散列表
散列表的定义
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
从这个定义就可以得知,散列表实际上存储数据的仍然是数组。
假设我们要存储一组电话簿:
Bob 13113113111
Lany 13113113113
Mary 13113113112
数组查询数据靠的是数组下标,当我们要查询Mary的电话号码,那得先从下标0开始查询,取出来发现是Bob,再取下标1的数据,取出来也不对,再取下标2的数据,取出来才是Mary的数据,这样遍历了整个数组才找到Mary的电话号码。
设计者的想法就是将Bob、Lany、Mary设计成key,能够用key来直接取出value值,并且不用遍历整组数据。
实现方式也是选择用数组来实现,利用数组高效查询的特性,在存取数据的时候使用了一个中转,将key转化成数组下标。
哈希函数
这个中转站,也就是哈希函数,这是一个加密函数,可以将任何数据加密成一串整型数字,虽然是数字,但一般情况下都是以十六进制来表示的,所以我们平常看到的都是字符串的样子。
哈希算法有很多种,目前应用最广泛的差不多是MD4、MD5、SHA1等加密算法。
将哈希映射到数组下标的实现方式也有很多,直接定址法、数字分析法、平方取中法、折叠法等等,在不同的语言中,实现方式是不太一样的。
最常见的实现就是将哈希函数的结果对数组长度进行取模,得到一个0到数组长度之间的数字,将此数字作为下标。
存电话簿:
Bob 13113113111
Lany 13113113113
Mary 13113113112
我们先创建一个长度为10的数组:

假设 Bob的哈希值为51246,那么51246%10=6,就将Bob的电话号码放到下标为6的空间中。
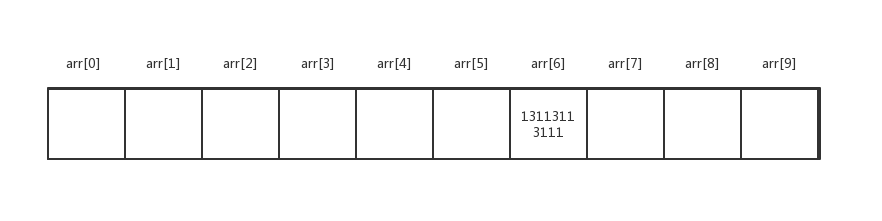
Mary的哈希值为26154,那么取模后得到的值为4,就将Mary的电话号码放到下标为4的空间中。
添加
但是由于数组的长度是有限的,系统创建数组的时候也无法预测程序员要存储的数据有多大,所以当添加的数据越来越多的时候,数组的空间就会逐渐填满,即使没填满,取模后下标相同的几率也会越来越大。
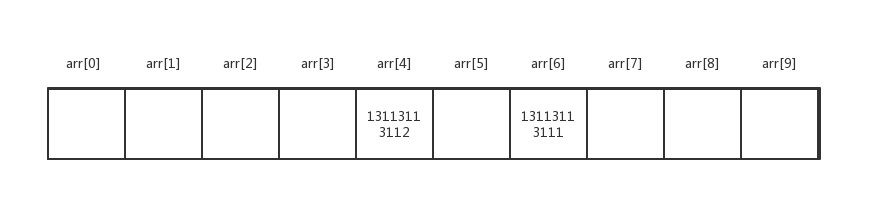
比如Lany哈希值为33724,取模后值也是:
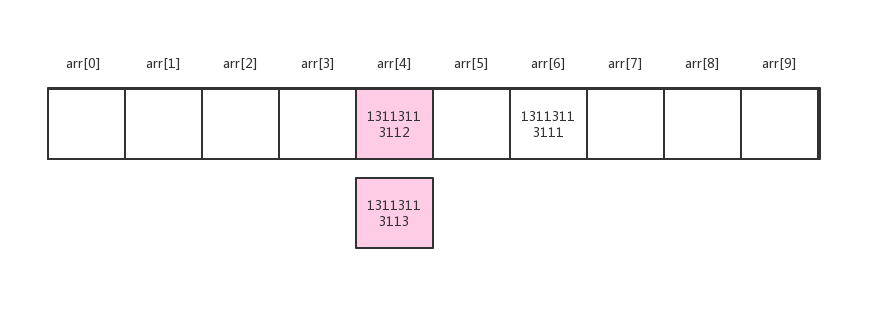
这种情况,就叫哈希冲突。
无论哈希函数设计有多么精细,都会产生冲突现象,也就是2个key的处理结果映射在了同一位置上,避免冲突的办法也有多种。
多哈希法,设计多种哈希函数。
开放地址法,如果哈希冲突,立刻计算出一个候补地址尝试存储数据,如果仍有冲突便继续计算下一个候补地址。
拉链法,如果哈希冲突,则在目标地址中将数据换成链表存储,无论多少数据,都可以在链表末尾进行连接。
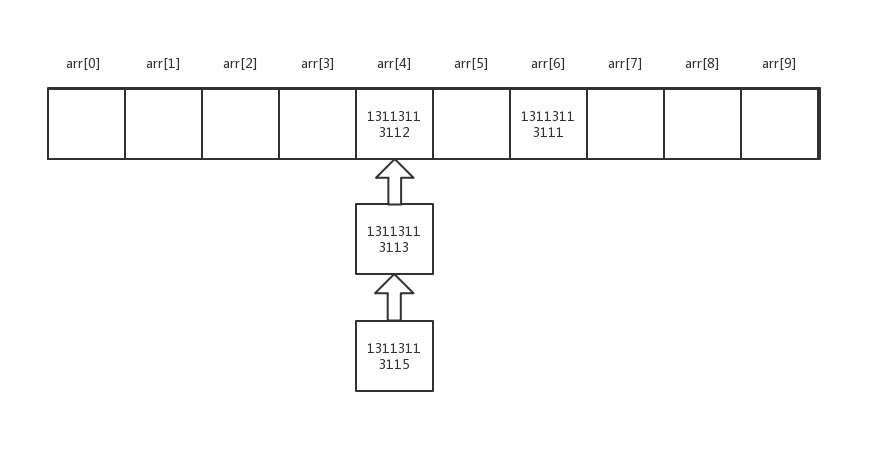
这里我们以拉链法来理解:
查找
查找和添加也是一样的,将key进行哈希处理,取模,得到的值就是数组下标。
如果我取Lany的电话号码呢?
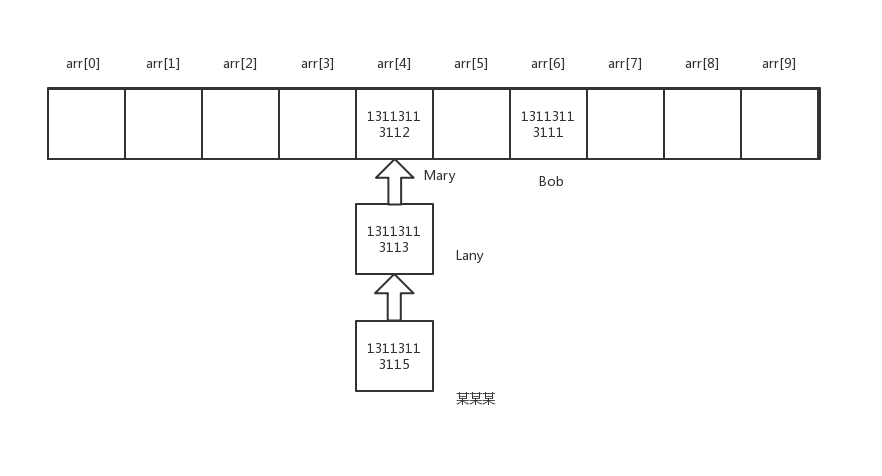
在上面我们已经知道了Lany和Mary是有哈希冲突的,在内存中已经拉出了一个动态链表,当我要查询Lany的电话号码的时候,找到了arr[4]这个元素,由于arr[4]这个元素与链表链头相对应,所以就顺着链表往下找。
可能大家会奇怪,因为我也奇怪,它是怎么确定哪一个元素是Lany的电话号码呢?
这里可以看一段Java中HashMap的源码:
JDK8,HashMap.java 第285行:
Node(int hash, K key, V value, Node<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; }
数组中的每个元素,存的并不是单纯的我们想存的数据,而是存了一个Node对象,同时将hash、key、和next也一起存了。
扩容
当添加的数据多了(HashMap初始长度只有16),散列表达到一定的饱和度,出现哈希冲突的几率会逐渐增高,可能会导致大量数据挤压在同一个数组下标上,形成长链,链表的查询无疑的低效率的,严重影响整个散列表的插入读取性能。
所以散列表必然会有一个扩容的操作:新创建一个2两倍长的空数组,再遍历原数组,将所有的节点重新进行哈希处理,后将新节点放入新数组。

