
机器学习 KNN算法实现 (鸢尾花)

![]()

frame 是Pandas的dataframe对象
alpha 图像透明度
figsize 英寸为单位的图像大小
diagonal 只能在{‘hist','kde'}中选一个 hist表示直方图 kde表示核密度估计
这个参数是scatter_matrix的关键参数
marker 是标记类型,如圈,点,三角号
代码
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split iris_dataset=load_iris() X_train,X_test,y_train,y_test=train_test_split(iris_dataset['data'],iris_dataset['target'],random_state=2) #print("X_train",X_train) #print("y_train",y_train) #print("X_test",X_test) #print("y_test",y_test) #print("X_train shape: {}".format(X_train.shape)) #print("X_test shape: {}".format(X_test.shape)) import pandas as pd import matplotlib.pyplot as plt iris_dataframe=pd.DataFrame(X_train,columns=iris_dataset.feature_names) pd.plotting.scatter_matrix(iris_dataframe,c=y_train,figsize=(15,15),marker='o',hist_kwds={'bins':20},s=60,alpha=.8) plt.show()
其中在 jupyter notebook里是不需要import matplotlib.pyplot 就可以显示图像
但是在VScode里必须 加这句
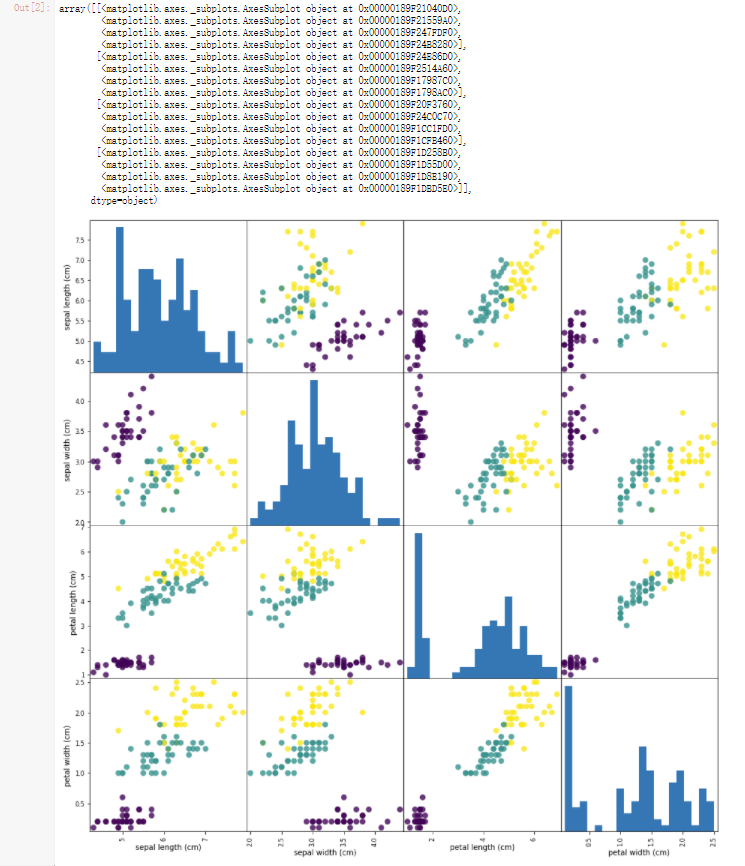
从中可以看出 比如 special width 和 special length 之间的关系比较杂乱
我们在训练模型时要优先选择关系明显的特征对进行学习


n_neighbors 表示近邻数量
weights 计算距离时的权重 缺省值是uniform 表示平均权重
distance表示距离远近设置不同的权重
metric 是距离的计算 缺省值是 minkowski 闵氏距离
显然当P=2即为欧氏距离
P=1即为曼哈顿距离
from sklearn import datasets from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import train_test_split iris=datasets.load_iris() print("数据集结构:",iris.data.shape) #获取属性 iris_X=iris.data #获取类别 iris_y=iris.target #划分数据集和训练集 iris_train_X,iris_test_X,iris_train_y,iris_test_y=train_test_split(iris_X,iris_y,test_size=0.2,random_state=0) #分类器初始化,参数默认 knn=KNeighborsClassifier() #对训练集进行训练 knn.fit(iris_train_X,iris_train_y) #对测试集数据的鸢尾花类型进行预测 predict_result=knn.predict(iris_test_X) print("测试集大小:",iris_test_X.shape) print("真实结果:",iris_test_y) print("预测结果:",predict_result) #显示预测结果准确率 print("预测准确率",knn.score(iris_test_X,iris_test_y))


