
分布式session的几种解决方案
现在很多商城,都会要求用户先去登录,登录之后再往购物车中添加商品,这样用户、购物车、商品,三个对象之间就有了绑定关系。
而针对我最开始说的那种情况,其实就是基于session做的,客户端往购物车中添加第一个商品的时候,发送一个请求,服务器收到请求之后,创建session,然后返回当前session对应的一个JessionId,浏览器存储在cookie中,客户端往购物车添加第二个商品时,携带JessionId,服务端收到请求后,更新session。浏览器关闭后,cookie失效,JessionId也就丢失了,需要重新往购物车中添加商品,默认情况下,session有效期为30分钟。
在分布式环境下,session就会出现问题了,假如服务端部署在两个服务器A和B上。第一次往购物车添加商品时,请求落在了服务器A上,服务器A创建了一个session,并返回JessionId,第二次往购物车添加商品时,请求落在了服务器B上,请求携带的JesssionId在服务器B上并不会找到对应的session。这时候服务器B就会创建一个新的session,并返回对应的JessionId,客户端发现第一次添加的商品丢失了。。。
接下来,一起来学习分布式环境下session一致性是如何实现的。
一、客户端存储
既然分布式环境中,一个客户端的多个请求可能会落在多个服务器上,那么我们是否可以改变策略,直接将session信息存储在客户端?可以的,服务器将session信息直接存储到cookie中,这样就保证了session的一致性,但是并不推荐这样去做,因为将一些信息存储在cookie中,相当于就把这些信息暴露给了客户端,存在严重的安全隐患。
缺点:
- 安全性存在问题
- cookie对于数据类型及数据大小有所限制
二、session复制
将服务器A的session,复制到服务器B,同样将服务器B的session也复制到服务器A,这样两台服务器的session就一致了。像tomcat等web容器都支持session复制的功能,在同一个局域网内,一台服务器的session会广播给其他服务器。

缺点:
同一个网段内服务器太多,每个服务器都会去复制session,会造成服务器内存浪费。
三、session黏性
利用Nginx服务器的反向代理,将服务器A和服务器B进行代理,然后采用ip_hash的负载策略,将客户端和服务器进行绑定,也就是说客户端A第一次访问的是服务器B,那么第二次访问也必然是服务器B,这样就不存在session不一致的问题了。
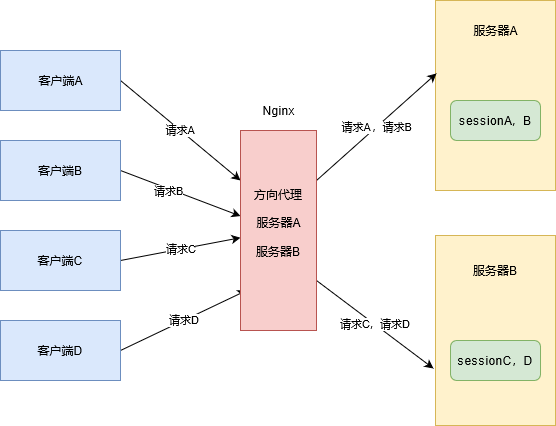
缺点:
如果服务器A宕机了,那么客户端A和客户端B的session就会出现丢失。
四、session集中管理
这种方式就是将所有服务器的session进行统一管理,可以使用redis等高性能服务器来集中管理session,而且spring官方提供的spirng-session就是这样处理session的一致性问题。这也是目前企业开发用到的比较多的一种分布式session解决方案。
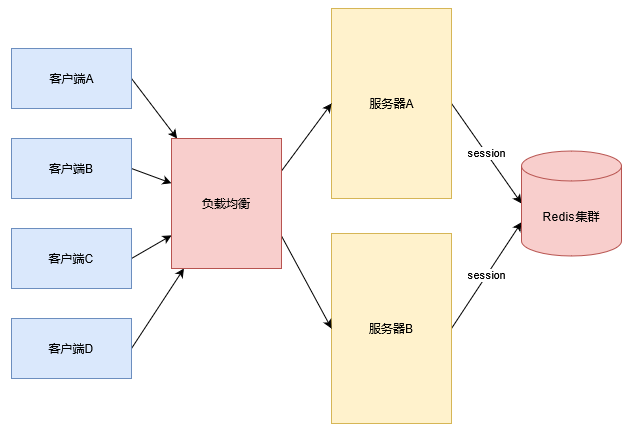
五、spring-session实战
Spring提供了处理分布式session的解决方案——Spring Session。Spring Session提供了用于管理用户会话的API和实现。
Spring Session提供了对redis,mongodb,mysql等常用的存储库的支持,Spring Session提供与HttpSession的透明整合,这意味着开发人员可以使用Spring Session支持的实现切换HttpSession实现。还是原来的配方,产生了不一样的味道!
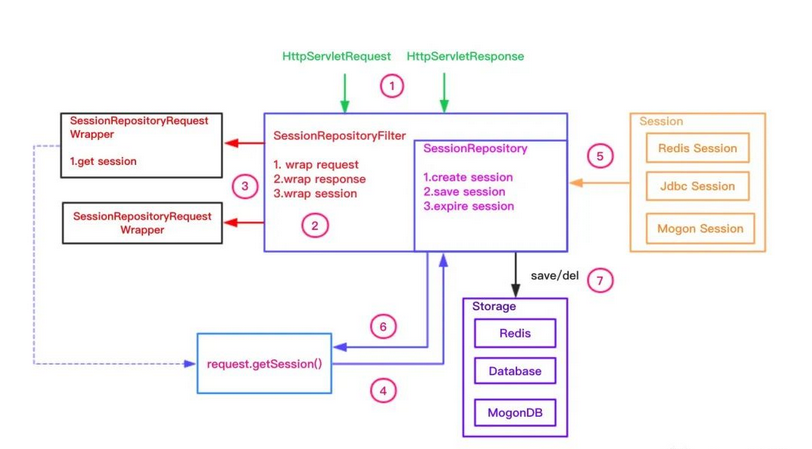
Spring Session添加了一个SessionRepositoryFilter的过滤器,用来修改包装请求和响应,包装后的请求为SessionRepositoryRequestWrapper,调用getSession()方法的时候实际上就是调用Spring Session实现了的session。
Spring Session使用非常简单,添加了相关依赖后,直接操作HttpSession就可以实现效果。
第一步:添加Spring Session和 redis的相关依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
第二步:配置redis相关信息
spring:
redis:
# redis库
database: 0
# redis 服务器地址
host: localhost
# redis 端口号
port: 6379
# redis 密码
password:
# session 使用redis存储
session:
store-type: redis
第三步:项目中使用session
public String sessionTest(HttpServletRequest request){
HttpSession session = request.getSession();
session.setAttribute("key","value");
return session.getAttribute("key").toString();
}
redis中每个session存储了三条信息。
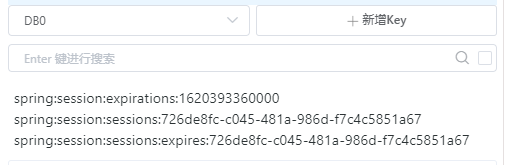
-
第一个存储这个Session的id,是一个Set类型的Redis数据结构。这个k中的最后的1439245080000值是一个时间戳,根据这个Session过期时刻滚动至下一分钟而计算得出。
-
第二个用来存储Session的详细信息,包括Session的过期时间间隔、最近的访问时间、attributes等等。这个k的过期时间为Session的最大过期时间 + 5分钟。如果默认的最大过期时间为30分钟,则这个k的过期时间为35分钟。
-
第三个用来表示Session在Redis中的过期,这个k-v不存储任何有用数据,只是表示Session过期而设置。这个k在Redis中的过期时间即为Session的过期时间间隔。
处理一个session为什么要存储三条数据,而不是一条呢!对于session的实现,需要监听它的创建、过期等事件,redis可以监听某个key的变化,当key发生变化时,可以快速做出相应的处理。
但是Redis中带有过期的key有两种方式:
- 当访问时发现其过期
- Redis后台逐步查找过期键
当访问时发现其过期,会产生过期事件,但是无法保证key的过期时间抵达后立即生成过期事件。
spring-session为了能够及时的产生Session的过期时的过期事件,所以增加了:
spring:session:sessions:expires:726de8fc-c045-481a-986d-f7c4c5851a67spring:session:expirations:1620393360000
spring-session中有个定时任务,每个整分钟都会查询相应的spring:session:expirations:整分钟的时间戳中的过期SessionId,然后再访问一次这个SessionId,即spring:session:sessions:expires:SessionId,以便能够让Redis及时的产生key过期事件——即Session过期事件。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2020-12-31 Spring 中的 bean线程安全性分析
2020-12-31 JAVA 线上问题排查方法
2020-12-31 Redis常见延迟问题定位与分析