谷粒商城学习笔记以及错误总结
谷粒商城学习笔记以及错误总结:
谷粒商城文档:https://easydoc.net/s/78237135/ZUqEdvA4/7C3tMIuF
一、Vue前端项目配置调用api接口:
//api接口请求地址
window.SITE_CONFIG['baseUrl'] = 'http://localhost:8080/renren-fast';
最开始这样写,但发现是通过网关来处理的
后台renren-fast设置允许跨域请求:
@Override
public void addCorsMappings(CorsRegistry registry) {
registry.addMapping("/**")
.allowedOrigins("*")
.allowCredentials(true)
.allowedMethods("GET", "POST", "PUT", "DELETE", "OPTIONS")
.maxAge(3600);
}
二、SpringCloud Alibaba简介:
- 注册中心:
- 配置中心:
- 网关:
No Feign Client for loadBalancing defined. Did you forget to include spring-cloud-starter-loadbalancer?:
添加spring-cloud-starter-loadbalancer,排除 Nacos 的 Ribbon:
https://blog.csdn.net/qq_43416157/article/details/114318283
在项目中多配置集启动失败(暂未找到原因,下载下来的项目都能成功启动,大意了,真是没闪)
##Nacos加载多配置集
spring.cloud.nacos.config.extension-configs[0].data-id=datasource.yml
spring.cloud.nacos.config.extension-configs[0].group=dev
spring.cloud.nacos.config.extension-configs[0].refresh=true
spring.cloud.nacos.config.extension-configs[1].data-id=mybatis.yml
spring.cloud.nacos.config.extension-configs[1].group=dev
spring.cloud.nacos.config.extension-configs[1].refresh=true
spring.cloud.nacos.config.extension-configs[2].data-id=other.yml
spring.cloud.nacos.config.extension-configs[2].group=dev
spring.cloud.nacos.config.extension-configs[2].refresh=true
三、网关gateway:
动态上下线:发送请求需要知道商品服务的地址,如果商品服务器有123服务器,1号掉线后,还得改,所以需要网关动态地管理,他能从注册中心中实时地感知某个服务上线还是下线。【先通过网关,网关路由到服务提供者】
拦截:请求也要加上询问权限,看用户有没有权限访问这个请求,也需要网关。
所以我们使用spring cloud的gateway组件做网关功能。
网关是请求流量的入口,常用功能包括路由转发,权限校验,限流控制等。springcloud gateway取代了zuul网关。
https://spring.io/projects/spring-cloud-gateway
三大核心概念:
Route: The basic building block of the gateway. It is defined by an ID, a destination URI, a collection of predicates断言, and a collection of filters. A route is matched if the aggregate predicate is true.发一个请求给网关,网关要将请求路由到指定的服务。路由有id,目的地uri,断言的集合,匹配了断言就能到达指定位置,
Predicate断言: This is a Java 8 Function Predicate. The input type is a Spring Framework ServerWebExchange. This lets you match on anything from the HTTP request, such as headers or parameters.就是java里的断言函数,匹配请求里的任何信息,包括请求头等。根据请求头路由哪个服务
Filter: These are instances of Spring Framework GatewayFilter that have been constructed with a specific factory. Here, you can modify requests and responses before or after sending the downstream request.过滤器请求和响应都可以被修改。
客户端发请求给服务端。中间有网关。先交给映射器,如果能处理就交给handler处理,然后交给一系列filer,然后给指定的服务,再返回回来给客户端。
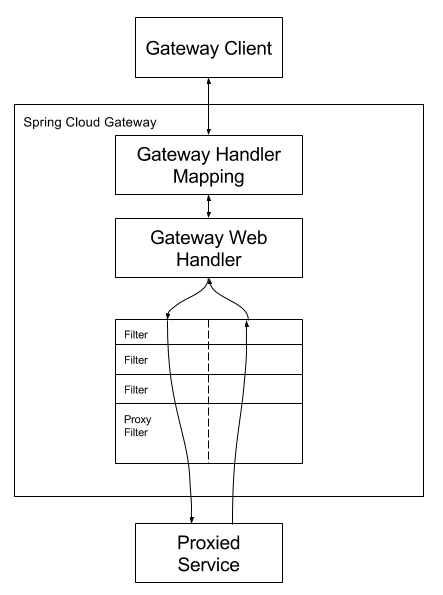
- id: test_route
uri: https://www.baidu.com/?tn=98010089_dg&ch=12
predicates:
- Query=url,baidu
访问http://localhost:88/?url=baidu即可跳转到百度
//api接口请求地址
window.SITE_CONFIG['baseUrl'] = 'http://localhost:88/api';
88是网关端口号,由application.yml配置来处理前端发送过来的请求
网关-路径重写:
- id: admin_route
uri: lb://renren-fast
predicates:
- Path=/api/**
filters:
- RewritePath=/api/(?<segment>/?.*), /renren-fast/$\{segment}
如出现Access to XMLHttpRequest at 'http://localhost:88/api/sys/login' from origin 'http://localhost:8001' has been blocked by CORS policy: The 'Access-Control-Allow-Origin' header contains multiple values 'http://localhost:8001, http://localhost:8001', but only one is allowed.
这表示同源请求有多个,原因是配置了多个跨越,把renren-fast的跨越请求注释即可!
跨域的解决方案:
方法1:设置nginx包含admin和gateway。都先请求nginx,这样端口就统一了
方法2:让服务器告诉预检请求能跨域
解决方案1:
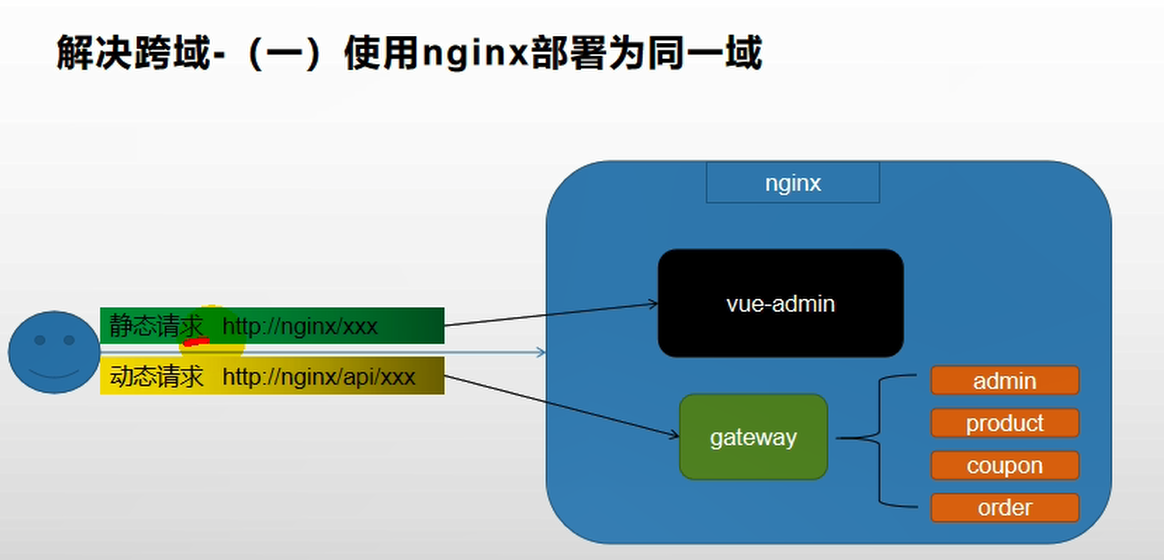
解决方案二为在服务端2配置允许跨域
在响应头中添加:参考:https://blog.csdn.net/qq_38128179/article/details/84956552
Access-Control-Allow-Origin : 支持哪些来源的请求跨域
Access-Control-Allow-Method : 支持那些方法跨域
Access-Control-Allow-Credentials :跨域请求默认不包含cookie,设置为true可以包含cookie
Access-Control-Expose-Headers : 跨域请求暴露的字段
CORS请求时,XMLHttpRequest对象的getResponseHeader()方法只能拿到6个基本字段:
Cache-Control、Content-Language、Content-Type、Expires、Last-Modified、Pragma
如果想拿到其他字段,就必须在Access-Control-Expose-Headers里面指定。
Access-Control-Max-Age :表明该响应的有效时间为多少秒。在有效时间内,浏览器无须为同一请求再次发起预检请求。请注意,浏览器自身维护了一个最大有效时间,如果该首部字段的值超过了最大有效时间,将失效
解决方法:在网关中定义“GulimallCorsConfiguration”类,该类用来做过滤,允许所有的请求跨域。
package com.atguigu.gulimall.gateway.config;
@Configuration // gateway
public class GulimallCorsConfiguration {
@Bean // 添加过滤器
public CorsWebFilter corsWebFilter(){
// 基于url跨域,选择reactive包下的
UrlBasedCorsConfigurationSource source=new UrlBasedCorsConfigurationSource();
// 跨域配置信息
CorsConfiguration corsConfiguration = new CorsConfiguration();
// 允许跨域的头
corsConfiguration.addAllowedHeader("*");
// 允许跨域的请求方式
corsConfiguration.addAllowedMethod("*");
// 允许跨域的请求来源
corsConfiguration.addAllowedOrigin("*");
// 是否允许携带cookie跨域
corsConfiguration.setAllowCredentials(true);
// 任意url都要进行跨域配置
source.registerCorsConfiguration("/**",corsConfiguration);
return new CorsWebFilter(source);
}
}
高级篇:
四、Elastic Search:
mysql用作持久化存储,ES用作检索
基本概念:index库>type表>document文档
index索引
动词:相当于mysql的insert
名词:相当于mysql的db
Type类型
在index中,可以定义一个或多个类型
类似于mysql的table,每一种类型的数据放在一起
Document文档
保存在某个index下,某种type的一个数据document,文档是json格式的,document就像是mysql中的某个table里面的内容。每一行对应的列叫属性
ElasticSearch安装
1:安装ES
直接点击:https://www.elastic.co/cn/downloads/past-releases#elasticsearch 官网选择版本,这里的版本最好对应Java pom.xml
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.6.2</elasticsearch.version>
</properties>
的版本
下载之后解压文件,切换到解压文件路径下,执行
切换到bin目录下
输入 elasticsearch.bat #运行es
即可看到如下内容:
{
"name" : "HOMEWCC",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "PkQa3LzwQIa6micTjlM0_g",
"version" : {
"number" : "7.9.2",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "d34da0ea4a966c4e49417f2da2f244e3e97b4e6e",
"build_date" : "2020-09-23T00:45:33.626720Z",
"build_snapshot" : false,
"lucene_version" : "8.6.2",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
Kibana 的安装(Windows版本)
什么是Kibana?
Kibana 是一个设计出来用于和 Elasticsearch 一起使用的开源的分析与可视化平台,可以用 kibana 搜索、查看、交互存放在Elasticsearch 索引里的数据,使用各种不同的图表、表格、地图等展示高级数据分析与可视化,基于浏览器的接口使你能快速创建和分享实时展现Elasticsearch查询变化的动态仪表盘,让大量数据变得简单,容易理解。
kibana的版本和elasticsearch的版本和必须一致。
打开下图的路径文件kibana.yml(可以通过记事本方式)

设置elasticsearch.url为启动的elasticsearch(http://localhost:9200/)(其实按照默认可以不用修改配置文件)

进入kibana的bin目录,双击kibana.bat(第一种方式)

通过cmd的方式进入kibana的bin目录,运行kibana.bat(第二种方式);
访问:http://localhost:5601,出现以下界面即完成安装。
ElasticSearch:IK分词及windows安装IK分词
ik分词器下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
pinyin分词器下载地址:https://github.com/medcl/elasticsearch-analysis-pinyin/releases
ik分词器要与ES版本一致
elasticsearch目录的plugins目录新建 analysis-ik ,analysis-pinyin文件夹,然后将我们第一步下载的IK分词包解压到analysis-ik文件夹,重新启动elasticsearch
验证分词:
标准分词器
POST _analyze { "analyzer": "standard", "text": "The 2 Brown-Foxes bone." }
使用分词器查询结果:
POST _analyze
{
"analyzer": "ik_smart",
"text": "我是中国人"
}
GET _analyze
{
"analyzer": "ik_max_word",
"text":"我是中国人"
}
自定义词库:
安装Nginx:
直接参考:https://www.cnblogs.com/jiangwangxiang/p/8481661.html
需要在html文件夹里面建立es文件夹,里面放分词组fenci.txt文本
修改elasticsearch-7.6.2\plugins\analysis-ik\config\IKAnalyzer.cfg.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://127.0.0.1/es/fenci.txt</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
修改完成后,需要重启elasticsearch容器,否则修改不生效。
在Kibana输入
GET _analyze { "analyzer": "ik_smart", "text":"樱桃萨其马,带你甜蜜入夏" }进行测试
商品上架功能:
#商品上架的最终选用的数据模型:
DELETE gulimall_product
PUT gulimall_product
{
"mappings": {
"properties": {
"skuId": {
"type": "long"
},
"spuId": {
"type": "keyword"
},
"skuTitle": {
"type": "text",
"analyzer": "ik_smart"
},
"skuPrice": {
"type": "keyword"
},
"skuImg": {
"type": "keyword"
},
"saleCount": {
"type": "long"
},
"hasStock": {
"type": "boolean"
},
"hotScore": {
"type": "long"
},
"brandId": {
"type": "long"
},
"catelogId": {
"type": "long"
},
"brandName": {
"type": "keyword"
},
"brandImg": {
"type": "keyword"
},
"catelogName": {
"type": "keyword"
},
"attrs": {
"type": "nested",
"properties": {
"attrId": {
"type": "long"
},
"attrName": {
"type": "keyword"
},
"attrValue": {
"type": "keyword"
}
}
}
}
}
}
GET gulimall_product/_search
五、公用工具:
六、商城系统首页:
七、Nginx:
1:Nginx+网关+openFeign的逻辑:
正向代理:如Science and the Internet,隐藏客户端信息
反向代理:屏蔽内网服务器信息,负载均衡访问
gulimall.com在hosts文件配置,由于在windows上面修改的hosts文件,windows里面安装了Nginx
访问gulimall.com的时候不带端口,默认就来到了Nginx默认的80端口,
在Nginx里面配置了专门监听【指定80端口来的可以访问gulimall.com】
listen 80; server_name gulimall.com *.gulimall.com;
Nginx监听到后在代理给网关,在代理网关过程中,
Nginx会丢掉Host,所以
修改nginx/conf/conf.d/gulimall.conf,接收到gulimall.com的访问后,如果是/,转交给指定的upstream,由于nginx的转发会丢失host头,造成网关不知道原host,所以我们添加头信息
location / {
proxy_pass http://gulimall;
proxy_set_header Host $host;
}
,网关在做处理Api进行访问
2、Nginx配置文件
3、Nginx+网关配置
配置gateway为服务器,将域名为**.gulimall.com转发至商品服务。配置的时候注意 网关优先匹配的原则,所以要把这个配置放到后面
- id: gulimall_host_route
uri: lb://gulimall-product
predicates:
- Host=**.gulimall.com
由于1,2,3部在windows下面没有。所以在windows下面没能配置
八、压力测试:
JVM参数、工具、调优笔记:https://blog.csdn.net/hancoder/article/details/108312012
Jmeter
下载:https://jmeter.apache.org/download_jmeter.cgi
Jconsole、JvisualVM:
运行状态:
运行:正在运行
休眠:sleep
等待:wait
驻留:线程池里面的空闲线程
监视:阻塞的线程,正在等待锁
要监控GC,安装插件:工具-插件。可用插件-检查最新版本 报错的时候百度“插件中心”,改个JVM对应的插件中心url.xml.z
安装visual GC
优化
SQL耗时越小越好,一般情况下微秒级别
命中率越高越好,一般情况下不能低于95%
锁等待次数越低越好,等待时间越短越好
中间件越多,性能损失雨大,大多都损失在网络交互了
Nginx动静分离
由于动态资源和静态资源目前都处于服务端,所以为了减轻服务器压力,我们将js、css、img等静态资源放置在Nginx端,以减轻服务器压力
静态文件上传到 mydata/nginx/html/static/index/css,这种格式
修改index.html的静态资源路径,加上static前缀src="/static/index/img/img_09.png"
修改/mydata/nginx/conf/conf.d/gulimall.conf
如果遇到有/static为前缀的请求,转发至html文件夹
location /static {
root /usr/share/nginx/html;
}
location / {
proxy_pass http://gulimall;
proxy_set_header Host $host;
}
九、redisson分布式锁与缓存:
【谷粒商城】高级篇-分布式锁与缓存:
缓存:
- 本地缓存:和微服务同一个进程。缺点:分布式时造成缓存数据不一致
- 分布式缓存:缓存中间件
lettuce堆外内存溢出bug
当进行压力测试时后期后出现堆外内存溢出OutOfDirectMemoryError
产生原因:
1)、springboot2.0以后默认使用lettuce作为操作redis的客户端,它使用netty进行网络通信
2)、lettuce的bug导致netty堆外内存溢出。netty如果没有指定堆外内存,默认使用Xms的值,可以使用-Dio.netty.maxDirectMemory进行设置
解决方案:由于是lettuce的bug造成,不要直接使用-Dio.netty.maxDirectMemory去调大虚拟机堆外内存,治标不治本。
1)、升级lettuce客户端。但是没有解决的
2)、切换使用jedis
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<exclusions>
<exclusion>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
解决方案:
缓存空对象、布隆过滤器、mvc拦截器
缓存击穿指某一个数据缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大。
解决方案:
1:不好的方法是synchronized(this),肯定不能这么写 ,不具体写了。
加互斥锁:业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db去数据库加载,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。
锁时序问题:之前的逻辑是查缓存没有,然后取竞争锁查数据库,这样就造成多次查数据库。
解决方法:竞争到锁后,再次确认缓存中没有,再去查数据库。
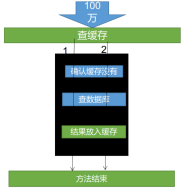
2:设置热点数据永远不过期。
缓存雪崩是指缓存中大批量的数据都到了过期时间,从而导致查询数据量巨大,引起数据库压力过大甚至宕机。和缓存击穿不同,缓存击穿是指某一条数据到了过期时间,大量的并发请求都来查询这一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库,DB(数据库)瞬时压力过重雪崩。
解决方案:
1、设置热点数据永不过期。
2、缓存数据的过期时间设置随机,可以在原有的过期时间上加上一个随机值,比如1-3min,防止同一时间大量缓存数据集体失效,导致数据库压力过大。
3、如果是分布式部署缓存数据库,可将热点数据分别存放到不同的缓存数据库中,避免某一点由于压力过大而宕掉。
出现雪崩:降级 熔断
事前:尽量保证整个 redis 集群的高可用性,发现机器宕机尽快补上。选择合适的内存淘汰策略。
事中:本地ehcache缓存 + hystrix限流&降级,避免MySQL崩掉。
事后:利用 redis 持久化机制保存的数据尽快恢复缓存。
分布式缓存:
本地缓存问题:每个微服务都要有缓存服务、数据更新时只更新自己的缓存,造成缓存数据不一致
解决方案:分布式缓存,微服务共用缓存中间件
分布式锁:
参考链接:https://www.cnblogs.com/wangyingshuo/p/14510524.html
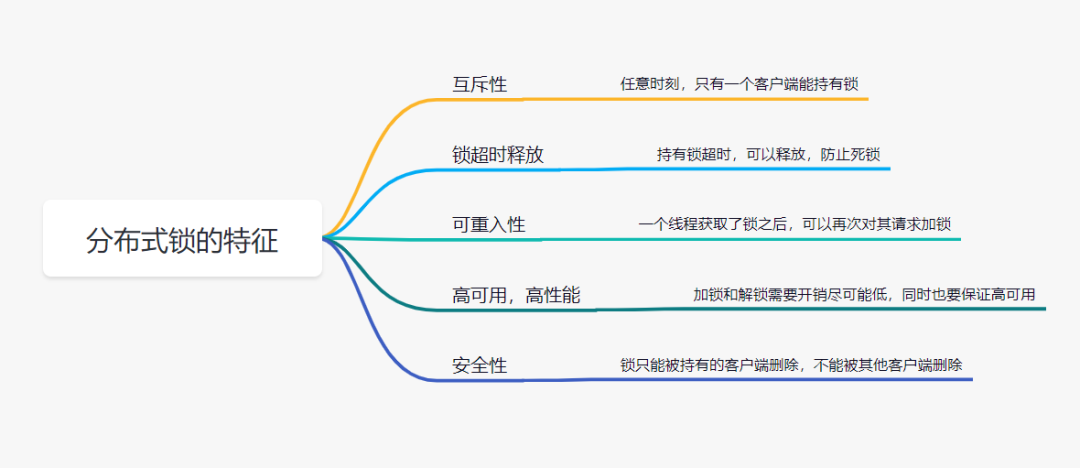
分布式项目时,但本地锁只能锁住当前服务,需要分布式锁
redis分布式锁的原理:setnx,同一时刻只能设置成功一个
前提,锁的key是一定的,value可以变
三种情况分析:
没获取到锁阻塞或者sleep一会
设置好了锁,玩意服务出现宕机,没有执行删除锁逻辑,这就造成了死锁
解决:设置过期时间
业务还没执行完锁就过期了,别人拿到锁,自己执行完去删了别人的锁
解决:锁续期(redisson有看门狗),。删锁的时候明确是自己的锁。如uuid
判断uuid对了,但是将要删除的时候锁过期了,别人设置了新值,那删除了别人的锁
1 if redis.call("get",KEYS[1]) == ARGV[1] 2 then 3 return redis.call("del",KEYS[1]) 4 else 5 return 0 6 end;
1 stringRedisTemplate.execute( 2 new DefaultRedisScript<Long返回值类型>(script脚本支付非常, Long.class返回值类型), 3 Arrays.asList("lock"), // 键key的集合 4 lockValue);
上面的lua脚本写法每次用分布式锁时比较麻烦,我们可以采用redisson现有框架
Redisson:
Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务。其中包括(BitSet, Set, Multimap, SortedSet, Map, List, Queue, BlockingQueue, Deque, BlockingDeque, Semaphore, Lock, AtomicLong, CountDownLatch, Publish / Subscribe, Bloom filter, Remote service, Spring cache, Executor service, Live Object service, Scheduler service) Redisson提供了使用Redis的最简单和最便捷的方法。Redisson的宗旨是促进使用者对Redis的关注分离(Separation of Concern),从而让使用者能够将精力更集中地放在处理业务逻辑上。
可重入锁(Reentrant Lock):
A调用B。AB都需要同一锁,此时可重入锁就可以重入,A就可以调用B。不可重入锁时,A调用B将死锁。
如果负责储存这个分布式锁的Redisson节点宕机以后,而且这个锁正好处于锁住的状态时,这个锁会出现锁死的状态。为了避免这种情况的发生,Redisson内部提供了一个监控锁的看门狗,它的作用是在Redisson实例被关闭前,不断的延长锁的有效期。默认情况下,看门狗的检查锁的超时时间是30秒钟(每到20s就会自动续借成30s,是1/3的关系)
读写锁(ReadWriteLock):
基于Redis的Redisson分布式可重入读写锁RReadWriteLock Java对象实现了java.util.concurrent.locks.ReadWriteLock接口。其中读锁和写锁都继承了RLock接口。
分布式可重入读写锁允许同时有多个读锁和一个写锁处于加锁状态。
信号量(Semaphore):
信号量为存储在redis中的一个数字,当这个数字大于0时,即可以调用acquire()方法增加数量,也可以调用release()方法减少数量,但是当调用release()之后小于0的话方法就会阻塞,直到数字大于0
闭锁(CountDownLatch):
基于Redisson的Redisson分布式闭锁(CountDownLatch)Java对象RCountDownLatch采用了与java.util.concurrent.CountDownLatch相似的接口和用法。
以下代码只有offLatch()被调用5次后 setLatch()才能继续执行
RCountDownLatch latch = redisson.getCountDownLatch("anyCountDownLatch");
latch.trySetCount(1);
latch.await();
// 在其他线程或其他JVM里
RCountDownLatch latch = redisson.getCountDownLatch("anyCountDownLatch");
latch.countDown();
缓存和数据库一致性:
双写模式:写数据库后,写缓存
问题:并发时,线程2写进入,写完DB后都写缓存。有暂时的脏数据
失效模式:写完数据库后,删缓存
问题:还没存入数据库,线程2又读到旧的DB了(线程2读取到还没删除的旧Redis数据)
解决:缓存设置过期时间,定期更新
解决:写数据写时,加分布式的读写锁。
解决方案:
如果是用户纬度数据(订单数据、用户数据),这种并发几率非常小,不用考虑这个问题,缓存数据加上过期时间,每隔一段时间触发读的主动更新即可
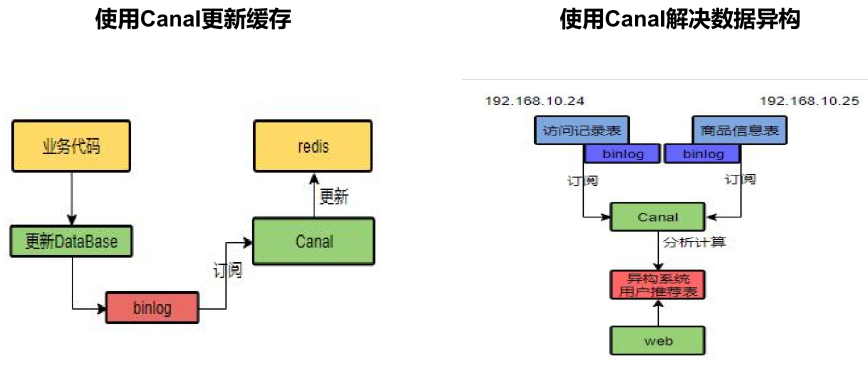
如果是菜单,商品介绍等基础数据,也可以去使用canal订阅binlog的方式
缓存数据+过期时间也足够解决大部分业务对于缓存的要求。
通过加锁保证并发读写,写写的时候按顺序排好队。读读无所谓。所以适合使用读写锁。(业务不关心脏数据,允许临时脏数据可忽略);
总结:
我们能放入缓存的数据本就不应该是实时性、一致性要求超高的。所以缓存数据的时候加上过期时间,保证每天拿到当前最新数据即可。
我们不应该过度设计,增加系统的复杂性
遇到实时性、一致性要求高的数据,就应该查数据库,即使慢点。
springCache:
Cache接口的实现包括RedisCache、EhCacheCache、ConcurrentMapCache等
使用Spring缓存抽象时我们需要关注以下两点:
1、确定方法需要缓存以及他们的缓存策略
2、从缓存中读取之前缓存存储的数据
配置:
#SpringCache配置
spring.cache.type=redis
#设置超时时间,默认是毫秒
spring.cache.redis.time-to-live=3600000
#设置Key的前缀,如果指定了前缀,则使用我们定义的前缀,否则使用缓存的名字作为前缀
#spring.cache.redis.key-prefix=CACHE_
#配置是否使用前缀
spring.cache.redis.use-key-prefix=true
#是否缓存空值,防止缓存穿透
spring.cache.redis.cache-null-values=true
缓存使用@Cacheable@CacheEvict:
第一个方法存放缓存,第二个方法清空缓存
* (1)更新分类数据
* (2)@CacheEvict采用失效模式更新缓存
* (3)可以有两种方式来实现同时更新缓存到redis的一级或三级分类数据
* (4)Caching组合删除多个缓存
* (5)allEntries = true删除value = {"category"}的所有缓存分区
#root.methodName以value的值作为key
@Cacheable(value = {"category"}, key = "#root.methodName")
SpringCache原理与不足:
1)、读模式
1:缓存穿透:查询一个null数据。解决方案:缓存空数据,可通过spring.cache.redis.cache-null-values=true
2;缓存击穿:大量并发进来同时查询一个正好过期的数据。解决方案:加锁 ? 默认是无加锁的;
使用sync = true来解决击穿问题
3:缓存雪崩:大量的key同时过期。解决:加随机时间。
2)、写模式:(缓存与数据库一致)
1:读写加锁。
2:引入Canal,感知到MySQL的更新去更新Redis
读多写多,直接去数据库查询就行
3)、总结:
常规数据(读多写少,即时性,一致性要求不高的数据,完全可以使用Spring-Cache):
写模式(只要缓存的数据有过期时间就足够了)
特殊数据:特殊设计
十、检索:
商品检索服务:
需求:
上架的商品才可以在网站展示。
上架的商品需要可以被检索。
分析sku在es中如何存储
商品mapping
分析:商品上架在es中是存sku还是spu?
1)、检索的时候输入名字,是需要按照sku的title进行全文检索的
2)、检素使用商品规格,规格是spu的公共属性,每个spu是一样的
3)、按照分类id进去的都是直接列出spu的,还可以切换。
4〕、我们如果将sku的全量信息保存到es中(包括spu属性〕就太多字段了
nested嵌入式对象
属性是"type": “nested”,因为是内部的属性进行检索
数组类型的对象会被扁平化处理(对象的每个属性会分别存储到一起)
渲染检索页面:
ES语句DSL
此处先写出如何检索指定的商品,如检索"华为"关键字
- 嵌入式的属性
- highlight:设置该值后,返回的时候就包装过了
- 查出结果后,附属栏也要对应变化
- 嵌入式的聚合时候也要注意
十一、异步编排:
异步编排参考网上链接即可:https://blog.csdn.net/weixin_45762031/article/details/103519459
十二、商品详情:
sql构建
我们观察商品页面与VO,可以大致分为5个部分需要封装。1 2 4比较简单,单表就查出来了。我们分析3、5
我们在url中首先有sku_id,在从sku_info表查标题的时候,顺便查到了spu_id、catelog_id,这样我们就可以操作剩下表了。
分组规格参数
在5查询规格参数中
pms_product_attr_value 根据spu_id获得spu相关属性
pms_attr_attrgroup_relation根据catelog_id获得属性的分组
优化:异步编排
因为商品详情是查多个sql,所以可以利用线程池进行异步操作,但是因为有的步骤需要用到第一步的spu_d结果等想你想,所以需要使用异步编排。
调用thenAcceptAsync()可以接受上一步的结果且没有返回值。
最后调用get()方法使主线程阻塞到其他线程完成任务。
/**
* 商品详情信息返回数据
*
* @param skuId
* @return
*/
@Override
public SkuItemVo item(Long skuId) throws ExecutionException, InterruptedException {
SkuItemVo skuItemVo = new SkuItemVo();
CompletableFuture<SkuInfoEntity> infoFutrue = CompletableFuture.supplyAsync(() -> {
//1 sku基本信息
SkuInfoEntity info = getById(skuId);
skuItemVo.setInfo(info);
return info;
}, executor);
CompletableFuture<Void> spuInfoFuture = infoFutrue.thenAcceptAsync(res -> {
//查询商品基本信息
SpuInfoEntity spuInfo = spuInfoService.getById(res.getSpuId());
skuItemVo.setSpuInfo(spuInfo);
}, executor);
CompletableFuture<Void> ImgageFuture = CompletableFuture.runAsync(() -> {
//2 sku图片信息
List<SkuImagesEntity> images = imagesService.getImagesBySkuId(skuId);
skuItemVo.setImages(images);
}, executor);
//3. 获取SPU销售属性组合 pms_product_attr_value
CompletableFuture<Void> saleAttrFuture = infoFutrue.thenAcceptAsync(res -> {
//3 获取spu销售属性组合 list
List<SkuItemSaleAttrVo> saleAttrVos = skuSaleAttrValueService.getSaleAttrsBySpuId(res.getSpuId());
skuItemVo.setSaleAttr(saleAttrVos);
}, executor);
CompletableFuture<Void> descFuture = infoFutrue.thenAcceptAsync(res -> {
//4. 获取SPU的介绍 pms_spu_info_desc
SpuInfoDescEntity spuInfoDescEntity = spuInfoDescService.getById(res.getSpuId());
skuItemVo.setDesp(spuInfoDescEntity);
}, executor);
CompletableFuture<Void> baseAttrFuture = infoFutrue.thenAcceptAsync(res -> {
//5. 获取SPU的规格参数信息
List<SpuItemAttrGroupVo> spuItemAttrGroupVos = attrGroupService.getAttrGroupWithAttrsBySpuId(res.getSpuId(), res.getCatalogId());
skuItemVo.setGroupAttrs(spuItemAttrGroupVos);
}, executor);
// 等待所有任务都完成再返回
CompletableFuture.allOf(spuInfoFuture, ImgageFuture, saleAttrFuture, descFuture, baseAttrFuture).get();
return skuItemVo;
}
十三、认证服务:
为了防止恶意攻击短信接口,用redis缓存电话号:
在redis中以phone-code为前缀将电话号码和验证码进行存储并将当前时间与code一起存储
如果调用时以当前phone取出的redis值不为空且当前时间在存储时间的60s以内,说明60s内该号码已经调用过,返回错误信息
60s以后再次调用,需要删除之前存储的phone-code
code存在一个过期时间,我们设置为10min,10min内验证该验证码有效
session要能在不同服务和同服务的集群的共享:
十四、购物车服务:
十五、订单服务:
远程调用丢失用户信息:
原因:feign远程调用的请求头中没有含有JSESSIONID的cookie,所以也就不能得到服务端的session数据,也就没有用户数据
解决方案:向容器中导入定制的RequestInterceptor为请求加上cookie。
线程异步丢失上下文问题:
原因:由于RequestContextHolder使用ThreadLocal共享数据,所以在开启异步时获取不到老请求的信息,自然也就无法共享cookie了。
解决方案:开启异步的时候将老请求的RequestContextHolder的数据设置进去
1 // 从主线程获取用户数据 放到局部变量中 2 RequestAttributes attributes = RequestContextHolder.getRequestAttributes(); 3 CompletableFuture<Void> getAddressFuture = CompletableFuture.runAsync(() -> { 4 // 把旧RequestAttributes放到新线程的RequestContextHolder中 5 RequestContextHolder.setRequestAttributes(attributes); 6 }
接口幂等性讨论:
幂等性:订单提交一次和提交多次结果是一致的。
哪些情况要防止:
- 用户多次点击按钮
- 用户页面回退再次提交
- 服务相互调用,由于网络间题,导致请求失败。feign触发重试机制
- 其他业务情况
幂等解决方案:
(1)、token机制:
服务端提供了发送token的接囗。我们在分析业务的时候,哪些业务是存在幂等问题的,就必须在执行业务前,先去获取token,服务器会把token保存到redis中。
服务器判断token是否存在redis中,存在表示第一次请求,然后先删除token,继续执行业务。
但要保证只能有一个去redis看,否则就可能都看到redis中有,删除两次
【对比+删除】得是原子性的,所以就想到了用redis-luna脚本分布式锁
if redis.call('get',KEYS[1])==ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end
KEYS[1] 用来表示在redis中用作键值的参数占位,主要用来传递在redis 中用作keyz值的参数。
ARGV[1] 用来表示在redis中用作参数的占位,主要用来传递在redis中用做value值的参数。
如果判断token不存在redis中,就表示是重复操作,直接返回重复标记给client,这样就保证了业务代码,不重复执行。
redis 127.0.0.1:6379> EVAL script numkeys key [key ...] arg [arg ...]
参数说明:
- script: 参数是一段 Lua 5.1 脚本程序。脚本不必(也不应该)定义为一个 Lua 函数。
- numkeys: 用于指定键名参数的个数。
- key [key ...]: 从 EVAL 的第三个参数开始算起,表示在脚本中所用到的那些 Redis 键(key),这些键名参数可以在 Lua 中通过全局变量 KEYS 数组,用 1 为基址的形式访问( KEYS[1] , KEYS[2] ,以此类推)。
- arg [arg ...]: 附加参数,在 Lua 中通过全局变量 ARGV 数组访问,访问的形式和 KEYS 变量类似( ARGV[1] 、 ARGV[2] ,诸如此类)。
(2)、各种锁:
a、数据库悲观锁
b、数据库乐观锁
c、业务层分布式锁
(3)、各种唯一约束:
a、数据库唯一约束
b、redis set防重
(4)、防重表:
把唯一幸引插入去重表,再进行业务操作,且他们在同一个事务中。
(5)、全局请求唯一id
调用接口时,生成一个唯一id,redis将数据保存到集合(去重),存在即处理过。
可以使用nginx设置每一个请求的唯一id
proxy_set_header X-Request-id $request_id;
分布式事务:
1 public interface AService { 2 public void a(); 3 public void b(); 4 } 5 6 @Service() 7 public class AServiceImpl1 implements AService{ 8 @Transactional(propagation = Propagation.REQUIRED) 9 public void a() { 10 this.b(); 11 } 12 @Transactional(propagation = Propagation.REQUIRES_NEW) 13 public void b() { 14 } 15 }
此处的this指向目标对象,因此调用this.b()将不会执行b事务切面,即不会执行事务增强,
因此b方法的事务定义“@Transactional(propagation = Propagation.REQUIRES_NEW)”将不会实施,
即结果是b和a方法的事务定义是一样的(我们可以看到事务切面只对a方法进行了事务增强,没有对b方法进行增强)
Q1:b中的事务会不会生效?
A1:不会,a的事务会生效,b中不会有事务,因为a中调用b属于内部调用,没有通过代理,所以不会有事务产生。
Q2:如果想要b中有事务存在,要如何做?
A2:<aop:aspectj-autoproxy expose-proxy=“true”> ,设置expose-proxy属性为true,将代理暴露出来,使用AopContext.currentProxy()获取当前代理,将this.b()改为((UserService)AopContext.currentProxy()).b()
CAP理论
CAP原则又称CAP定理,指的是在一个分布式系统中
一致性(consistency)
在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)
可用性(Availability)
在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性)
分区容惜性(Partitiontolerance)
大多数分布式系统都分布在多个子网络。每个子网络就叫做一个区(partition)。
分区容错的意思是,区间通信可能失败。比如,一台服务器放在中国,另一台服务器放在美国,这就是两个区,它们之间可能无法通信。
CAP原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾
CP要求一致性(有一个没同步好就不可用)
AP要求高可用
raft是一个实现分布式一致性的协议
BASE理论是对CAP理论的延伸,思想是即使无法做到强一致性(CAP的一致性就是强一致性),但可以采用弱一致性,即最终一致性
BASE是指:
基本可用(BasicallyAvailable)
基本可用是指分布式系统在出现故障的时候,允许损失部分可用性(例如响应时间、功能上的可用性),允许损失部分可用性。需要注意的是,基本可用绝不等价于系统不可用。
响应时间上的损失:正常情况下搜索引擎需要在0.5秒之内返回给用户相应的查询结果,但由于出现故障(比如系统部分机房发生断电或断网故障),查询结果的响应时间增加到了1~2秒。
功能上的损失:购物网站在购物高峰(如双十一)时,为了保护系统的稳定性,部分消费者可能会被引导到一个降级页面。
软状态(soft state)
软状态是指允许系统存在中间状态,而该中间状态不会影响系统整体可用性。分布式存储中一般一份数据会有多个副本,允许不同副本同步的延时就是软状态的体现。mysql replication的异步复制也是一种体现。
最终一致性(Eventual Consistency)
最终一致性是指系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。弱一致性和强一致性相反,最终一致性是弱一致性的一种特殊情况。(这也是分布式事务的想法)
从客户端角度,多进程并发访同时,更新过的数据在不同程如何获的不同策珞,决定了不同的一致性。
对于关系型要求更新过据能后续的访同都能看到,这是强一致性。
如果能容忍后经部分过者全部访问不到,则是弱一致性
如果经过一段时间后要求能访问到更新后的数据,则是最终一致性
分布式事务几种方案:
1) 2PC模式(XA事务)
数据库支持的2pc【2二阶段提交】,又叫做XA Transactions
2) 柔性事务-TCC事务补偿型方案
- 刚性事务:遵循ACID原则,强一致性。
- 柔性事务:遵循BASE理论,最终一致性;
与刚性事务不同,柔性事务允许一定时间内,不同节点的数据不一致,但要求最终一致。
- 一阶段
prepare行为:调用自定义的prepare逻辑。 - 二阶段
commit行为:调用自定义的commit逻憬。 - 二阶段
rollback行为:调用自定义的rollback逻辑。
3)柔性事务-最大努力通知型方案
按规律进行通知,不保证数据一定能通知成功,但会提供可查询操作接囗进行核对。这种方案主要用在与第三方系统通讯时,比如:调用微信或支付宝支付后的支付结果通知。这种方案也是结合MQ进行实现,例如:通过MQ发送就请求,设置最大通知次数。达到通知次数后即不再通知。
案例:银行涌知、商户通知等(各大交易业务平台间的商户涌知:多次通知、查询校对、对账文件),支付宝的支付成功异步回调
大业务调用订单,库存,积分。最后积分失败,则一遍遍通知他们回滚
让子业务监听消息队列
如果收不到就重新发
4)柔性事务=可靠消息+最终一致性方案(异步确保型)
实现:业务处理服务在业务事务提交之前,向实时消息服务请求发送捎息,实时捎息服务只记录消息数据,而不是真正的发送。
业务处理服务在业务事务提交之后,向实时消息服务确认发送。
只有在得到确认发送指令后,实时消息服务才会真正发送。
seata解决分布式事务问题
Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。
快速开始:http://seata.io/zh-cn/docs/user/quickstart.html
TC (Transaction Coordinator) - 事务协调者
维护全局和分支事务的状态,驱动全局事务提交或回滚。
TM (Transaction Manager) - 事务管理器
定义全局事务的范围:开始全局事务、提交或回滚全局事务。
RM (Resource Manager) - 资源管理器
管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
消息队列实现最终一致性:
(1) 延迟队列
- 解决:rabbitmq的消息TTL和死信Exchange结合
定义:延迟队列存储的对象肯定是对应的延时消息,所谓"延时消息"是指当消息被发送以后,并不想让消费者立即拿到消息,而是等待指定时间后,消费者才拿到这个消息进行消费。
实现:rabbitmq可以通过设置队列的TTL+死信路由实现延迟队列
TTL:RabbitMQ可以针对Queue设置x-expires 或者 针对Message设置 x-message-ttl,来控制消息的生存时间,如果超时(两者同时设置以最先到期的时间为准),则消息变为dead letter(死信)
死信路由DLX:RabbitMQ的Queue可以配置x-dead-letter-exchange 和x-dead-letter-routing-key(可选)两个参数,如果队列内出现了dead letter,则按照这两个参数重新路由转发到指定的队列。
x-dead-letter-exchange:出现dead letter之后将dead letter重新发送到指定exchange
x-dead-letter-routing-key:出现dead letter之后将dead letter重新按照指定的routing-key发送
(2) 延迟队列使用场景
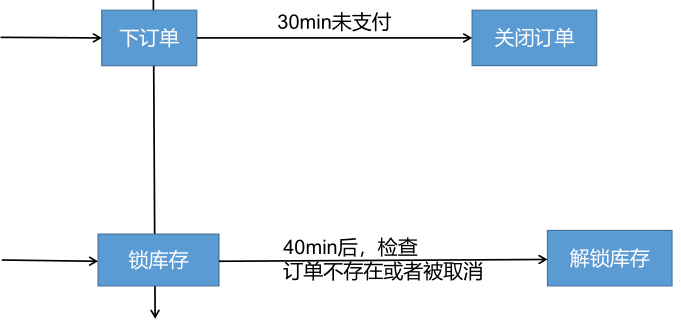
十六、Sentinel整合:
Sentinel服务流控、熔断和降级
自定义被限流响应
设置被限流后看到的页面
1 @Component 2 public class GulimallSentinelConfig 3 implements UrlBlockHandler{ 4 @Override 5 public void blocked(HttpServletRequest request, 6 HttpServletResponse response, 7 BlockException ex) throws IOException { 8 R r = R.error(BizCodeEnum.SECKILL_EXCEPTION.getCode(),BizCodeEnum.SECKILL_EXCEPTION.getMsg()); 9 response.setContentType("application/json;charset=utf-8"); 10 response.getWriter().write(JSON.toJSONString(r)+"servlet用法"); 11 } 12 }
网关流控
如果能在网关层就进行流控,可以避免请求流入业务,减小服务压力
feign的流控和降级
默认情况下,sentinel是不会对feign远程调用进行监控的,需要开启配置
feign:
sentinel:
enabled: true
在@FeignClient设置fallback属性
@FeignClient(value = "gulimall-seckill",
fallback = SeckillFallbackService.class) // 被限流后的处理类
public interface SeckillFeignService {
@ResponseBody
@GetMapping(value = "/getSeckillSkuInfo/{skuId}")
R getSeckillSkuInfo(@PathVariable("skuId") Long skuId);
}
在降级类中实现对应的feign接口,并重写降级方法
1 @Component 2 public class SeckillFallbackService implements SeckillFeignService { 3 @Override 4 public R getSeckillSkuInfo(Long skuId) { 5 return R.error(BizCodeEnum.READ_TIME_OUT_EXCEPTION.getCode(), BizCodeEnum.READ_TIME_OUT_EXCEPTION.getMsg()); 6 } 7 }
Zipkin链路追踪
由于微服务项目模块众多,相互之间的调用关系十分复杂,因此为了分析工作过程中的调用关系,需要使用zipkin来进行链路追踪
导入依赖
1 <!--链路追踪--> 2 <dependency> 3 <groupId>org.springframework.cloud</groupId> 4 <artifactId>spring-cloud-starter-zipkin</artifactId> 5 </dependency> 6 7 配置 8 9 spring: 10 zipkin: 11 base-url: http://localhost:9411 12 sender: 13 type: web 14 # 取消nacos对zipkin的服务发现 15 discovery-client-enabled: false 16 #采样取值介于 0到1之间,1则表示全部收集 17 sleuth: 18 sampler: 19 probability: 1

