k8s集群搭建(一)
k8s简介
kubernetes,简称K8s,是用8代替8个字符“ubernete”而成的缩写。是一个开源的,用于管理云平台中多个主机上的容器化的应用,Kubernetes的目标是让部署容器化的应用简单并且高效(powerful),Kubernetes提供了应用部署,规划,更新,维护的一种机制
k8s的资源对象
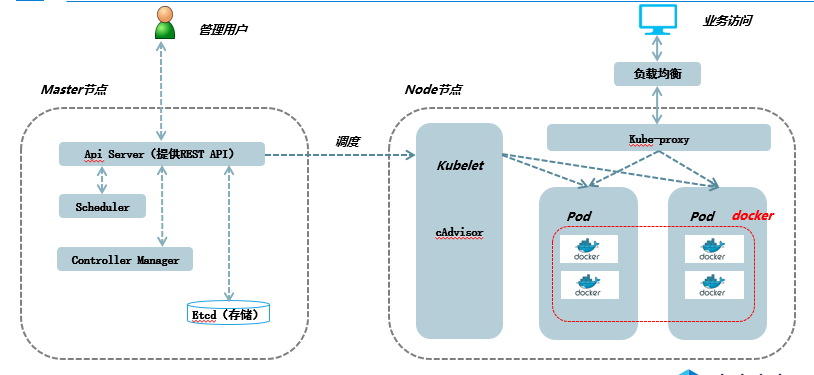
master
kubernetes里的master指的是集群控制节点,在每个kubernetes集群里都需要有一个master来负责真个集群的管理和控制,在master上运行着以下关键进程:
- API Server(kube-apiserver):提供了HTTP Rest接口的关键服务进程,是kubernetes里所有资源的增删改查等操作的唯一入口,也是集群中的入口进程
- Controller Manager(kube-controller-manager):kubernetes里所有资源对象的自动化控制中心,可以理解成为资源对象的“大总管”
- Scheduler:(kube-scheduler):负责资源调度(pod调度)的进程,相当于公交公司的“调度室”
- Etcd:所有资源对象的数据被会被保存到etcd中,持久化
node
除了master,kubernetes集群中其他机器被称之为 Node,node可以是一台物理机,也可以是一台虚拟机,node是kubernetes集群中的工作负载节点,每个node都会被master分配一些工作负载(docker容器),当某个node宕机时,其他节点会接管故障节点的资源,node节点当中的重要进程:
- kubelet:负责pod对应容器的创建,启停等任务,另外kubelet与master紧密协作,随时报告给master自身的情况,如CPU,内存,操作系统,docker版本等
- kube-proxy:实现kubernetes server的通信与负载均衡机制的重要组件
- docker engine:docker引擎,负责本主机的容器创建 和管理工作
pod
pod是kubernetes最重要的基本概念,是kubernetes调度的最小单元,每个container都有一个pause容器,称之为根容器,属于kubernetes平台的一部分,一个pod可以运行多个容器(container),但是一般来说我们一个pod只运行一个container,如下图:

k8s集群架构图
集群的搭建(master)
简单了解k8s的资源对象之后咱们就先来搭建一个k8s集群,因为我们的后续操作都是建立在k8s集群当中的,因此,我们就需要先搭建一个k8s集群,这样也便于大家的理解
环境准备
三台机器:
- master:192.168.254.13
- node1:192.168.254.12
- node2:192.168.254.10
- 基于主机名通信:/etc/hosts;
- 时间同步
- 关闭firewalld,selinux
规划如下:

第一步:确保master和node中开启内核参数
echo 1 > /proc/sys/net/bridge/bridge-nf-call-iptables note:如果提示没有bridge-nf-call-iptables 解决办法: [root@localhost ~]# modprobe br_netfilter
第二步:配置docker yum源和kubenetes yum源并且安装
#安装kubernetes的yum源
vim /etc/yum.repos.d/kubernetes.repo [kubernetes] name = kubernetes baseurl = https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled = 1 gpgcheck = 1 gpgkey = https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg #安装docker的yum源 cd /etc/yum.repos.d/ wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo yum install kubelet kubeadm kubectl docker-ce -y
第三步:添加初始化额外参数,忽略swap报警信息
[root@localhost ~]# vim /etc/sysconfig/kubelet KUBELET_EXTRA_ARGS="--fail-swap-on=false" [root@localhost ~]# service docker restart
第四步:初始化集群
[root@localhost ~]# kubeadm init --kubernetes-version=v1.15.2 --service-cidr=10.96.0.0/12 --pod-network-cidr=10.244.0.0/16 --ignore-preflight-errors=Swap --ignore-preflight-errors=NumCPU --image-repository registry.aliyuncs.com/google_containers 解释: --apiserver-advertise-address:指定用 Master 的哪个IP地址与 Cluster的其他节点通信。 --service-cidr:指定Service网络的范围,即负载均衡VIP使用的IP地址段。 --pod-network-cidr:指定Pod网络的范围,即Pod的IP地址段。 --image-repository:Kubenetes默认Registries地址是 k8s.gcr.io,在国内并不能访问 gcr.io,在1.13版本中我们可以增加-image-repository参数,默认值是 k8s.gcr.io,将其指定为阿里云镜像地址:registry.aliyuncs.com/google_containers。 --kubernetes-version=v1.13.3:指定要安装的版本号。 --ignore-preflight-errors=:忽略运行时的错误,例如上面目前存在[ERROR NumCPU]和[ERROR Swap],忽略这两个报错就是增加--ignore-preflight-errors=NumCPU 和--ignore-preflight-errors=Swap的配置即可。
第五步:记录以下内容,因为后期我们的node节点需要通过ca认证加入到集群当中
kubeadm join 192.168.254.13:6443 --token 71ovlq.w7pf14czrwi7f1ag --discovery-token-ca-cert-hash sha256:d2a9a1aa23fdbcd42711a222c959026073cf0a70f37a87806233d8319c66feb4
第六步:按照提示完成以下三步
[root@localhost ~]# mkdir -p $HOME/.kube [root@localhost ~]# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config [root@localhost ~]# chown $(id -u):$(id -g) $HOME/.kube/config
第七步:查看节点状态
这里的NotReady是因为咱们还没有部署网络
[root@localhost ~]# kubectl get node NAME STATUS ROLES AGE VERSION localhost.localdomain NotReady master 8h v1.15.2
第八步:查看组件状态
[root@localhost ~]# kubectl get cs NAME STATUS MESSAGE ERROR controller-manager Healthy ok scheduler Healthy ok etcd-0 Healthy {"health":"true"}
第九步:部署flannel网络(github)
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml 若下载失败可以从阿里云上pull [root@master1 ~]# docker pull registry.cn-hangzhou.aliyuncs.com/rsq_kubeadm/flannel:v0.11.0-amd64 [root@master1 ~]# docker tag registry.cn-hangzhou.aliyuncs.com/rsq_kubeadm/flannel:v0.11.0-amd64 quay.io/coreos/flannel:v0.11.0-amd64 [root@master1 ~]# docker rmi registry.cn-hangzhou.aliyuncs.com/rsq_kubeadm/flannel:v0.11.0-amd64
集群的搭建(2个node节点)
对于2个node节点的配置跟master节点的1,2,3步一样,这里就不在写了,直接跳到第四步
第四步:节点加入集群,也就是部署master时候的第五步
[root@localhost ~]#kubeadm join 192.168.254.13:6443 --token wug9gq.m9j7hhmvvy9ag8kk --discovery-token-ca-cert-hash sha256:6f8a056391bf04c3911465c581e78376e1d35eb309641105ddd69ce5eb47c591 --ignore-preflight-errors=Swap
第五步:在master节点上用一下命令查看,以下状态是代表ok
[root@master ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION master Ready master 10h v1.15.3 node1 Ready <none> 10h v1.15.3 node2 Ready <none> 10h v1.15.3
补充
1.如果发现以上错误说明master节点token失效,需要在master上重新生成 [root@localhost ~]# kubeadm token create --print-join-command 3.如果node机器曾经加入过集群,要重新加入需要kubeadm reset重置,然后在join [root@localhost ~]# kubeadm reset 4.如果忘掉token [root@master ~]# kubeadm token list
5.如果忘掉hash串 [root@master]openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
kubectl命令
kubectl命令是用来在k8s集群当中进行增删改查pod的重要命令,它的常用命令如下:
kubectl get nodes #获取节点信息 kubectl get pods -n kube-system #获取kube-system名称空间内的信息 kubectl get pods -n kube-system -o wide #获取kube-system名称空间的详细信息 kubectl get cs #获取component组件的状态 kubectl get ns #获取所有名称空间的状态 kubectl describe node NODENAME #查看节点的详细信息 kubectl cluster-info #集群信息 kubectl delete pod httpd1 #删除所创建的pod kubectl apply #针对于清单文件创建pod,也可以用这个命令进行更新,他会检查etcd中的数据,把不同地方同步 kubectl patch #打补丁,比如replacas从1修改成5 kubectl rollout undo #回滚 kubectl expose #创建一个service kubectl scale #扩容或者缩容 kubectl edit #编辑pod或者service清单文件
例子:
1.启动pod,跑nginx服务(在这里的80端口只能被各个pod所访问,集群外的机器无法访问,因为如果pod死掉会重新起一个新pod,但是ip会改变,因此我们在访问服务时不能以pod的ip为准,因此,需要serviceip) [root@master ~]#kubectl run nginx-deployment --image=nginx:1.14-alpine --port=80 --replicas=1 2.获取pod名称信息,然后映射给service [root@master ~]# kubectl get pods NAME READY STATUS RESTARTS AGE nginx-deployment-675947b94d-vwcnj 1/1 Running 0 145m nginx1-7f4f664fbf-c54z6 1/1 Running 0 145m 3.查看一个pod的标签,在用describe svc SERVICE去查看标签选择器是否一致 [root@master ~]# kubectl get pods --show-labels; NAME READY STATUS RESTARTS AGE LABELS nginx-6db489d4b7-bk4sr 1/1 Running 0 71m pod-template-hash=6db489d4b7,run=nginx nginx-6db489d4b7-gmwsg 1/1 Running 0 74m pod-template-hash=6db489d4b7,run=nginx 4.暴露端口80端口集群网络 [root@master ~]# kubectl expose deployment nginx-deployment --name=nginx --port=80 --target-port=80 --protocol=TCP service/nginx exposed 解释: --name: 创建的服务名称 --port: service端口 --target-port: pod端口 --protocol: 协议 deployment: 后面跟创建pod的名字 5.查看服务ip,刚才的nginx服务ip就位10.99.108.60(这里的ip,也是只能在集群内部各节点中访问,集群外无法访问) [root@master ~]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 15h nginx ClusterIP 10.99.108.60 <none> 80/TCP 7m1s 6.进入到容器交互界面 kubectl exec -it nginx-56b8c64cb4-t97vb -- /bin/bash #假如当前pod只有一个容器,运行以下命令即可 7.增加原有服务pod数量(动态扩容和缩容) kubectl scale --replicas=6 deployment nginx 8.滚动更新 kubectl set image deployment nginx nginx=nginx:1.14-alpine 查看滚动更新状态 kubectl rollout status deployment nginx 如果更新完成之后发现有问题我们还可以做回滚操作 kubectl rollout undo deployment nginx 9.如果想要让集群以外的客户端访问,需要修改pod的service kubectl edit svc nginx type: ClusterIP替换成type:NodePort即可
