分布式存储
2022-06-15 17:09 @学无止境 阅读(2329) 评论(0) 收藏 举报原文:
https://www.elecfans.com/consume/1347010.html
分布式存储技术
1.什么是分布式存储
在了解什么是分布式存储之前,我们先来了解一下存储几十年来的大概历程。
直连存储(DAS):存储和数据直连,拓展性、灵活性差。
中心化存储(SAN、NAS):设备类型丰富,通过IP/FC网络互连,具有一定的拓展性,但是受到控制器能力限制,拓展能力有限。同时,设备到了生命周期要进行更换,数据迁移需要耗费大量的时间和精力。
分布式存储:基于标准硬件和分布式架构,实现千节点/EB级扩展,同时可以对块、对象、文件等多种类型存储统一管理。
分布式存储就是将数据分散存储到多个存储服务器上,并将这些分散的存储资源构成一个虚拟的存储设备,实际上数据分散的存储在企业的各个角落。
打个简单的比方,将数据比作成货物,存储比作成货车,直连存储就相当于用普通货车拉货;为了提升拉货的效率,改用大型的货车拉货,这就相当于中心化存储;现在,由于货物太多,大型的货车已经不足以拉动全部货物,改用一节一节连接起来的火车拉货,这就是分布式存储。分布式系统的出现是为了用普通的机器完成单个计算机无法完成的计算、存储任务,目的是利用更多的机器,处理更多的数据。
2.分布式存储的优势
可扩展:分布式存储系统可以扩展到数百甚至数千个这样的集群大小,并且系统的整体性能可以线性增长。
低成本:分布式存储系统的自动容错和自动负载平衡允许在低成本服务器上构建分布式存储系统。此外,线性可扩展性还能够增加和降低服务器的成本,并实现分布式存储系统的自动操作和维护。
高性能:无论是针对单个服务器还是针对分布式存储群集,分布式存储系统都需要高性能。
分布式存储框架
分布式存储技术的实现,往往离不开底层的分布式存储框架。根据其存储的类型,可分为块存储,对象存储和文件存储。在主流的分布式存储技术中,HDFS属于文件存储,Swift属于对象存储,而Ceph可支持块存储、对象存储和文件存储,故称为统一存储。
1.HDFS
HDFS是Hadoop核心组成之一,是分布式计算中数据存储管理的基础,被设计成适合运行在通用硬件上的分布式文件系统。

1.1 HDFS的功能模块
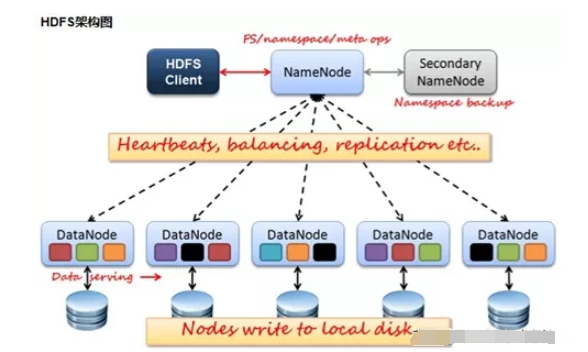
Client
Client是用户与HDFS交互的手段,当文件上传 HDFS 的时候,Client 将文件切分成一个一个的 Block,然后进行上传;Client通过与NameNode 交互,来获取文件的位置信息;与 DataNode 交互,读取或者写入数据;Client还可以提供NameNode格式化等一些命令来管理HDFS;同时,Client可以通过对HDFS的增删改查等操作来访问HDFS。
NameNode
NameNode就是HDFS的Master架构,它维护着文件系统树及整棵树内所有的文件和目录,HDFS文件系统中处理客服端读写请求、管理数据块(Block)的映射信息、配置副本策略等管理工作由NameNode来完成。
DataNode
NameNode 下达命令,DataNode 执行实际操作。DataNode表示实际存储的数据块,同时可以执行数据块的读写操作。
Secondary NameNode
Secondary NameNode的功能主要是辅助NameNode,分担其工作量;在紧急情况下可以辅助恢复NameNode,但是它不能替换NameNode并提供服务。
1.2 HDFS的优势
1.容错性:数据自动保存多个副本。通过增加副本的形式,提高容错性。其中一个副本丢失以后,可以自动恢复。
2.可以处理大数据:能够处理数据规模达到GB、TB甚至PB级别的数据;能够处理百万规模以上的文件数量。
3.可以构建在廉价的机器上,通过多副本机制,提高可靠性。
1.3 HDFS的缺点
1.不适合低延时数据访问:比如毫秒级的存储数据,是做不到的。
2.无法高效对大量小文件进行存储:存储大量小文件的话,它会占用 NameNode 大量的内存来存储文件目录和块信息。这样是不可取的,因为 NameNode的内存总是有限的。同时,小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标。
3.不支持并发写入、文件随机修改:一个文件只能有一个写,不允许多个线程同时写。仅支持数据 append(追加),不支持文件的随机修改。
2.Swift
swift于2008年起步,最初是由Rackspace公司开发的分布式对象存储服务, 2010 年贡献给 OpenStack 开源社区。现如今已部署到大规模公有云的生产环境中使用。
2.1 Swift的功能模块
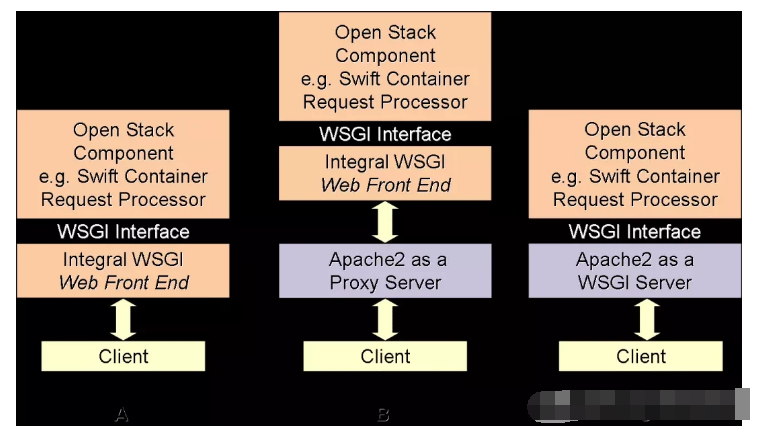
Swift 采用完全对称、面向资源的分布式系统架构设计,所有组件都可扩展,避免因单点失效而影响整个系统的可用性。
Proxy Server(代理服务):对外提供对象服务 API,Proxy Server首先会通过Ring查找被操作实体的物理位置,随后将请求转发至相应的账户、容器或对象服务。
AuthenTIcaTIon Server(认证服务):验证用户的身份信息,并获得一个访问令牌(Token)。
Cache Server(缓存服务):缓存令牌,账户和容器信息,但不会缓存对象本身的数据。
Account Server(账户服务):Account Server是存储节点中负责处理Account的get、head、put、delete、relicaTIon请求的服务进程。提供账户元数据和统计信息,并维护所含容器列表的服务。
Container Server(容器服务):Container Server是存储节点中负责处理Container的get、head、put、delete、relicaTIon请求的服务进程。提供容器元数据和统计信息,并维护所含对象列表的服务。
Object Server(对象服务):Object Server就是一个简单的BLOB存储服务器,可以存储、检索和删除保存再本地设备的对象。提供对象元数据和内容服务,每个对象会以文件存储在文件系统中。
Replicator(复制服务):检测本地副本和远程副本是否一致,采用推式(Push)更新远程副本。
Updater(更新服务):对象内容的更新。
Auditor(审计服务):检查对象、容器和账户的完整性,如果发现错误,文件将被隔离。
Account Reaper(账户清理服务):移除被标记为删除的账户,删除其所包含的所有容器和对象。
2.2 Swift的技术特点
1.Swift的数据模型采用层次结构,共设三层:Account/Container/Object(即账户/容器/对象),每层节点数均没有限制,可以任意扩展。
2.Swift是基于一致性散列技术,通过计算将对象均匀分布在虚拟空间的虚拟节点上,在增加、删除节点时可以大大减少需移动的数据量;通过独特的数据结构 Ring(环),再将虚拟节点映射到实际的物理存储设备上,完成寻址过程。
3.Swift为账户、容器和对象分别定义了的环。环是为了将虚拟节点(分区)映射到一组物理存储设备上,并提供一定的冗余度而设计的,环的数据信息包括存储设备列表和设备信息、分区到设备的映射关系、计算分区号的位移。
2.3 Swift的优点
1.极高的数据持久性
2.完全对称的系统架构
3.无限的可扩展性
4.无单点故障
5.是OpenStack的子项目之一,适合云环境的部署
2.4 Swift的缺点
原生的对象存储,不支持实时的文件读写、编辑功能
3.Ceph
Ceph最早起源于Sage就读博士期间的工作、成果于2004年发表,并随后贡献给开源社区。经过十几年的发展,已成为应用最广泛的开源分布式存储平台。
3.1 Ceph的主要架构
基础存储系统RADOS
Ceph的最底层是RADOS(分布式对象存储系统),它具有可靠、智能、分布式等特性,实现高可靠、高可拓展、高性能、高自动化等功能,并最终存储用户数据。RADOS系统主要由Ceph OSD、Ceph Monitors两部分组成,Ceph OSD 的功能是存储数据,处理数据的复制、恢复、回填、再均衡,并通过检查其他OSD 守护进程的心跳来向 Ceph Monitors 提供一些监控信息。Ceph Monitor维护着展示集群状态的各种图表,包括监视器图、 OSD 图、归置组( PG )图、和 CRUSH 图。
基础库LIBRADOS
LIBRADOS层的功能是对RADOS进行抽象和封装,并向上层提供API,以便直接基于RADOS进行应用开发。RADOS是一个对象存储系统,因此,LIBRADOS实现的API是针对对象存储功能的。物理上,LIBRADOS和基于其上开发的应用位于同一台机器,因而也被称为本地API。应用调用本机上的LIBRADOS API,再由后者通过socket与RADOS集群中的节点通信并完成各种操作。
上层应用接口
Ceph上层应用接口涵盖了RADOSGW(RADOS Gateway)、RBD(Reliable Block Device)和Ceph FS(Ceph File System),其中,RADOSGW和RBD是在LIBRADOS库的基础上提供抽象层次更高、更便于应用或客户端使用的上层接口。
应用层
应用层就是不同场景下对于Ceph各个应用接口的各种应用方式,例如基于LIBRADOS直接开发的对象存储应用,基于RADOSGW开发的对象存储应用,基于RBD实现的云主机硬盘等。
3.2 Ceph的功能模块
Client客户端:负责存储协议的接入,节点负载均衡。
MON监控服务:负责监控整个集群,维护集群的健康状态,维护展示集群状态的各种图表,如OSD Map、Monitor Map、PG Map和CRUSH Map。
MDS元数据服务:负责保存文件系统的元数据,管理目录结构。
OSD存储服务:主要功能是存储数据、复制数据、平衡数据、恢复数据,以及与其它OSD间进行心跳检查等。一般情况下一块硬盘对应一个OSD。
3.3 Ceph的优点
1.CRUSH算法
CRUSH算法是ceph的两大创新之一,简单来说,ceph摒弃了传统的集中式存储元数据寻址的方案,转而使用CRUSH算法完成数据的寻址操作。采用CRUSH算法,数据分布均衡,并行度高,不需要维护固定的元数据结构。
2.高可用
Ceph中的数据副本数量可以由管理员自行定义,并可以通过CRUSH算法指定副本的物理存储位置以分隔故障域,支持数据强一致性,适合读多写少场景;ceph可以忍受多种故障场景并自动尝试并行修复。
3.高扩展性
Ceph本身并没有主控节点,扩展起来比较容易,并且理论上,它的性能会随着磁盘数量的增加而线性增长。
4.特性丰富
Ceph支持对象存储、块存储和文件存储服务,故称为统一存储
3.4 Ceph的缺点
1.去中心化的分布式解决方案,需要提前做好规划设计,对技术团队的要求能力比较高。
2.Ceph扩容时,由于其数据分布均衡的特性,会导致整个存储系统性能的下降。
BMJ分布式存储
BMJ是一个高速、安全、可拓展的区块链基础设施项目。面向5G,对IPFS底层技术深度开发及优化,通过切片技术对节点的P2P传输,实现数百兆文件的秒传。从全新的角度出发,BMJ基于区块链的分布式云存储系统设计思想提出新的方案,在数据传输方面引入数据交换机制和秒传机制来提高数据传输速度;在数据存储方面,通过采用一种高效的数据存储架构来提高数据存储效率。
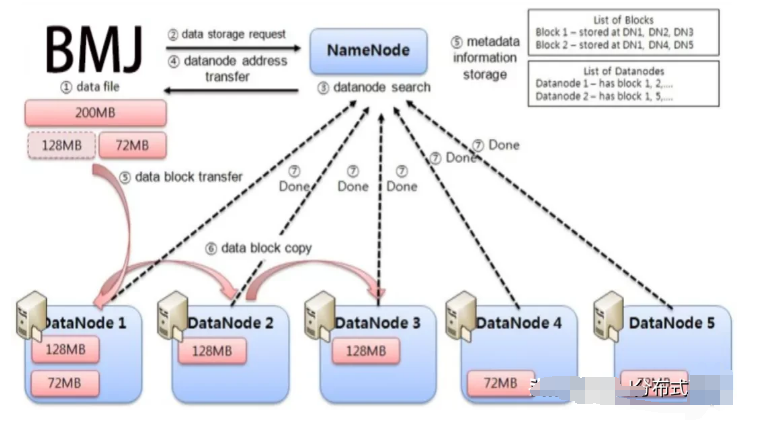
作为分布式存储的领航者,BMJ目前正在快速布局,未来形成包括云存储、云计算、大数据的产业集群,可以更好的引领传统企业升级转型,推动整个新经济的发展。
为存储而来,为服务而生,BMJ正在悄然地改变着整个世界,改变你我的生活。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号