

flume1.7---源码探索和改进--由于初学java-比较详细
一:生产碰到的问题总结
1.采集文件能否加入对于文件或者目录的一个时间判断,比如24h之前的日志不采集
2.轮转的日志不要采集。特点:inode相同,文件名不同
3.文件句柄不释放问题
4.重复采集问题
二:官方文档
第一件事是阅读官方文档,查看相应的说明。其中idleTimeout说明了,两分钟后会关闭非活动文件。带着疑问继续...

下载相关API文档,用于查看类的继承关系和方法的说明。下面放一个自己理解的关系图
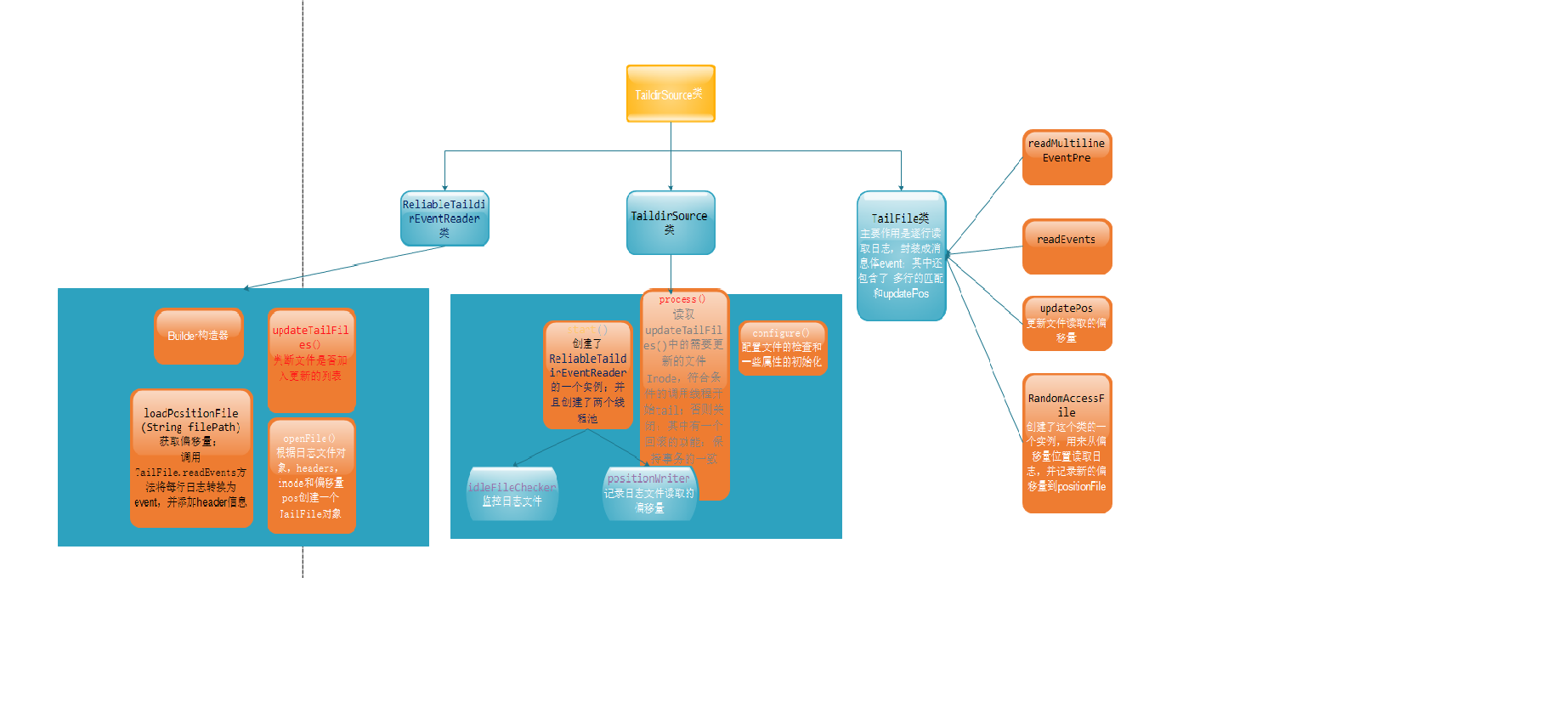
三:代码的理解:
其中定位到两个方法,一个是ReliableTaildirEventReader类下的方法public List<Long> updateTailFiles(boolean skipToEnd) throws IOException
另一个是TaildirMatcher类下的方法private static List<File> sortByLastModifiedTime(List<File> files)
先说第一个:
//判断文件是否有新文件或者已存在的文件是否有更新,返回的是一个inode的集合updatedInodes public List<Long> updateTailFiles(boolean skipToEnd) throws IOException { updateTime = System.currentTimeMillis(); List<Long> updatedInodes = Lists.newArrayList(); /*获取缓存中的taildir;taildirCache的数据类型是List<TaildirMatcher>--->找到TaildirMatcher构造器,有如下形参 (String fileGroup, String dirPath, String filePath,boolean cachePatternMatching) taildir:{filegroup='f1', filePattern='/logger/flume/xxx/escmbcxxx.log', cached=true} */ for (TaildirMatcher taildir : taildirCache) { /*taildir.getFileGroup()返回的是filegroups;headerTable的数据类型是Table<String, String, String>;Table 类找不到...,所以暂时看不到row方法,不过可以猜到:headers头部信息存放的是组和文件的绝对路径的map集合*/ Map<String, String> headers = headerTable.row(taildir.getFileGroup()); //f是实际扫描的文件 for (File f : taildir.getMatchingFiles()) {//taildir.getMatchingFiles()返回的是按最后修改时间倒序的file集合 long inode = getInode(f); //获取文件对应的inode值 if (inode == -1) continue; //tailFiles是map.hashmap的对象;返回的是:Map<Long, TailFile>;通过get方法,获取TailFile TailFile tf = tailFiles.get(inode); //tf就应该是TailFile(File file, Map<String, String> headers, long inode, long pos, Event bufferEvent) //如果tf为空,TailFile中的绝对路径名不同于file集合中的该文件的绝对路径名 if (tf == null || !tf.getPath().equals(f.getAbsolutePath())) { long startPos = skipToEnd ? f.length() : 0; //设置开始的pos值为0 tf = openFile(f, headers, inode, startPos, null); //创建一个包含该文件信息的TailFile对象 } else { //TailFile是空值的话,里面也取不到路径,更不可能和file集合中的路径相同;所以进去else的情况只有一个 //TailFile有值,后面不再判断 boolean updated = tf.getLastUpdated() < f.lastModified() || tf.getPos() != f.length(); //对比TailFile中文件的最后更新时间是否小于扫描上来的file的mtime(小就证明文件有更新)|| //pos记录的字节数不等于该文件的实际大小--->这个作用防止仅仅往后修改了文件的mtime logger.debug("File:" + tf.getPath() + ", inode:" + inode + " is updated:" + updated + ", tf.getLastUpdated()=" + tf.getLastUpdated() + ", f.lastModifed()=" + f.lastModified() + ", tf.getRaf()=null:" + (tf.getRaf()==null) + ", tf.getPos()=" + tf.getPos() + ", f.length:" + f.length()); if (updated) { if (tf.getRaf() == null) { /*tf.getRaf()返回的raf --->通过RandomAccessFile类下的seek()方法,按字节获取文件的偏移位置 并且从这之后开始读取新的内容;如果这个值为空,那么无法断点续读,只能从新开始*/ tf.close();//自己diy的;关闭的是上面的tf,下面的是新打开的tf tf = openFile(f, headers, inode, tf.getPos(), tf.getBufferEvent());//创建一个包含该文件信息的TailFile对象 } /*正常情况下一定是新扫描过得文件一定大于TailFile中缓存的文件大小;这里做了一个异常判断,就是如果相反,新扫描的文件 反而比原来缓存中记录的文件字节小了,那么肯定发生了什么错误,直接重置pos*/ if (f.length() < tf.getPos()) { logger.info("Pos " + tf.getPos() + " is larger than file size! " + "Restarting from pos 0, file: " + tf.getPath() + ", inode: " + inode + ", f.length():" + f.length()); tf.updatePos(tf.getPath(), inode, 0);//返回的是一个boolean,确定更新pos值 } } tf.setNeedTail(updated);/*(updated)为真。这段代码表示这个文件标记为需要tail;为假则不需要*/ } tailFiles.put(inode, tf); //注意作用域 updatedInodes.add(inode);//把inode添加到updatedInodes } } return updatedInodes; }
这个方法主要在判断什么文件需要加入到更新列表去读取新增的日志,所以逐行的去写了注释。我觉得这个方法中就可以修改不去读取轮转的日志
下面上自己的判断:
对于切割的日志特点:Inode相同 文件名不同 最后的修改时间大于切割前的更新时间
tf--->缓存中的日志 f--->是定期扫描的日志
boolean updated = tf.getLastUpdated() < f.lastModified() || tf.getPos() != f.length();
两种条件二选一,既满足条件。
接着来
if (updated) 为true
if (tf.getRaf() == null) 为假
if (f.length() < tf.getPos()) flume DEBUG日志中没有搜到相应的“Restarting from pos 0”的信息,所以证明轮转的没有被清0
直接进入
tf.setNeedTail(updated); --->轮转的日志需要tail
由此想到想要阻止轮转的进入update,只有找到它不同于其他正常进入update的日志属性---->文件名不同 ,所以diy了红色部分
boolean updated = tf.getLastUpdated() < f.lastModified() || tf.getPos() != f.length() ||tf.getPath().equals(f.getAbsolutePath());
接着说第二方法:
TaildirMatcher类下方法private List<File> getMatchingFilesNoCache()--->作用是根据目录,按正则表达式匹配符合的文件。
看了方法体,感觉没地方下手修改时间问题
看到了下面的方法,对上一个方法进行一个排序private static List<File> sortByLastModifiedTime(List<File> files)
private static List<File> sortByLastModifiedTime(List<File> files) { final HashMap<File, Long> lastModificationTimes = new HashMap<File, Long>(files.size()); for (File f: files) { lastModificationTimes.put(f, f.lastModified()); } Collections.sort(files, new Comparator<File>() { @Override public int compare(File o1, File o2) { return lastModificationTimes.get(o1).compareTo(lastModificationTimes.get(o2)); } }); return files; }
感觉这里好下手一些,毕竟对f.lastModified()进行了一个判断
下面上自己diy的一个判断
private static List<File> sortByLastModifiedTime(List<File> files) { final HashMap<File, Long> lastModificationTimes = new HashMap<File, Long>(files.size()); Date date = new Date(); for (File f: files) { if (f.lastModified() >= date.getTime()-86400*1000){ lastModificationTimes.put(f, f.lastModified()); }else{ files.remove(f); } } Collections.sort(files, new Comparator<File>() { @Override public int compare(File o1, File o2) { return lastModificationTimes.get(o1).compareTo(lastModificationTimes.get(o2)); } }); return files; }
仅仅做了一个判断文件的修改时间是否在24小时之内,是的按原代码进行操作,不是的话从文件列表删除。因为手敲了一下f.lastModified()的这个方法,得到的是一个长格式的毫秒。
public class DateTest {
public static void main(String[] args) {
Date date = new Date();
System.out.println(date.getTime());
System.out.println(date.getTime()-86400*1000);
File f = new File("E:\\filebeat.yml");
long last = f.lastModified();
System.out.println(last);
}
}
"C:\Program Files\Java\jdk-14.0.1\bin\java.exe" "-javaagent:C:\Program Files\JetBrains\IntelliJ IDEA 2020.1\lib\idea_rt.jar=53923:C:\Program Files\JetBrains\IntelliJ IDEA 2020.1\bin" -Dfile.encoding=UTF-8 -classpath "C:\Users\Administrator\IdeaProjects\TestProject\out\production\TextOOP;D:\E盘要满,往这放\Java Tools\commons-io-2.7\commons-io-2.7.jar;D:\E盘要满,往这放\Java Tools\mysql-connector-java-5.1.44\mysql-connector-java-5.1.44-bin.jar;D:\E盘要满,往这放\Java Tools\commons-dbutils-1.7\commons-dbutils-1.7.jar;D:\E盘要满,往这放\Java Tools\commons-dbcp2-2.7.0\commons-dbcp2-2.7.0.jar;D:\E盘要满,往这放\Java Tools\commons-pool2-2.8.1\commons-pool2-2.8.1.jar;D:\E盘要满,往这放\Java Tools\commons-logging-1.2\commons-logging-1.2.jar" com.hjs.DateTest
1599121874443
1599035474443
1592471783000
Process finished with exit code 0
通过前辈的文章了解到在类TaildirSource中有一个核心方法public Status process() ,主要作用是:读取updateTailFiles()中的需要更新的文件Inode,符合条件的调用线程开始tail;否则关闭;其中有一个回滚的功能:保持事务的一致性。
代码很长,不照搬了,里面注意到一个重要的判断 if (tf.needTail() || tf.needFlushTimeoutEvent()) ,这个就是调用了刚说的第一个方法中的结尾处的一个boolean的判断。可以推断,第一个方法的理解应该是正确的。
四:实践
因为java也是才学了2个月,接下来尝试打包替换到原有的Taidirsource的jar包,上虚拟机测试一下结果。maven依赖有点难搞,有结果了再放上来记录一下,看看是否正确。
有错误非常欢迎能指出。
努力进步!
posted on 2020-09-03 16:44 也无风雨也无qing 阅读(255) 评论(0) 编辑 收藏 举报


