serviceName.role
与配置信息相关的类包括:
1)ReplicatorRuntimeConf:整个系统的重要目录和配置文件获取,包括程序主目录、日志目录、配置目录等;
2)TungstenProperties:封装了从配置文件中读取到的属性键值对,系统运行时每个组件所需的配置信息都是从中获得的;
3)ReplicatorConf:定义了读取配置文件时的一些常量前缀;
4)ReplicatorRole:枚举类型,只有MASTER/SLAVE/OTHER三种,代表角色。
3.4 总体架构
Tungsten Replicator作为一款数据复制工具,其核心作用就是将数据从源端数据库中抽取,随后依次完成解析、转换、过滤、封装等操作,最终在目的端数据库中应用所有数据,以完成两者的状态同步。
Tungsten Replicator所支持的源端数据库类型目前只限于MySQL和Oracle等几款流行的关系型数据库,而这些数据库对于数据修改的记录都存放在相应的日志文件中,如MySQL的二进制日志binlog和Oracle的CDC(Change Data Capture),因此Tungsten Replicator会通过相应的Extractor向这些日志文件中抽取数据记录,经过处理后应用于目的端数据库。此外对于MySQL而言,binlog的日志记录方式无论是基于语句的还是基于行的都可以有效解析与处理。
同时,每种类型的数据库由于其实现机制和存储格式的不同,无法直接完成数据复制。而Tungsten Replicator之所以可以实现异构数据库的复制,就在于它将从不同数据库中抽取的数据以一种统一的数据存储格式存放于一系列THL文件中(以thl.data.000000XXX方式命名),并且每个记录以事务为单位,拥有全局唯一的序列号,除了数据本身外还包括必要的元数据信息,有利于后续的状态监控和故障恢复。因此如果希望数据复制到不同类型的目的端数据库时,只需编写对应的Applier从THL文件中读取数据进行相应的转换处理即可应用于目的端数据库。而Tungsten Replicator目前支持的目的端数据库种类非常丰富,同时涵盖多款关系型数据库和新型数据库,应用场景极为广泛。总体的架构图如图3.1所示。
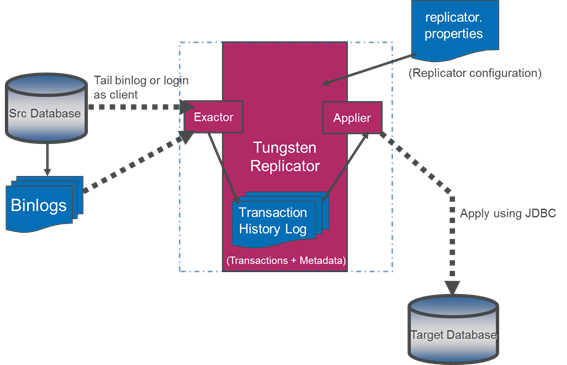
图 3.1
3.5集群架构
由于Tungsten Replicator所支持的复制拓扑结构包括了Master-Slave、Multi-Master、Direct、Fan-In和Star等,每种结构构成的集群方式不尽相同,因此本文选取Direct和Master-Slave这两种结构进行介绍。
3.5.1 Direct架构
参与复制的主机本质上都属于Slave,其角色为Direct,而源端数据库则充当Master。这是最简单的复制拓扑结构,总体示意图如图3.2所示。
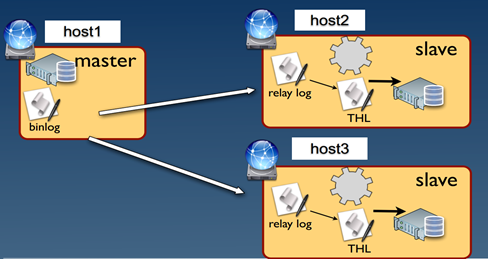
图 3.2
Direct架构默认包含四个Stage:
1)binlog-> queue
默认Extractor是MySQLExtractor,Applier是InMemoryQueueAdapter。
在此阶段,MySQLExtractor从MySQL数据源获取binlog数据(默认先将binlog数据dump到本地relay log中再进行处理),解析binlog中的各类LogEvent,最终以事务为单位创建一个DBMSEvent,添加必要属性(如seqno和eventId等)后封装成ReplDBMSEvent,经过Filters处理后,InMemoryQueueAdapter直接将ReplDBMSEvent放入InMemoryQueueStore中;
2)queue->THL
默认Extractor是InMemoryQueueAdapter,Applier是THLStoreApplier。
在此阶段,InMemoryQueueAdapter从InMemoryQueueStore中取出ReplDBMSEvent数据,经过Filters处理后,THLStoreApplier负责将数据封装成THLEvent后存入本地的THL文件中;
3)THL-> queue
默认Extractor是THLStoreExtractor,Applier是InMemoryQueueAdapter。
在此阶段,THLStoreExtractor从本地THL文件中获取ReplDBMSEvent数据,经过Filter处理后,InMemoryQueueAdapter将其放入InMemoryQueueStore中;
4)queue->MySQL
默认Extractor是InMemoryQueueAdapter,Applier是MySQLDrizzleApplier,Filter是MySQLSessionSupportFilter和PrimaryKeyFilter。
在此阶段,InMemoryQueueAdapter从InMemoryQueueStore中取出ReplDBMSEvent数据,经过Filters处理后,MySQLDrizzleApplier将ReplDBMSEvent中的数据转换为相应的SQL语句,通过JDBC向目的端的MySQL执行命令,完成主从数据同步。
3.5.2 Master-Slave架构
参与复制的主机有N台,其中一台的角色为Master,另外N-1台为Slave。总体示意图如图3.3所示。
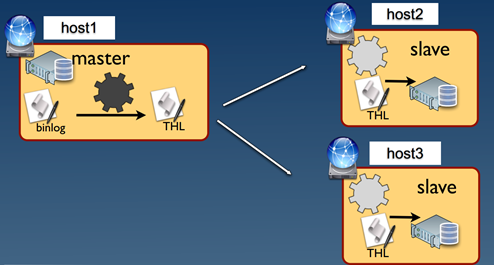
图 3.3
3.5.2.1 Master端架构
Master端共有两个Stage,架构图如图3.4所示:
1) binlog->queue
同Direct第(1)阶段;
2) queue->THL
同Direct第(2)阶段。

图 3.4
3.5.2.2 Slave端架构
Slave端共有三个Stage,架构图如图3.5所示:
1) MasterTHL->THL
默认Extractor是RemoteTHLExtractor,Applier是THLStoreApplier。
在此阶段,RemoteTHLExtractor与Master建立连接并获取其THL文件中的ReplDBMSEvent数据,经过Filter处理后,THLStoreApplier将ReplDBMSEvent存入本地THL;
2) THL->queue
同Direct第(3)阶段;
3) queue->MySQL,
同Direct第(4)阶段。
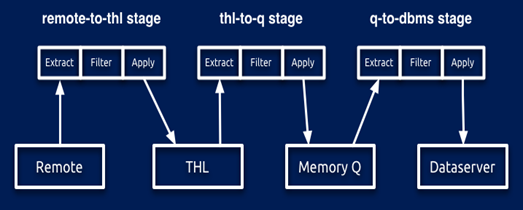
图 3.5
3.6 关键技术点
在Tungsten Replicator的实现过程中涉及到一些较为重要的技术细节,在此逐一阐述。
3.6.1 重启点
在Tungsten Replicator运行的过程中,一旦将数据同步在目的端数据库时,同时还会更新元数据库trep_commit_seqno表中的记录,用于标记最近一条同步记录的相关元数据信息(如seqno、eventId等),这是为了保证服务重启后可以准确初始化重启点,接着上次的进度恢复服务。以Slave为例具体说明其实现过程:
假设Slave端的THL文件中记录的最近一条记录所持有的seqno为N,而目的端数据库中元数据库trep_commit_seqno表最近一条记录所持有的seqno为M,N>M,说明目的端数据库的同步进度尚未追上THL写入的进度。此时,假设服务由于某些原因停止,重新启动后的流程如下:
1)由3.5.2.2可知,Slave端默认存在三个Stage,MySQLDrizzleApplier作为最后一个Stage的Applier会访问目的端数据库,将trep_commit_seqno表最近一条记录(seqno=M)读出封装成一个ReplDBMSHeader实例,依次往前向本Stage的Extractor(InMemoryQueueAdapter)传递,并且会持续传递到第二个Stage的Extractor(THLStoreExtractor),这样该Extractor就知道应该向THL请求第M+1条记录相关的信息。
2)与此同时,第一个Stage的Applier(THLStoreApplier)会从本地THL文件中获取最近一条记录(seqno=N)读出封装成一个ReplDBMSHeader实例,往前向本Stage的Extractor(RemoteTHLExtractor)传递,这样该Extractor就知道应该向Master请求第N+1条记录相关的信息。整个服务的重启点就此恢复到上次运行的最后进度,保证不会丢失同步信息。
3)而如果从trep_commit_seqno表取出的最近一条记录为空,则说明是首次启动该记录尚不存在,Slave此时会向源端数据库发送相应的SQL命令获得其当前binlog位置信息作为数据同步的起始点。
Master端的重启点获取类似Slave的2)阶段。
3.6.2 事务分片
为了特殊处理大事务,Tungsten Replicator中可由配置文件里的transaction_frag_size指定事务分片的阈值,即当一个事务所占的字节数大于此值时需要进行相应的分片。此分片行为在解析抽取binlog的过程中完成,即由MySQLExtractor负责。
完成分片后,一个事务可能对应N个分片,每个分片都是一个ReplDBMSEvent实例,而每个分片的seqno都相同(因为seqno是按照事务为单位分配的全局唯一ID),而它们的fragno(分片号)从0~N-1连续分配,且最后一个分片的lastFragment标志位为true(代表其是该事务最后一个分片)。尽管一个事务可能被分片,但在最终同步到目的端数据库时还是通过相应的机制保证每个分片重新合并成完整的事务并提交,满足事务原子性的特点。
3.6.3 块提交
Tungsten Replicator为了提升数据复制的性能,降低连续提交单事务造成的开销,提供了块提交功能(Block Commit),即可以多个事务可作为一个单元一同提交。触发一次提交的满足条件由blockCommitPolicy、blockCommitRowCount和blockCommitInterval三个属性值共同确定,同时涉及较为复杂的逻辑判断过程,在此不具体详述。
3.6.4 并行复制
Tungsten Replicator默认是不开启并行复制的,但是可以通过相应的配置实现。由于数据最终同步到目的端的过程相对于数据抽取的过程通常会滞后,因此在数据同步阶段采用多线程并行可以加快复制的速度,但是需要相应的处理逻辑来解决可能产生的数据不一致和数据丢失等问题,因为每个并行复制线程的处理进度无法保持一致。
3.6.4.1 实现基础
使用并行复制时,Tungsten Replicator将每个并行复制单元称为一个channel或partition,而实现并行复制的基础就在于原本的单队列(InMemoryQueueStore)被替换为多队列(ParallelQueueStore),每个队列对应一个channel。下面具体介绍并行复制相关的插件:
1)ParallelQueueStore
并行复制的基础数据结构,由N个队列组成。同时设定了一个Partitioner,即分区策略,用来确定一个事件应该被分配给哪个channel进行处理;
2)ParallelQueueApplier
ParallelQueueStore之前的Applier,以单线程的方式将某个事件放入ParallelQueueStore中对应的channel中,以这种串行化的方式是为了保证在数据写入阶段的顺序性;
3)ParallelQueueExtractor
ParallelQueueStore之后的Extractor,开启N个线程,每个线程指定对应一个ParallelQueueStore中的channel,用于将事件从并行队列中取出并进行后续处理。
4)Partitioner
事件分区的策略,包括RoundRobinPartitioner、HashPartitioner和ShardListPartitioner等。其中RoundRobinPartitioner根据事件的seqno通过对channel个数取模进行轮询分配到各个channel中,HashPartitioner根据事件涉及的schema的哈希值对channel个数取模分配,而ShardListPartitioner通过事先配置shard.list文件指定每个schema与channel的映射关系进行分配。值得注意的是,无论采用哪种分区策略,同属一个事务的分片一定会连续地进入同一个channel中进行处理,因为这些分片的seqno都是相同的,保证了事务的完整性。
N个channel组成的并行复制,就会在目的端数据库的元数据表trep_commit_seqno中维护N条记录,每个channel对应一条,即记录了每个channel最近一次同步的数据信息。
与此同时,并行复制中很关键的一环就是判断某事务是否可以与其他事务并行执行,因为事务之间可能存在依赖关系或事务为跨数据库事务,此时相关操作必须临时调整为串行过程来保证数据一致性。为了应对这种场景,必须使用ShardListPartitioner作为分区的策略(因为其他分区策略并未采取相关保护机制,因此可能出现数据不一致现象),具体的情况如下:
1)由于该分区策略保证同属一个数据库的事件会划分到同一个channel,因此同一数据库的所有事务都是串行执行的,这就表明Tungsten Replicator的并行复制只适用于多数据库的业务场景,否则并不能发挥其效率优势;
2)每个事件在被分区的时候,还会设置其critical标志位,如果该值为真则说明该事件不允许与其他数据库相关事件并行,如跨数据库事务或shard.list中配置的数据库相关事务。
3)当将某个critical为真的事件放入并行队列时会判断当前所有的并行队列是否为空,如果是则允许放入;反之就阻塞等待。这种机制保证了某个必须串行的事件在执行的时候不会与其他任何事件并行执行,从而确保复制结果的正确性。
3.6.4.2 实现原理
运行时,在预处理阶段每个channel对应的终端Applier(MySQLDrizzleApplier)会从元数据表trep_commit_seqno中取出各自channel对应的最近同步数据的seqno,以其中最小的seqno对应的事件作为重启点向上请求。这种请求策略是保守但却必要的,因为可能有些请求来的事件是已经处理过的,本无需再次请求,但为了保证最小seqno和最大seqno之间连续的所有事件都不遗漏,因此采取这种方式可以确保主从数据一致性。
随后在正式处理阶段,每个channel对应的Extractor从所属队列中取出事件,判断该事件与其保留的最近事件seqno之间的大小关系:
1)如果是小于或等于,说明之前已经同步过了,无需再次同步,直接忽略;
2)如果是大于,说明是新的事件,需要处理。
因此,采用这种处理流程,虽然由于每个channel的执行进度不统一可能导致某一刻Slave的状态跟Master不同,但服务重启后之前没有处理的事件一定会被重新处理,而已经处理过的事件绝不会重复处理。
3.7状态监控
Tungsten Replicator运行时的状态监控主要包括服务监控与THL日志查看。
3.7.1 服务监控
所有的服务监控都是通过trepctl命令实现的。
3.7.1.2 总体状态监控
通过trepctl status命令查看服务的总体状态,执行结果如图3.6所示。

图 3.6
其中最重要的输出信息包括:
1)appliedLastEventId:最后一条event对应的MySQL binlog和位置偏移。
2)appliedLastSeqno:最后一条event对应的seqno。
3)appliedLatency:对于Master而言,该值代表最后一条event从事务在源端数据库提交到存入本地THL中的时间间隔;对于Slave而言,该值代表最后一条event从事务在源端数据库提交到目的端数据库提交的时间间隔。因此,该值可用于判断Slave数据复制相对于Master的进度。
4)state:当前服务的运行状态,如ONLINE、OFFLINE:NORMAL和OFFLINE:ERROR等。
每个输出字段详细的解释见官方文档相关章节:
http://docs.continuent.com/tungsten-replicator-4.0/terminology-output-fields.html
3.7.1.3 Stage状态监控
通过trepctl status-name stages命令查看服务的每个Stage状态,执行结果如图3.7所示。

图 3.7
3.7.1.4Store状态监控
通过trepctl status -name stores命令查看服务的每个Store状态,执行结果如图3.8所示。
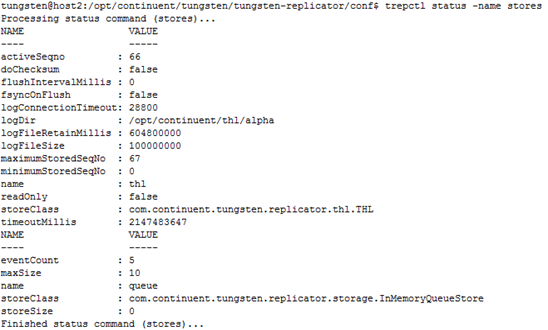
图 3.8
3.7.1.5 Shard状态监控
通过trepctl status -name shards命令查看服务的每个Shard状态,主要用于并行复制的场景,执行结果如图3.9所示。
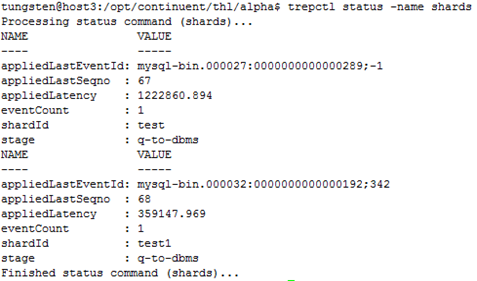
图 3.9
3.7.2 THL日志查看
THL日志相关查看通过thl命令实现的。
3.7.2.1 THL总体信息
通过thl info命令查看服务的THL总体信息,包括THL文件数量、存放路径、文件大小、事件个数、事件ID等信息,执行结果如图3.10所示。

图 3.10
3.7.2.2 THL索引信息
通过thl index命令查看服务所有的THL文件以及其记录的事件范围,执行结果如图3.11所示。
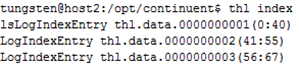
图 3.11
3.7.2.3 THL事件查看
通过thl list指令查看THL中某条或某几条事件记录的详细信息,执行结果如图3.12和图3.13所示,分别显示了MySQL中的一条SQL数据和RowChange数据。
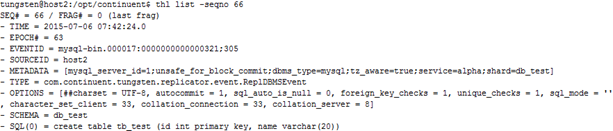
图 3.12
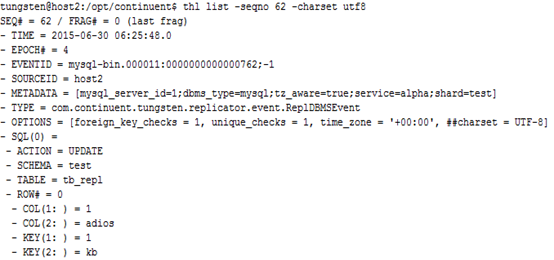
图 3.13
为尊重原创成果,如需转载烦请注明本文出处:http://www.cnblogs.com/fernandolee24/p/6259480.html ,特此感谢

 浙公网安备 33010602011771号
浙公网安备 33010602011771号