十大排序算法
前言
你好,我是小赵,最近在系统的整理算法方面的知识,当你度过了新手阶段,想要成为牛逼的技术达人,算法是必须要掌握的东西,而算法中的排序,是每个程序员都绕不开的基本功,重要性就没必要多说了。
在工作之余坚持学习总是非常辛苦,经常不知不觉熬夜到四五点才去睡,文中的每一张图(除了最后一张,哈哈 ^_^)都是亲手所画,每一份实现代码,都是仔细测试并添加注释,当然在这个纷杂的信息世界中, 没有百分之一百的原创,免不了有的东西有所借鉴与参考。
如果你还处在新手阶段无忧无虑,请一定要尽量学一学,如果你是前辈,欢迎提一些宝贵意见。
如果你觉得喜欢,请留个评论,或者给个关注,有粉必回哈,绝不会让你有来无回,非常感谢。
本文篇幅过大,字符总数一万八千余个,配图60余张,放在书籍里已经可以写一个大章节了,强烈推荐先收藏再阅读。
冒泡排序
冒泡排序无疑是最为出名的排序算法之一,从序列的一端开始往另一端冒泡(你可以从左往右冒泡,也可以从右往左冒泡,看心情),依次比较相邻的两个数的大小(到底是比大还是比小也看你心情)。
图解冒泡
我们以[8,2,5,9,7]这组数字来做示例,上图来战:
我们从左往右依次冒泡,将小的往右移动
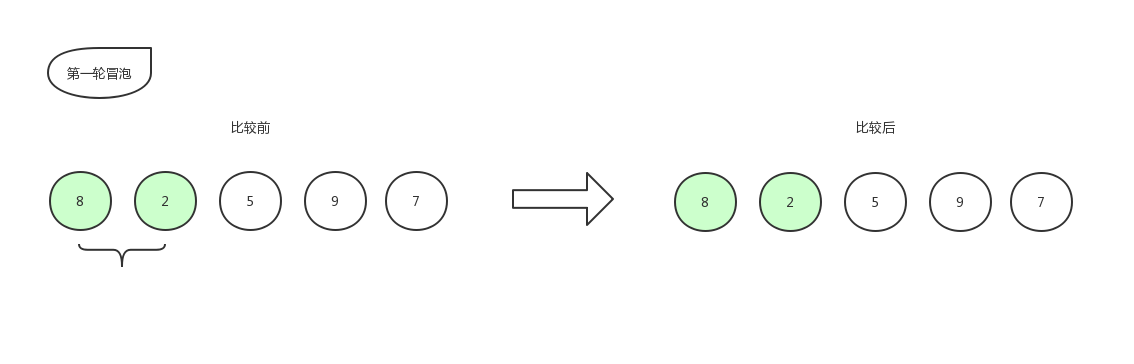
首先比较第一个数和第二个数的大小,我们发现2比8要小,那么保持原位,不做改动。位置还是8,2,5,9,7。
指针往右移动一格,接着比较:

比较第二个数和第三个数的大小,发现2比5要小,所以位置交换,交换后数组更新为:[8,5,2,9,7]。
指针再往右移动一格,继续比较:
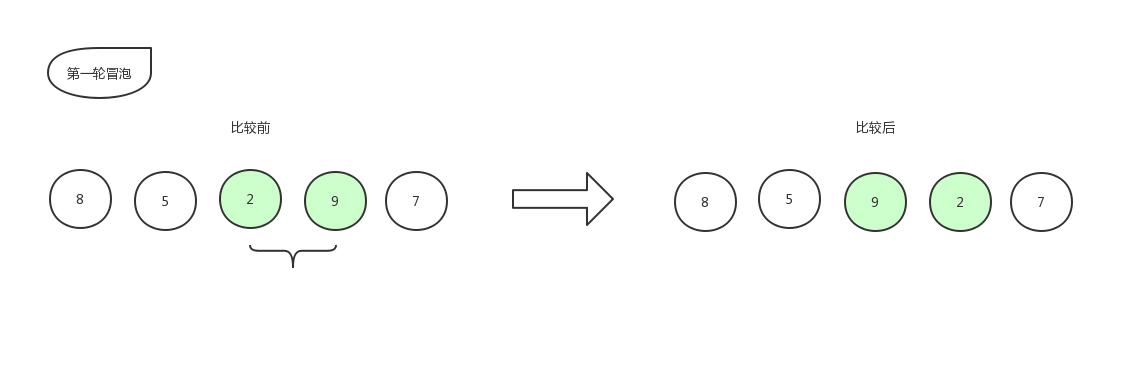
比较第三个数和第四个数的大小,发现2比9要小,所以位置交换,交换后数组更新为:[8,5,9,2,7]
同样,指针再往右移动,继续比较:

比较第4个数和第5个数的大小,发现2比7要小,所以位置交换,交换后数组更新为:[8,5,9,7,2]
下一步,指针再往右移动,发现已经到底了,则本轮冒泡结束,处于最右边的2就是已经排好序的数字。
通过这一轮不断的对比交换,数组中最小的数字移动到了最右边。
接下来继续第二轮冒泡:
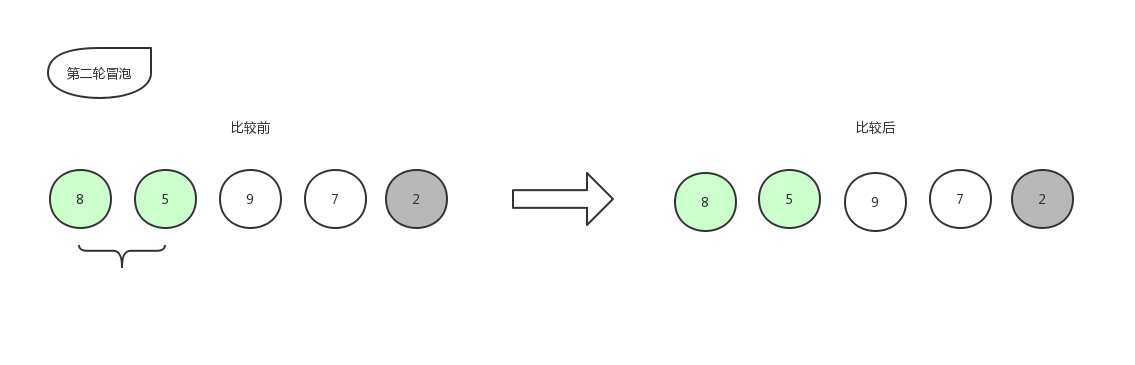
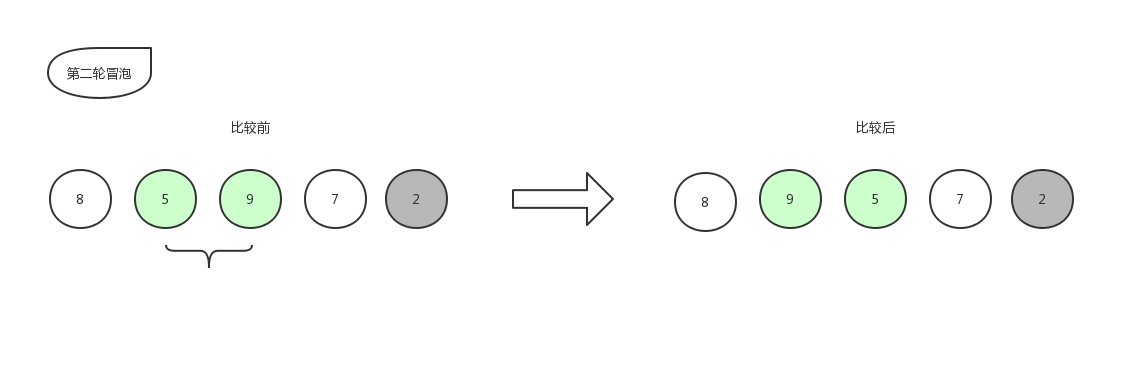
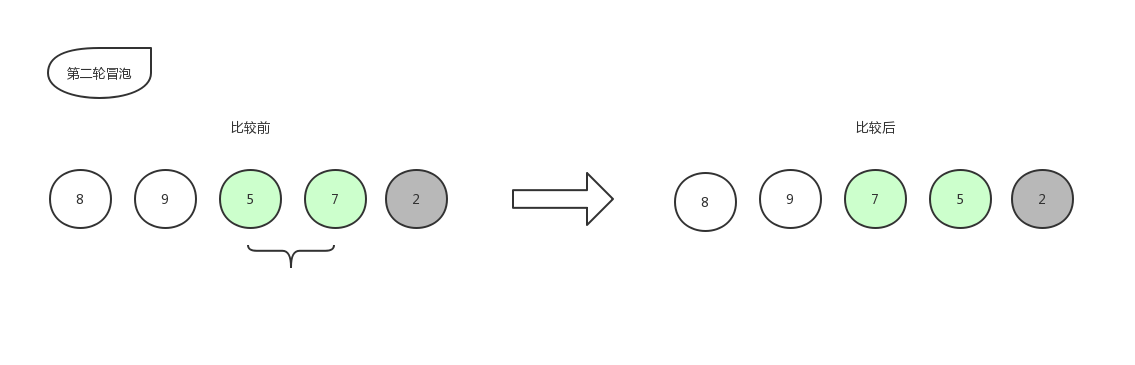
由于右边的2已经是排好序的数字,就不再参与比较,所以本轮冒泡结束,本轮冒泡最终冒到顶部的数字5也归于有序序列中,现在数组已经变化成了[8,9,7,5,2]。
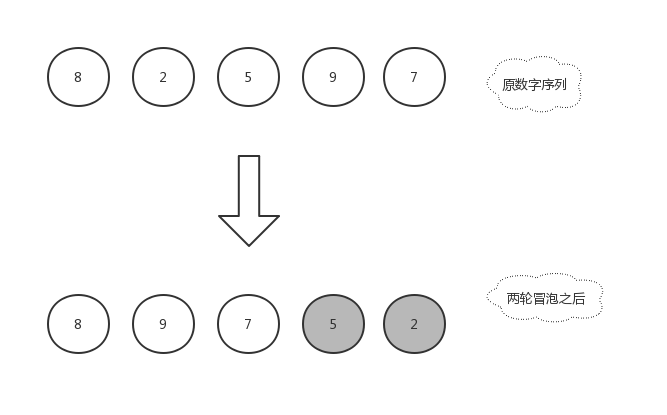
让我们开始第三轮冒泡吧!
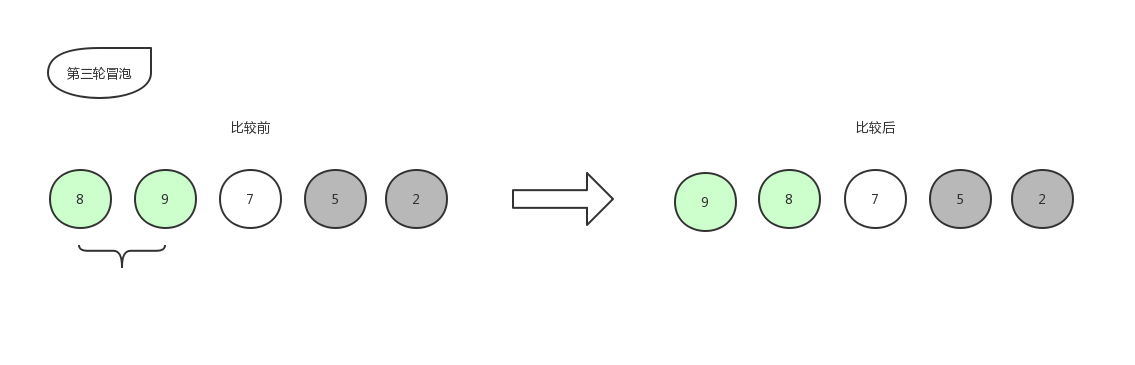

由于8比7大,所以位置不变,此时第三轮冒泡也已经结束,第三轮冒泡的最后结果是[9,8,7,5,2]
紧接着第四轮冒泡:
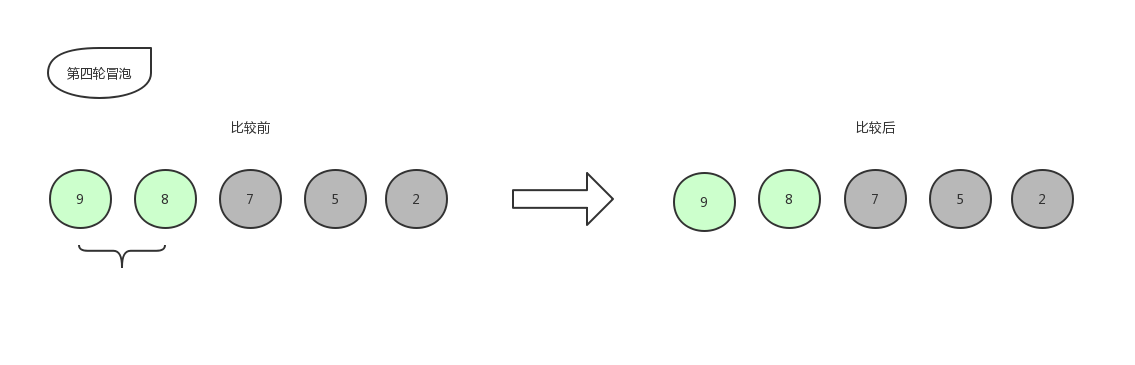
9和8比,位置不变,即确定了8进入有序序列,那么最后只剩下一个数字9,放在末尾,自此排序结束。
代码实现

public static void sort(int arr[]) { for(int i=0;i<arr.length-1;i++){ for(int j=0;j<arr.length-1-i;j++){ int temp = 0; if(arr[j] < arr[j+1]){ temp = arr[j]; arr[j] = arr[j+1]; arr[j+1] = temp; } } } }
冒泡的代码还是相当简单的,两层循环,外层冒泡轮数,里层依次比较,江湖中人人尽皆知。
我们看到嵌套循环,应该立马就可以得出这个算法的时间复杂度为O(n^2)。
冒泡优化
冒泡有一个最大的问题就是这种算法不管不管你有序还是没序,闭着眼睛把你循环比较了再说。
比如我举个数组例子:[9,8,7,6,5],一个有序的数组,根本不需要排序,它仍然是双层循环一个不少的把数据遍历干净,这其实就是做了没必要做的事情,属于浪费资源。
针对这个问题,我们可以设定一个临时遍历来标记该数组是否已经有序,如果有序了就不用遍历了。
public static void sort(int arr[]) { for(int i=0;i<arr.length-1;i++){ boolean isSort = true; for(int j=0;j<arr.length-1-i;j++){ int temp = 0; if(arr[j] < arr[j+1]){ temp = arr[j]; arr[j] = arr[j+1]; arr[j+1] = temp; isSort = false; } } if(isSort){ break; } } }
选择排序
选择排序的思路是这样的:首先,找到数组中最小的元素,拎出来,将它和数组的第一个元素交换位置,第二步,在剩下的元素中继续寻找最小的元素,拎出来,和数组的第二个元素交换位置,如此循环,直到整个数组排序完成。
至于选大还是选小,这个都无所谓,你也可以每次选择最大的拎出来排,也可以每次选择最小的拎出来的排,只要你的排序的手段是这种方式,都叫选择排序。
图解选排
我们还是以[8,2,5,9,7]这组数字做例子。
第一次选择,先找到数组中最小的数字2,然后和第一个数字交换位置。(如果第一个数字就是最小值,那么自己和自己交换位置,也可以不做处理,就是一个if的事情)
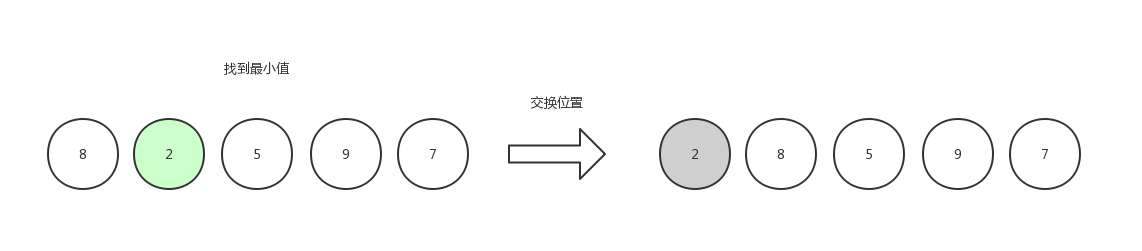
第二次选择,由于数组第一个位置已经是有序的,所以只需要查找剩余位置,找到其中最小的数字5,然后和数组第二个位置的元素交换。

第三次选择,找到最小值7,和第三个位置的元素交换位置。

第四次选择,找到最小值8,和第四个位置的元素交换位置。

最后一个到达了数组末尾,没有可对比的元素,结束选择。
如此整个数组就排序完成了。
代码实现
public static void sort(int arr[]) { for(int i=0;i<arr.length;i++){ int min = i;//最小元素的下标 for(int j=i+1;j<arr.length;j++){ if(arr[j] < arr[min]){ min = j;//找最小值 } } //交换位置 int temp = arr[i]; arr[i] = arr[min]; arr[min] = temp; } }
双层循环,时间复杂度和冒泡一模一样,都是O(n^2)
插入排序
插入排序的思想和我们打扑克摸牌的时候一样,从牌堆里一张一张摸起来的牌都是乱序的,我们会把摸起来的牌插入到左手中合适的位置,让左手中的牌时刻保持一个有序的状态。
那如果我们不是从牌堆里摸牌,而是左手里面初始化就是一堆乱牌呢? 一样的道理,我们把牌往手的右边挪一挪,把手的左边空出一点位置来,然后在乱牌中抽一张出来,插入到左边,再抽一张出来,插入到左边,再抽一张,插入到左边,每次插入都插入到左边合适的位置,时刻保持左边的牌是有序的,直到右边的牌抽完,则排序完毕。
图解插入
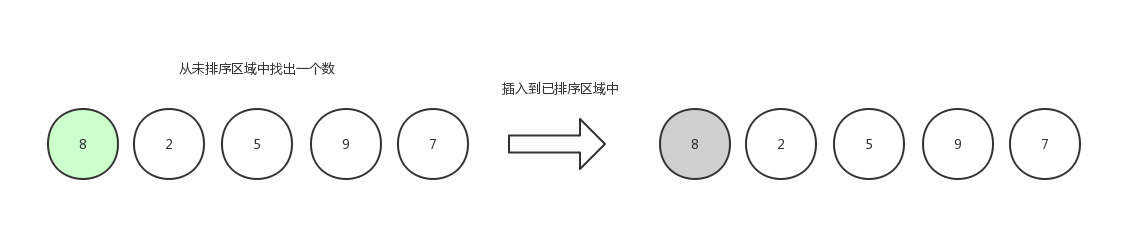
数组初始化:[8,2,5,9,7],我们把数组中的数据分成两个区域,已排序区域和未排序区域,初始化的时候所有的数据都处在未排序区域中,已排序区域是空。
第一轮,从未排序区域中随机拿出一个数字,既然是随机,那么我们就获取第一个,然后插入到已排序区域中,已排序区域是空,那么就不做比较,默认自身已经是有序的了。(当然了,第一轮在代码中是可以省略的,从下标为1的元素开始即可)
第二轮,继续从未排序区域中拿出一个数,插入到已排序区域中,这个时候要遍历已排序区域中的数字挨个做比较,比大比小取决于你是想升序排还是想倒序排,这里排升序:

第三轮,排5:
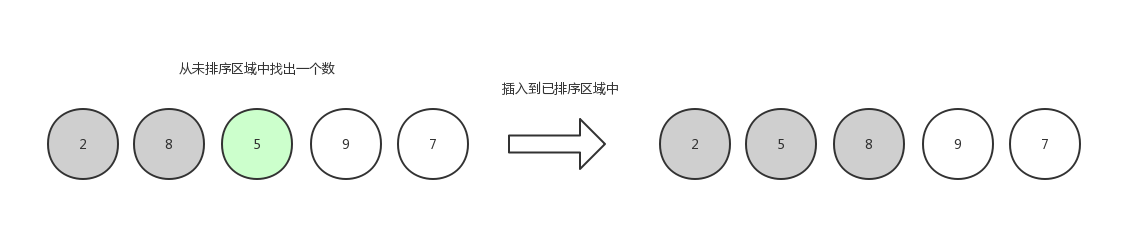
第四轮,排9:

第五轮,排7

排序结束。
代码实现
我们来看一下插入排序的代码实现
public static void sort(int[] arr) { int n = arr.length; for (int i = 1; i < n; ++i) { int value = arr[i]; int j = 0;//插入的位置 for (j = i-1; j >= 0; j--) { if (arr[j] > value) { arr[j+1] = arr[j];//移动数据 } else { break; } } arr[j+1] = value; //插入数据 } }
从代码里我们可以看出,如果找到了合适的位置,就不会再进行比较了,就好比牌堆里抽出的一张牌本身就比我手里的牌都小,那么我只需要直接放在末尾就行了,不用一个一个去移动数据腾出位置插入到中间。
所以说,最好情况的时间复杂度是O(n),最坏情况的时间复杂度是O(n^2),然而时间复杂度这个指标看的是最坏的情况,而不是最好的情况,所以插入排序的时间复杂度是O(n^2)。
希尔排序
希尔排序这个名字,来源于它的发明者希尔,也称作“缩小增量排序”,是插入排序的一种更高效的改进版本。
我们知道,插入排序对于大规模的乱序数组的时候效率是比较慢的,因为它每次只能将数据移动一位,希尔排序为了加快插入的速度,让数据移动的时候可以实现跳跃移动,节省了一部分的时间开支。
图解希尔
待排序数组 10个数据:
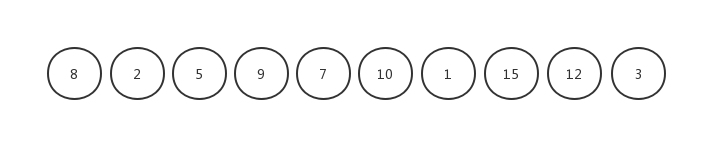
假设计算出的排序区间为4,那么我们第一次比较应该是用第5个数据与第1个数据相比较。
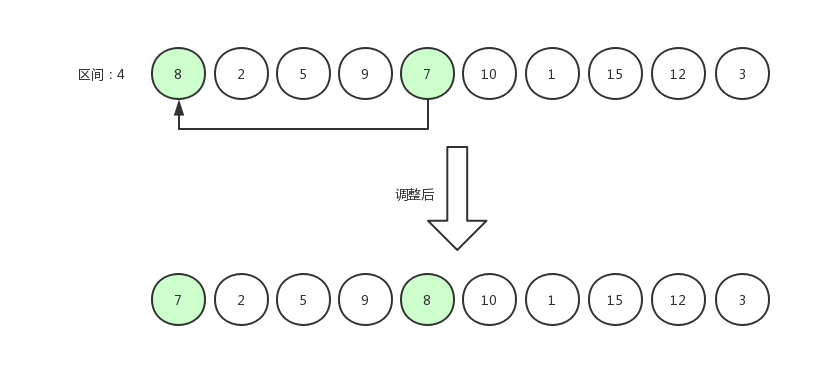
调换后的数据为[7,2,5,9,8,10,1,15,12,3],然后指针右移,第6个数据与第2个数据相比较。
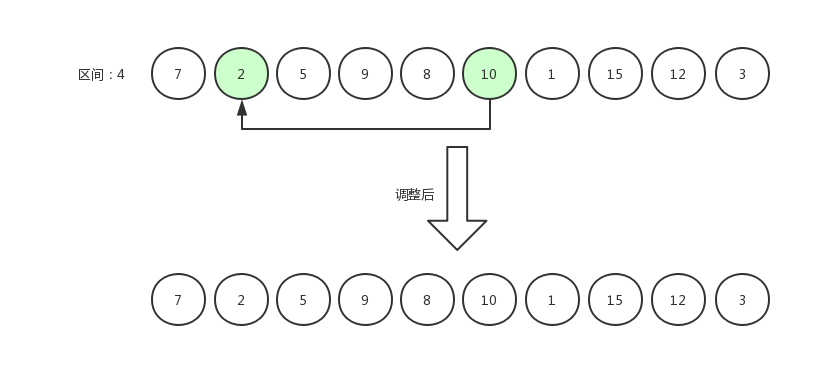
指针右移,继续比较。

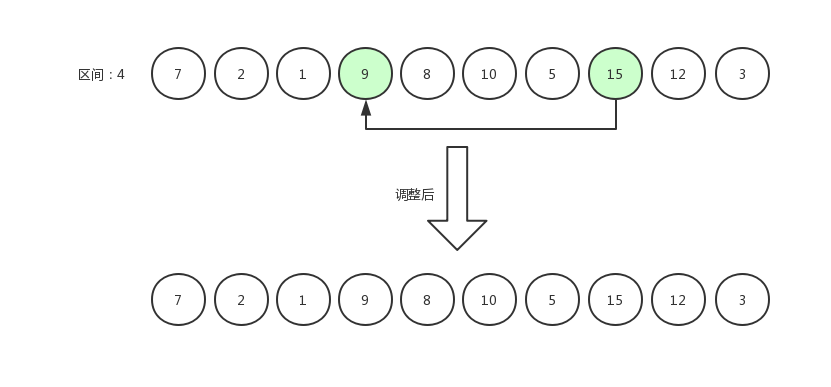
如果交换数据后,发现减去区间得到的位置还存在数据,那么继续比较,比如下面这张图,12和8相比较,原地不动后,指针从12跳到8身上,继续减去区间发现前面还有一个下标为0的数据7,那么8和7相比较。
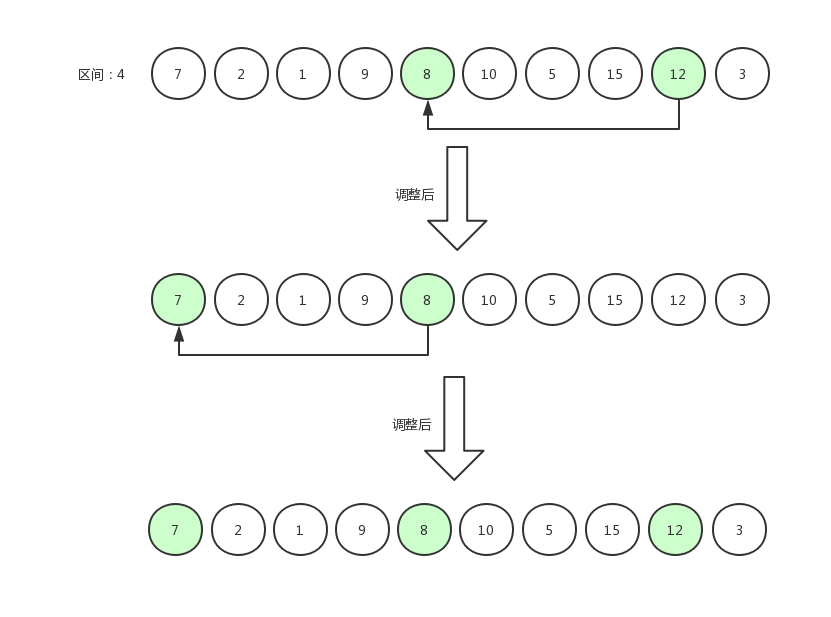
比较完之后的效果是7,8,12三个数为有序排列。
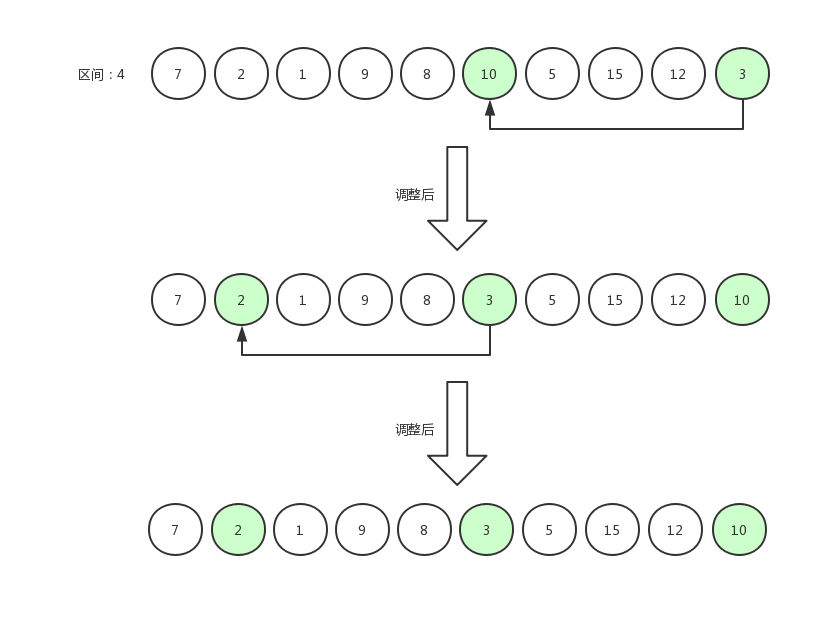
当最后一个元素比较完之后,我们会发现大部分值比较大的数据都似乎调整到数组的中后部分了。
假设整个数组比较长的话,比如有100个数据,那么我们的区间肯定是四五十,调整后区间再缩小成一二十还会重新调整一轮,直到最后区间缩小为1,就是真正的排序来了。
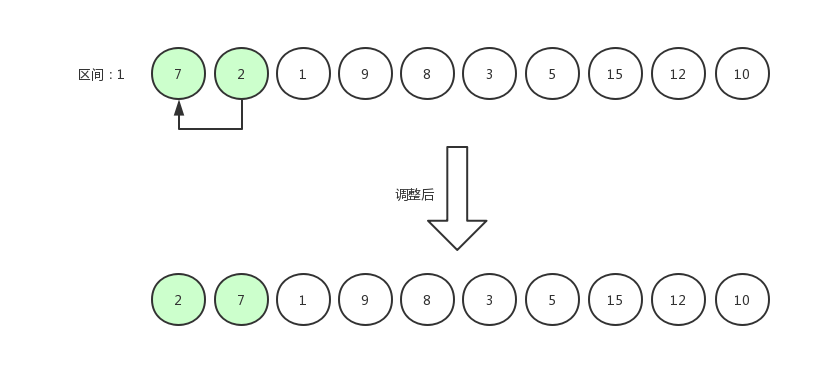
指针右移,继续比较:

重复步骤,即可完成排序,重复的图就不多画了。
我们可以发现,当区间为1的时候,它使用的排序方式就是插入排序。
代码实现
public static void sort(int[] arr) { int length = arr.length; //区间 int gap = 1; while (gap < length) { gap = gap * 3 + 1; } while (gap > 0) { for (int i = gap; i < length; i++) { int tmp = arr[i]; int j = i - gap; //跨区间排序 while (j >= 0 && arr[j] > tmp) { arr[j + gap] = arr[j]; j -= gap; } arr[j + gap] = tmp; } gap = gap / 3; } }
可能你会问为什么区间要以gap=gap*3+1去计算,其实最优的区间计算方法是没有答案的,这是一个长期未解决的问题,不过差不多都会取在二分之一到三分之一附近。
归并排序
归并字面上的意思是合并,归并算法的核心思想是分治法,就是将一个数组一刀切两半,递归切,直到切成单个元素,然后重新组装合并,单个元素合并成小数组,两个小数组合并成大数组,直到最终合并完成,排序完毕。
图解归并
我们以[8,2,5,9,7]这组数字来举例
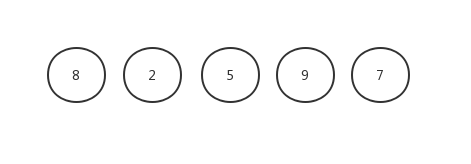
首先,一刀切两半:

再切:
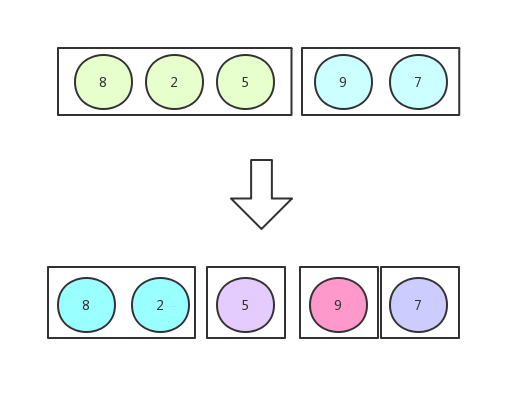
再切
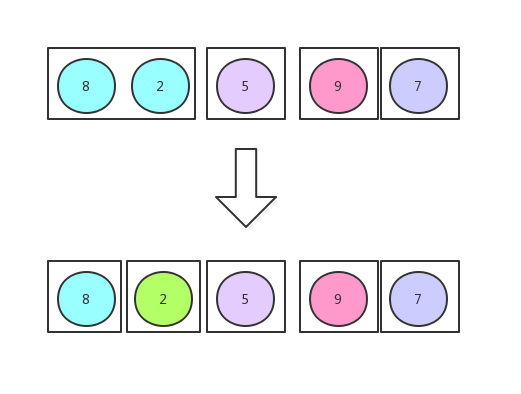
粒度切到最小的时候,就开始归并

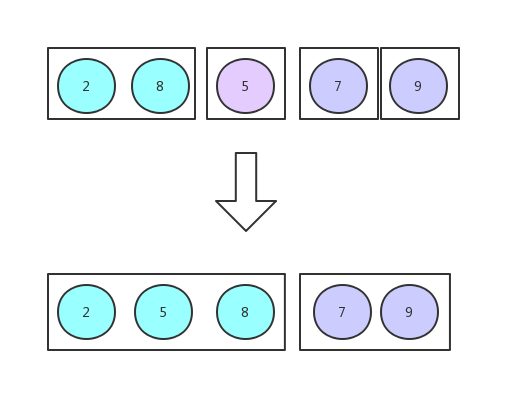
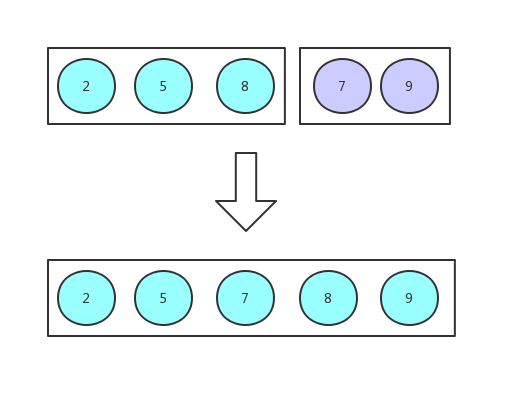
数据量设定的比较少,是为了方便图解,数据量为单数,是为了让你看到细节,下面我画了一张更直观的图可能你会更喜欢:
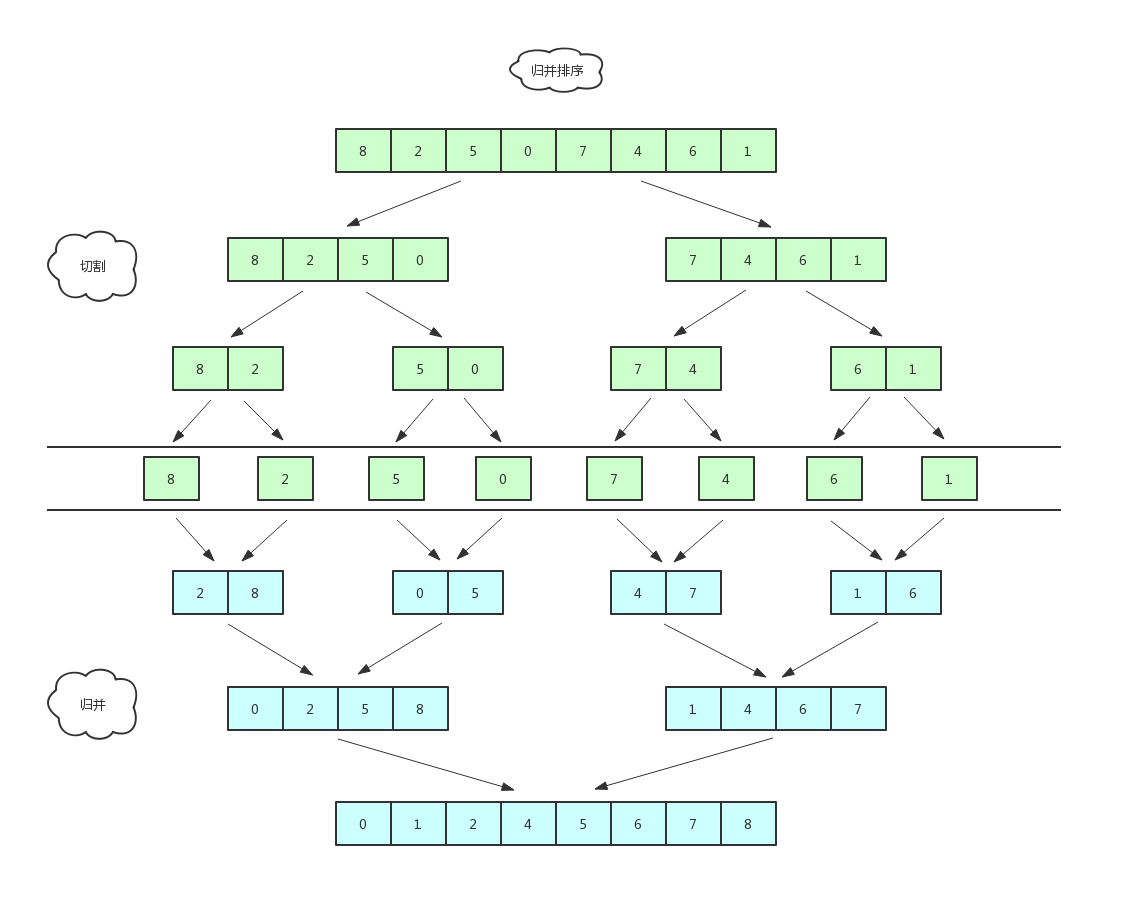
代码实现
我们上面讲过,归并排序的核心思想是分治,分而治之,将一个大问题分解成无数的小问题进行处理,处理之后再合并,这里我们采用递归来实现:
/** * 归并排序 * @param arr */ public static void sort(int[] arr) { int[] tempArr = new int[arr.length]; sort(arr, tempArr, 0, arr.length-1); } /** * 归并排序 * @param arr 排序数组 * @param tempArr 临时存储数组 * @param startIndex 排序起始位置 * @param endIndex 排序终止位置 */ private static void sort(int[] arr,int[] tempArr,int startIndex,int endIndex){ if(endIndex <= startIndex){ return; } //中部下标 int middleIndex = startIndex + (endIndex - startIndex) / 2; //分解 sort(arr,tempArr,startIndex,middleIndex); sort(arr,tempArr,middleIndex + 1,endIndex); //归并 merge(arr,tempArr,startIndex,middleIndex,endIndex); } /** * 归并 * @param arr 排序数组 * @param tempArr 临时存储数组 * @param startIndex 归并起始位置 * @param middleIndex 归并中间位置 * @param endIndex 归并终止位置 */ private static void merge(int[] arr, int[] tempArr, int startIndex, int middleIndex, int endIndex) { //复制要合并的数据 for (int s = startIndex; s <= endIndex; s++) { tempArr[s] = arr[s]; } int left = startIndex;//左边首位下标 int right = middleIndex + 1;//右边首位下标 for (int k = startIndex; k <= endIndex; k++) { if(left > middleIndex){ //如果左边的首位下标大于中部下标,证明左边的数据已经排完了。 arr[k] = tempArr[right++]; } else if (right > endIndex){ //如果右边的首位下标大于了数组长度,证明右边的数据已经排完了。 arr[k] = tempArr[left++]; } else if (tempArr[right] < tempArr[left]){ arr[k] = tempArr[right++];//将右边的首位排入,然后右边的下标指针+1。 } else { arr[k] = tempArr[left++];//将左边的首位排入,然后左边的下标指针+1。 } } }
我们可以发现merge方法中只有一个for循环,直接就可以得出每次合并的时间复杂度为O(n),而分解数组每次对半切割,属于对数时间O(log n),合起来等于O(log2n),也就是说,总的时间复杂度为O(nlogn)。
关于空间复杂度,其实大部分人写的归并都是在merge方法里面申请临时数组,用临时数组来辅助排序工作,空间复杂度为O(n),而我这里做的是原地归并,只在最开始申请了一个临时数组,所以空间复杂度为O(1)。
快速排序
快速排序的核心思想也是分治法,分而治之。它的实现方式是每次从序列中选出一个基准值,其他数依次和基准值做比较,比基准值大的放右边,比基准值小的放左边,然后再对左边和右边的两组数分别选出一个基准值,进行同样的比较移动,重复步骤,直到最后都变成单个元素,整个数组就成了有序的序列。
图解快排
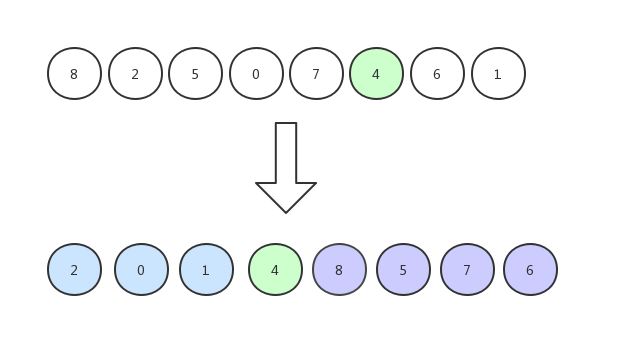
我们以[8,2,5,0,7,4,6,1]这组数字来进行演示
首先,我们随机选择一个基准值:

与其他元素依次比较,大的放右边,小的放左边:
然后我们以同样的方式排左边的数据:

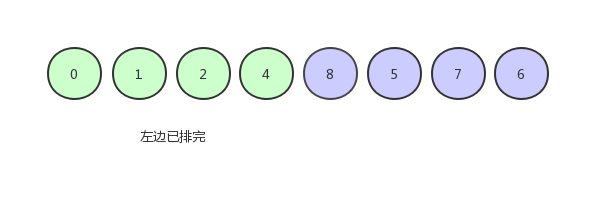
继续排0和1:

由于只剩下一个数,所以就不用排了,现在的数组序列是下图这个样子:
右边以同样的操作进行,即可排序完成。
单边扫描
快速排序的关键之处在于切分,切分的同时要进行比较和移动,这里介绍一种叫做单边扫描的做法。
我们随意抽取一个数作为基准值,同时设定一个标记mark代表左边序列最右侧的下标位置,当然初始为0,接下来遍历数组,如果元素大于基准值,无操作,继续遍历,如果元素小于基准值,则把mark+1,再将mark所在位置的元素和遍历到的元素交换位置,mark这个位置存储的是比基准值小的数据,当遍历结束后,将基准值与mark所在元素交换位置即可。
代码实现:
public static void sort(int[] arr) { sort(arr, 0, arr.length - 1); } private static void sort(int[] arr, int startIndex, int endIndex) { if (endIndex <= startIndex) { return; } //切分 int pivotIndex = partitionV2(arr, startIndex, endIndex); sort(arr, startIndex, pivotIndex-1); sort(arr, pivotIndex+1, endIndex); } private static int partition(int[] arr, int startIndex, int endIndex) { int pivot = arr[startIndex];//取基准值 int mark = startIndex;//Mark初始化为起始下标 for(int i=startIndex+1; i<=endIndex; i++){ if(arr[i]<pivot){ //小于基准值 则mark+1,并交换位置。 mark ++; int p = arr[mark]; arr[mark] = arr[i]; arr[i] = p; } } //基准值与mark对应元素调换位置 arr[startIndex] = arr[mark]; arr[mark] = pivot; return mark; }
双边扫描
另外还有一种双边扫描的做法,看起来比较直观:我们随意抽取一个数作为基准值,然后从数组左右两边进行扫描,先从左往右找到一个大于基准值的元素,将下标指针记录下来,然后转到从右往左扫描,找到一个小于基准值的元素,交换这两个元素的位置,重复步骤,直到左右两个指针相遇,再将基准值与左侧最右边的元素交换。
我们来看一下实现代码,不同之处只有partition方法:
public static void sort(int[] arr) { sort(arr, 0, arr.length - 1); } private static void sort(int[] arr, int startIndex, int endIndex) { if (endIndex <= startIndex) { return; } //切分 int pivotIndex = partition(arr, startIndex, endIndex); sort(arr, startIndex, pivotIndex-1); sort(arr, pivotIndex+1, endIndex); } private static int partition(int[] arr, int startIndex, int endIndex) { int left = startIndex; int right = endIndex; int pivot = arr[startIndex];//取第一个元素为基准值 while (true) { //从左往右扫描 while (arr[left] <= pivot) { left++; if (left == right) { break; } } //从右往左扫描 while (pivot < arr[right]) { right--; if (left == right) { break; } } //左右指针相遇 if (left >= right) { break; } //交换左右数据 int temp = arr[left]; arr[left] = arr[right]; arr[right] = temp; } //将基准值插入序列 int temp = arr[startIndex]; arr[startIndex] = arr[right]; arr[right] = temp; return right; }
极端情况
快速排序的时间复杂度和归并排序一样,O(n log n),但这是建立在每次切分都能把数组一刀切两半差不多大的前提下,如果出现极端情况,比如排一个有序的序列,如[9,8,7,6,5,4,3,2,1],选取基准值9,那么需要切分n-1次才能完成整个快速排序的过程,这种情况下,时间复杂度就退化成了O(n^2),当然极端情况出现的概率也是比较低的。
所以说,快速排序的时间复杂度是O(nlogn),极端情况下会退化成O(n^2),为了避免极端情况的发生,选取基准值应该做到随机选取,或者是打乱一下数组再选取。
另外,快速排序的空间复杂度为O(1)。
堆排序
堆排序顾名思义,是利用堆这种数据结构来进行排序的算法。
如果你了解堆这种数据结构,你应该知道堆是一种优先队列,两种实现,最大堆和最小堆,由于我们这里排序按升序排,所以就直接以最大堆来说吧。
我们完全可以把堆(以下全都默认为最大堆)看成一棵完全二叉树,但是位于堆顶的元素总是整棵树的最大值,每个子节点的值都比父节点小,由于堆要时刻保持这样的规则特性,所以一旦堆里面的数据发生变化,我们必须对堆重新进行一次构建。
既然堆顶元素永远都是整棵树中的最大值,那么我们将数据构建成堆后,只需要从堆顶取元素不就好了吗? 第一次取的元素,是否取的就是最大值?取完后把堆重新构建一下,然后再取堆顶的元素,是否取的就是第二大的值? 反复的取,取出来的数据也就是有序的数据。
图解堆排
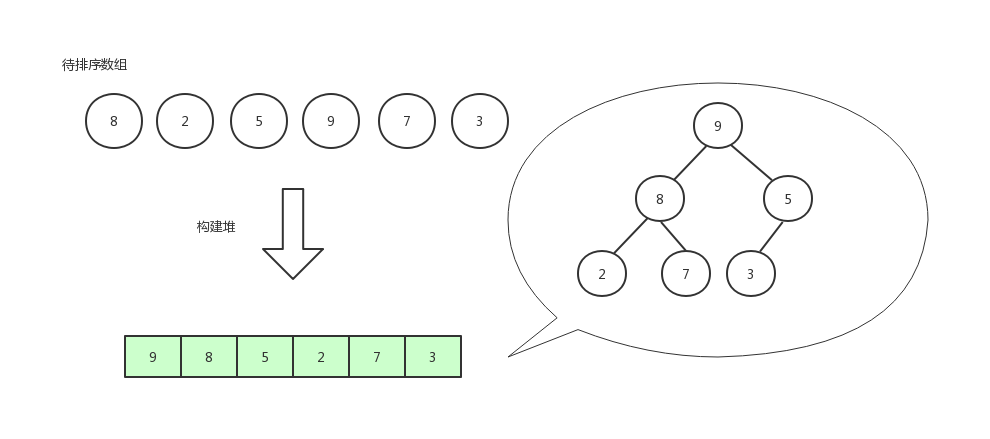
我们以[8,2,5,9,7,3]这组数据来演示。
首先,将数组构建成堆。
既然构建成堆结构了,那么接下来,我们取出堆顶的数据,也就是数组第一个数,9,取法是将数组的第一位和最后一位调换,然后将数组的待排序范围-1,
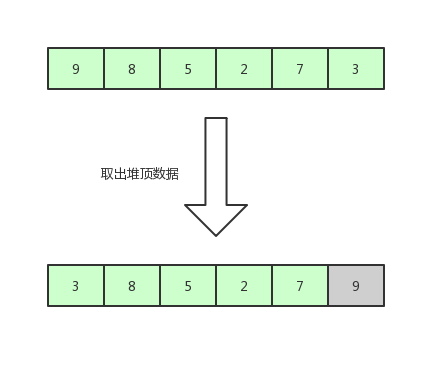
现在的待排序数据是[3,8,5,2,7],我们继续将待排序数据构建成堆。

取出堆顶数据,这次就是第一位和倒数第二位交换了,因为待排序的边界已经减1。

继续构建堆
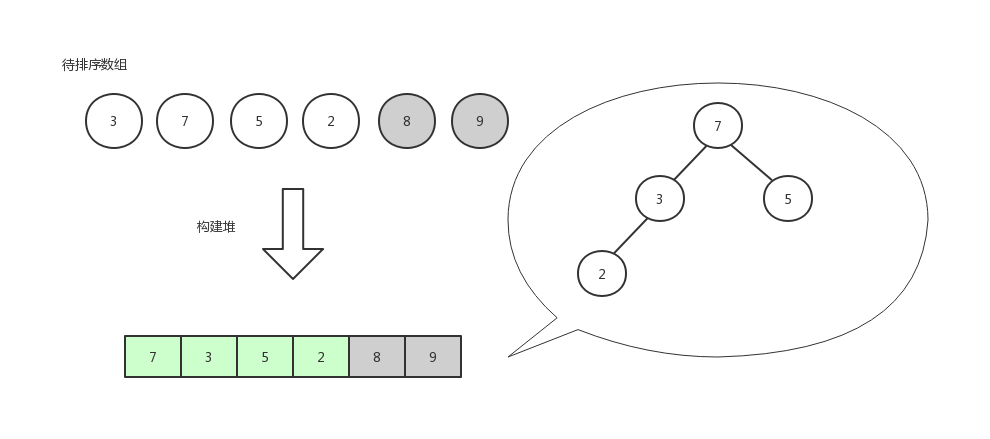
从堆顶取出来的数据最终形成一个有序列表,重复的步骤就不再赘述了,我们来看一下代码实现。
代码实现
如果你对堆这个数据结构不熟悉,不太理解代码,那么我建议你打断点,一行一行的观察数据的变化,伴随着注释说明,你肯定会豁然开朗。
/** * 堆排序 * @param arr 排序数组 */ public static void sort(int[] arr) { int length = arr.length; //构建堆 buildHeap(arr, length); for (int i = length - 1; i > 0; i--) { //将堆顶元素与末位元素调换 int temp = arr[0]; arr[0] = arr[i]; arr[i] = temp; //数组长度-1 隐藏堆尾元素 length--; //将堆顶元素下沉 目的是将最大的元素浮到堆顶来 sink(arr, 0, length); } } /** * 构建堆 * @param arr 数组 * @param length 数组范围 */ private static void buildHeap(int[] arr, int length) { for (int i = length / 2; i >= 0; i--) { sink(arr, i, length); } } /** * 下沉调整 * @param arr 数组 * @param index 调整位置 * @param length 数组范围 */ private static void sink(int[] arr, int index, int length) { int leftChild = 2 * index + 1;//左子节点下标 int rightChild = 2 * index + 2;//右子节点下标 int present = index;//要调整的节点下标 //下沉左边 if (leftChild < length && arr[leftChild] > arr[present]) { present = leftChild; } //下沉右边 if (rightChild < length && arr[rightChild] > arr[present]) { present = rightChild; } //如果下标不相等 证明调换过了 if (present != index) { //交换值 int temp = arr[index]; arr[index] = arr[present]; arr[present] = temp; //继续下沉 sink(arr, present, length); } }
堆排序和快速排序的时间复杂度都一样是O(nlogn)。
计数排序
计数排序是一种非基于比较的排序算法,我们之前介绍的各种排序算法几乎都是基于元素之间的比较来进行排序的,计数排序的时间复杂度为O(n+m),m指的是数据量,说的简单点,计数排序算法的时间复杂度约等于O(n),快于任何比较型的排序算法。
图解计数
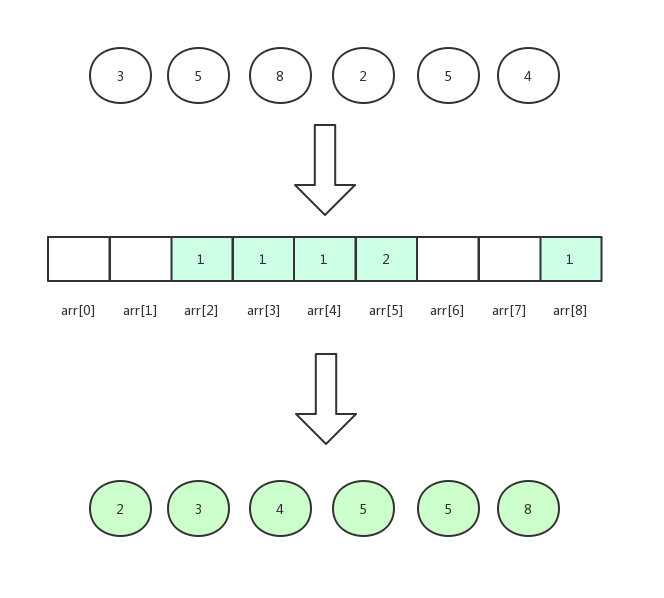
以下以[3,5,8,2,5,4]这组数字来演示。
首先,我们找到这组数字中最大的数,也就是8,创建一个最大下标为8的空数组arr。
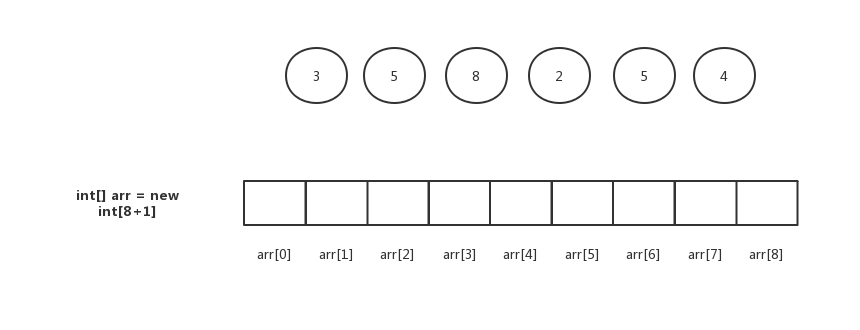
遍历数据,将数据的出现次数填入arr中对应的下标位置中。
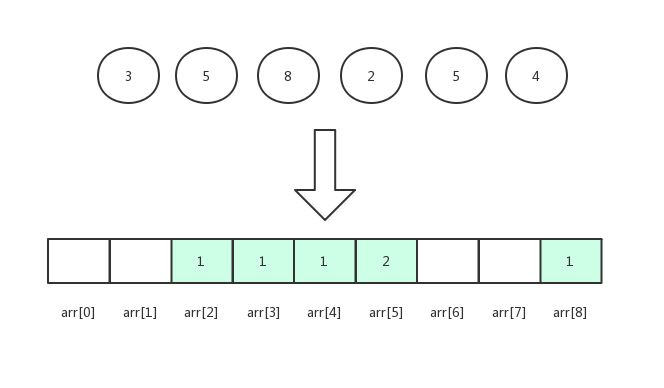
遍历arr,将数据依次取出即可。
代码实现
public static void sort(int[] arr) { //找出数组中的最大值 int max = arr[0]; for (int i = 1; i < arr.length; i++) { if (arr[i] > max) { max = arr[i]; } } //初始化计数数组 int[] countArr = new int[max + 1]; //计数 for (int i = 0; i < arr.length; i++) { countArr[arr[i]]++; arr[i] = 0; } //排序 int index = 0; for (int i = 0; i < countArr.length; i++) { if (countArr[i] > 0) { arr[index++] = i; } } }
稳定排序
有一个需求就是当对成绩进行排名次的时候,如何在原来排前面的人,排序后还是处于相同成绩的人的前面。
解题的思路是对countArr计数数组进行一个变形,变来和名次挂钩,我们知道countArr存放的是分数的出现次数,那么其实我们可以算出每个分数的最大名次,就是将countArr中的每个元素顺序求和。
如下图:
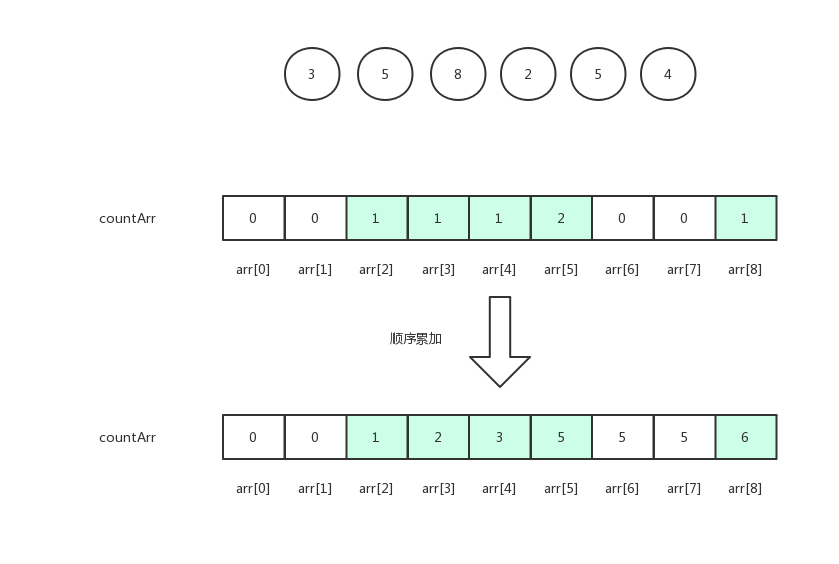
变形之后是什么意思呢?
我们把原数组[2,5,8,2,5,4]中的数据依次拿来去countArr去找,你会发现3这个数在countArr[3]中的值是2,代表着排名第二名,(因为第一名是最小的2,对吧?),5这个数在countArr[5]中的值是5,为什么是5呢?我们来数数,排序后的数组应该是[2,3,4,5,5,8],5的排名是第五名,那4的排名是第几名呢?对应countArr[4]的值是3,第三名,5的排名是第五名是因为5这个数有两个,自然占据了第4名和第5名。
所以我们取排名的时候应该特别注意,原数组中的数据要从右往左取,从countArr取出排名后要把countArr中的排名减1,以便于再次取重复数据的时候排名往前一位。
啊哦,图都画完了才发现我的排名是按升序来排的,竟然有这种排分数的逻辑,尴尬。
下面是代码实现:
public static void sort(int[] arr) { //找出数组中的最大值 int max = arr[0]; for (int i = 1; i < arr.length; ++i) { if (arr[i] > max) { max = arr[i]; } } //初始化计数数组 int[] countArr = new int[max + 1]; //计数 for (int i = 0; i < arr.length; ++i) { countArr[arr[i]]++; } //顺序累加 for (int i = 1; i < max + 1; ++i) { countArr[i] = countArr[i-1] + countArr[i]; } //排序后的数组 int[] sortedArr = new int[arr.length]; //排序 for (int i = arr.length - 1; i >= 0; --i) { sortedArr[countArr[arr[i]]-1] = arr[i]; countArr[arr[i]]--; } //将排序后的数据拷贝到原数组 for (int i = 0; i < arr.length; ++i) { arr[i] = sortedArr[i]; } }
计数局限性
计数排序的毛病很多,我们来找找bug。
如果我要排的数据里有0呢? int[]初始化内容全是0,排毛线。
如果我要排的数据范围比较大呢?比如[1,9999],我排两个数你要创建一个int[10000]的数组来计数?
对于第一个bug,我们可以使用偏移量来解决,比如我要排[-1,0,-3]这组数字,这个简单,我全给你们加10来计数,变成[9,10,7]计完数后写回原数组时再减10。不过有可能也会踩到坑,万一你数组里恰好有一个-10,你加上10后又变0了,排毛线。
对于第二个bug,确实解决不了,如果是[9998,9999]这种虽然值大但是相差范围不大的数据我们也可以使用偏移量解决,比如这两个数据,我减掉9997后只需要申请一个int[3]的数组就可以进行计数。
由此可见,计数排序只适用于正整数并且取值范围相差不大的数组排序使用,它的排序的速度是非常可观的。
桶排序
桶排序可以看成是计数排序的升级版,它将要排的数据分到多个有序的桶里,每个桶里的数据再单独排序,再把每个桶的数据依次取出,即可完成排序。
图解桶排序
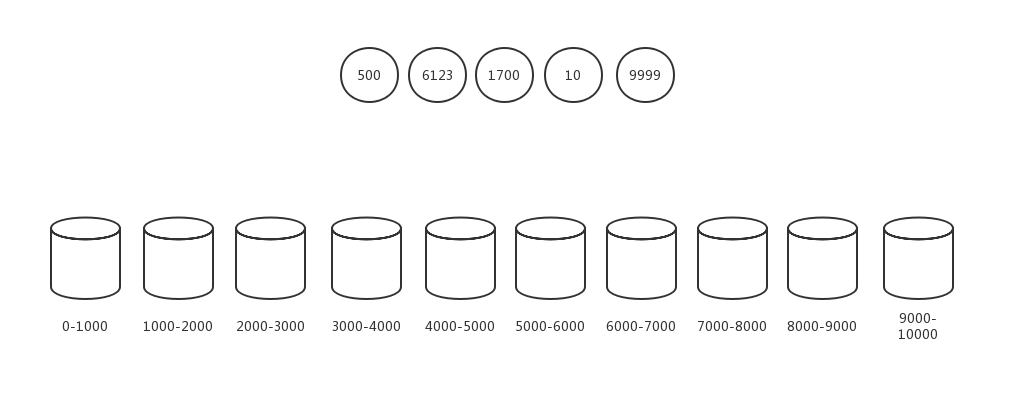
我们拿一组计数排序啃不掉的数据[500,6123,1700,10,9999]来举例。
第一步,我们创建10个桶,分别来装0-1000、1000-2000、2000-3000、3000-4000、4000-5000、5000-6000、6000-7000、7000-8000、8000-9000区间的数据。
第二步,遍历原数组,对号入桶。
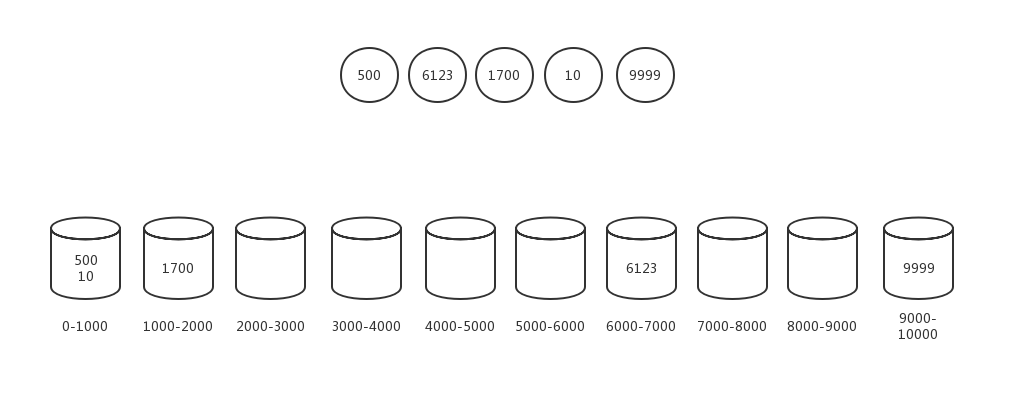
第三步,对桶中的数据进行单独排序,只有第一个桶中的数量大于1,显然只需要排第一个桶。

最后,依次将桶中的数据取出,排序完成。

代码实现
这个桶排序乍一看好像挺简单的,但是要敲代码就需要考虑几个问题了。
桶这个东西怎么表示?
怎么确定桶的数量?
桶内排序用什么方法排?
我们先来看看我的实现:
public static void sort(int[] arr){ //最大最小值 int max = arr[0]; int min = arr[0]; int length = arr.length; for(int i=1; i<length; i++) { if(arr[i] > max) { max = arr[i]; } else if(arr[i] < min) { min = arr[i]; } } //最大值和最小值的差 int diff = max - min; //桶列表 ArrayList<ArrayList<Integer>> bucketList = new ArrayList<>(); for(int i = 0; i < length; i++){ bucketList.add(new ArrayList<>()); } //每个桶的存数区间 float section = (float) diff / (float) (length - 1); //数据入桶 for(int i = 0; i < length; i++){ //当前数除以区间得出存放桶的位置 减1后得出桶的下标 int num = (int) (arr[i] / section) - 1; if(num < 0){ num = 0; } bucketList.get(num).add(arr[i]); } //桶内排序 for(int i = 0; i < bucketList.size(); i++){ //jdk的排序速度当然信得过 Collections.sort(bucketList.get(i)); } //写入原数组 int index = 0; for(ArrayList<Integer> arrayList : bucketList){ for(int value : arrayList){ arr[index] = value; index++; } } }
桶当然是一个可以存放数据的集合,我这里使用arrayList,如果你使用LinkedList那其实也是没有问题的。
桶的数量我认为设置为原数组的长度是合理的,因为理想情况下每个数据装一个桶。
数据入桶的映射算法其实是一个开放性问题,由于难度原因我找了一下网络上的文章博客,目前我没有发现什么最优的答案,大部分对桶排序的实现都是遮遮掩掩的,少部分写的代码也是瞎整,我承认我这里写的方案并不佳,因为我测试过不同的数据集合来排序,如果你有什么更好的方案或想法,欢迎留言讨论。
桶内排序为了方便起见使用了当前语言提供的排序方法,如果对于稳定排序有所要求,可以选择使用自定义的排序算法。
桶排序的思考及其应用
在额外空间充足的情况下,尽量增大桶的数量,极限情况下每个桶只有一个数据时,或者是每只桶只装一个值时,完全避开了桶内排序的操作,桶排序的最好时间复杂度就能够达到O(n)
比如高考总分750分,全国几百万人,我们只需要创建751个桶,循环一遍挨个扔进去,排序速度是毫秒级。
但是如果数据经过桶的划分之后,桶与桶的数据分布极不均匀,有些数据非常多,有些数据非常少,比如[8,2,9,10,1,23,53,22,12,9000]这十个数据,我们分成十个桶装,结果发现第一个桶装了9个数据,这是非常影响效率的情况,会使时间复杂度下降到O(nlogn),解决办法是我们每次桶内排序时判断一下数据量,如果桶里的数据量过大,那么应该在桶里面回调自身再进行一次桶排序。
基数排序
基数排序是一种非比较型整数排序算法,其原理是将数据按位数切割成不同的数字,然后按每个位数分别比较。
假设说,我们要对100万个手机号码进行排序,应该选择什么排序算法呢?排的快的有归并、快排时间复杂度是O(nlogn),计数排序和桶排序虽然更快一些,但是手机号码位数是11位,那得需要多少桶?内存条表示不服。
这个时候,我们使用基数排序是最好的选择。
图解鸡排
我们以[892, 846, 821, 199, 810,700]这组数字来做例子演示。
首先,创建十个桶,用来辅助排序。
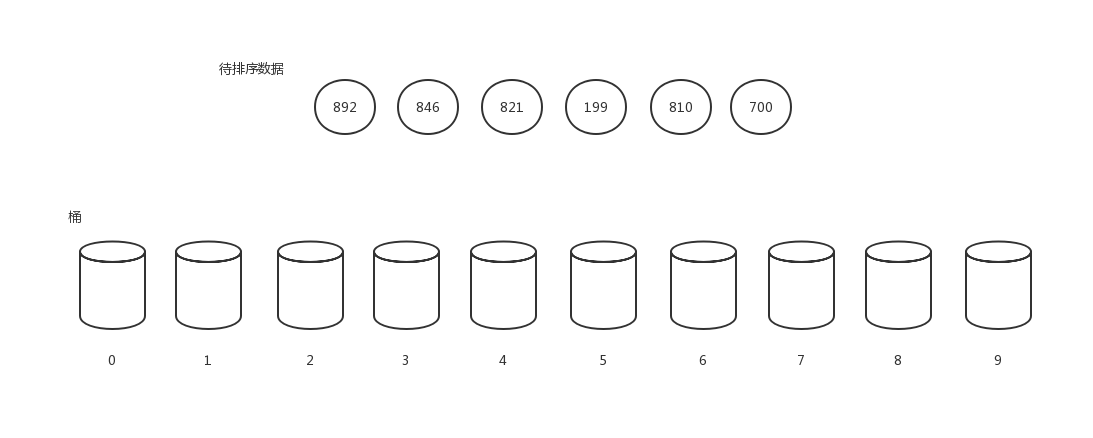
先排个位数,根据个位数的值将数据放到对应下标值的桶中。
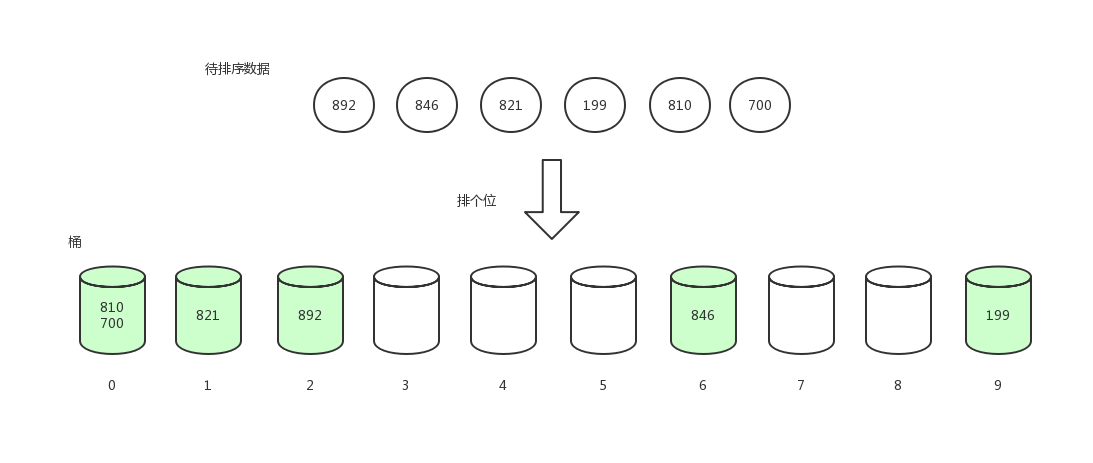
排完后,我们将桶中的数据依次取出。
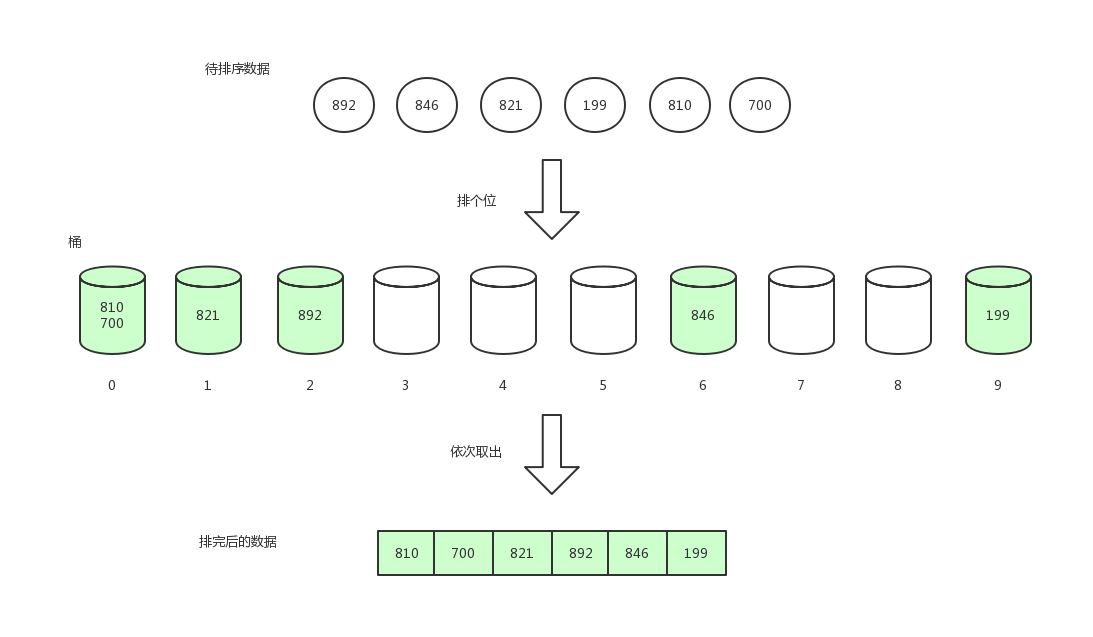
那么接下来,我们排十位数。

最后,排百位数。

排序完成。
代码实现
基数排序可以看成桶排序的扩展,也是用桶来辅助排序,我们来看下代码:
public static void sort(int[] arr) { int length = arr.length; //最大值 int max = arr[0]; for(int i=0;i<length;i++){ if(arr[i] > max){ max = arr[i]; } } //当前排序位置 int location = 1; //桶列表 ArrayList<ArrayList<Integer>> bucketList = new ArrayList<>(); //长度为10 装入余数0-9的数据 for(int i = 0; i < 10; i++){ bucketList.add(new ArrayList()); } while(true) { //判断是否排完 int dd = (int)Math.pow(10,(location - 1)); if(max < dd){ break; } //数据入桶 for(int i = 0; i < length; i++) { //计算余数 放入相应的桶 int number = ((arr[i] / dd) % 10); bucketList.get(number).add(arr[i]); } //写回数组 int nn = 0; for (int i=0;i<10;i++){ int size = bucketList.get(i).size(); for(int ii = 0;ii < size;ii ++){ arr[nn++] = bucketList.get(i).get(ii); } bucketList.get(i).clear(); } location++; } }
其实它的思想很简单,不管你的数字有多大,我一位一位的排,0-9最多也就十个桶,先按权重小的位置排序,然后按权重大的位置排序。
当然,如果你有需求,也可以选择从高位往低位排。
效率对比
最后,在菜鸟教程上扒了张图,真的是太详细了,非扒不可。
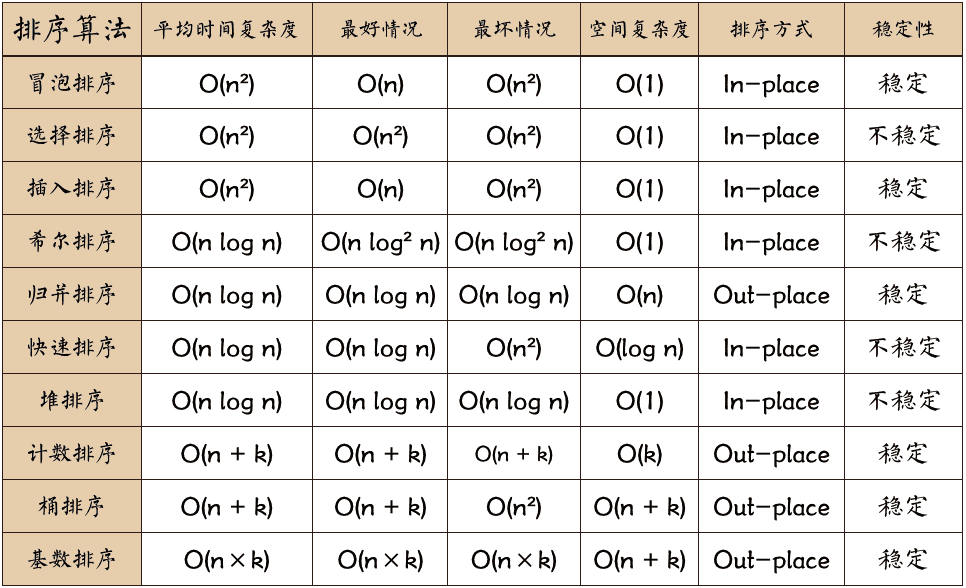
最后,感谢阅读。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构