
hadoop学习笔记(二)
HDFS架构图:

//linux 环境下 hadoop开发环境搭建
1.配置maven
tar -zxf apache-maven-xxxx -C /opt/modules
export MAVEN_HOME=/opt/modules/apache-maven-xxx
export PATH=$PATH:$MAVEN_HOME/bin
建立普通maven工程
pom.xml
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.5.0</version>
</dependency>
//*********************************************************************
JAVA api 文件读hdfs文件系统文件,往hdfs文件系统写文件
package com.ibeifeng.hadoop.fengyue.hdfs;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class HDFSDemo {
private static Logger log = LoggerFactory.getLogger(HDFSDemo.class);
public static void main(String[] args) {
// FileSystem fileSystem = getFileSystem();
// System.out.println(fileSystem);
// log.info(fileSystem.toString());
// readFile("");
writeFile("","");
}
/**
* getFileSystem
* @return
*/
public static FileSystem getFileSystem(){
try {
Configuration conf = new Configuration();
return FileSystem.get(conf);
} catch (Exception e) {
log.error("Exception e:",e);
}
return null;
}
public static void readFile(String filePath) {
FileSystem fileSystem = getFileSystem();
// Path path = new Path("/user/fengyue/mapreduce/wordcount/input/wc.input");
Path path = new Path(filePath);
FSDataInputStream inputStream=null;
try {
inputStream = fileSystem.open(path);
IOUtils.copyBytes(inputStream, System.out, 4096,false);
} catch (IOException e) {
log.error("readFile Exception:",e);
}finally{
if(null != inputStream){
try {
inputStream.close();
} catch (IOException e) {
log.error("readFile IOException:",e);
}
}
}
}
public static void writeFile(String sourcePath,String destPath){
FileSystem fileSystem = getFileSystem();
FileInputStream inStream=null;
FSDataOutputStream outStream =null;
try {
File file = new File(sourcePath);
inStream=new FileInputStream(file);
outStream = fileSystem.create(new Path(destPath));
IOUtils.copyBytes(inStream, outStream, 4096,false);
} catch (IllegalArgumentException e) {
log.error("writeFile IllegalArgumentException:",e);
} catch (IOException e) {
log.error("writeFile IOException:",e);
}finally{
if(null != inStream){
try {
inStream.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
if(null != outStream){
try {
outStream.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
}
//--------------------------------------
NameNode启动过程:
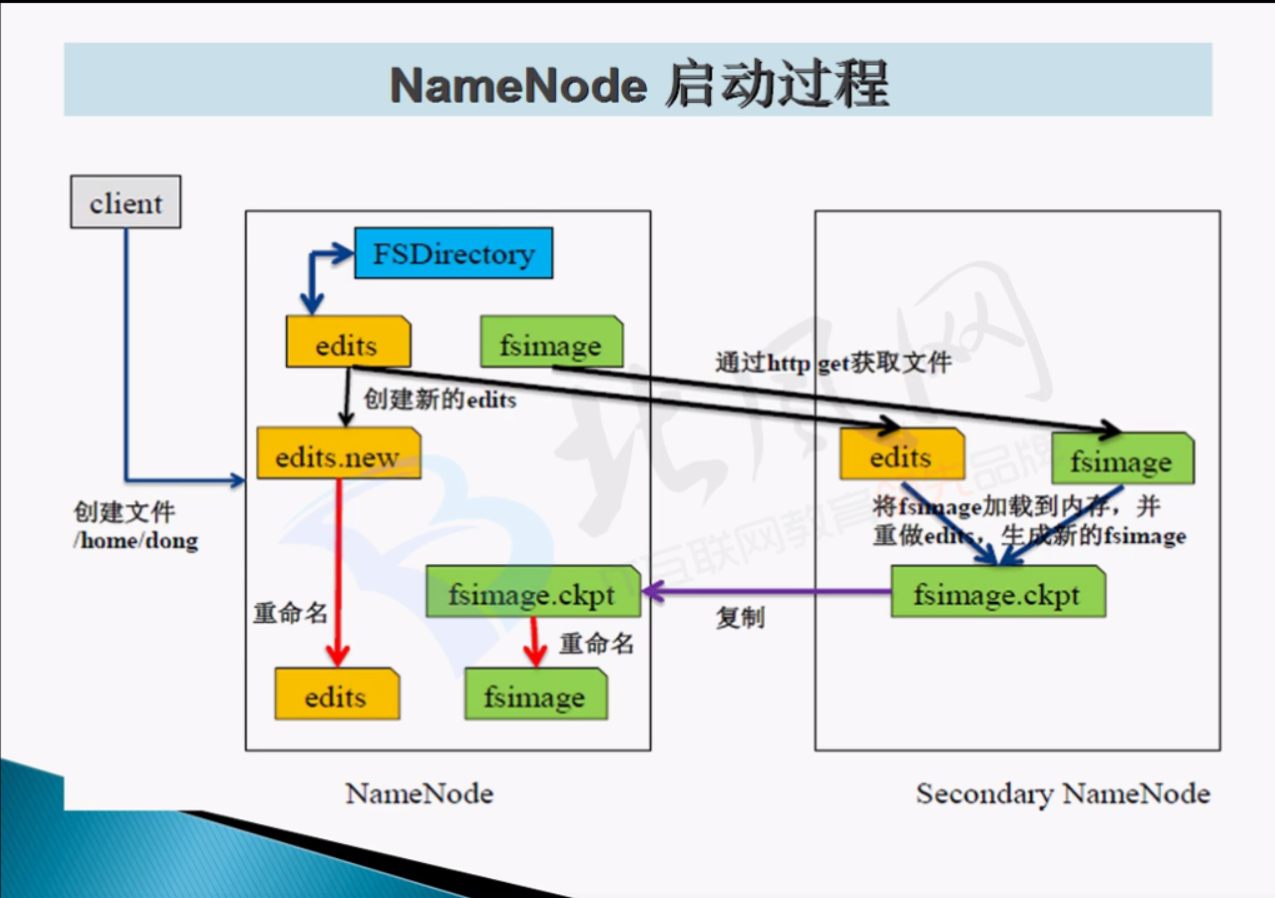
描述:
NameNode
*内存
*本地磁盘
*fsimage (存放datanode元数据)
*edits (存放hdfs文件系统的编辑日志)
第一次启动hdfs文件系统之前,需要format hdfs文件系统,目的为了生成fsimage(存放dataNode节点信息)
nameNode 启动 : 1.read fsimage元数据
datanode 启动 : 1.向namenode注册,2.定时向namenode发送节点信息报告。
//---------------------
第二次启动hdfs文件系统
1.首先读取存放在fsimage的元数据信息
2.读取edits中文件系统编辑的日志,并重新生成新的fsimage,以及空的edits,用来存储一直到下次启动hdfs的所有操作日志。
seconderynamenode的作用:为了防止一次读取的edits文件并合并到fsimage的耗时太长,此时seconderynamenode定时获取namenode的fsimage,edits,将两者合并传送到 namenode节点。并进行覆盖,防止出现namenode读取edits合并fsimage耗时过长。
具体实现见上图。
//-------------------------------
hadoop safemode(安全模式)
1.hadoop什么时候启动安全模式?
当namenode读取完fsimage,edits信息之后;datanode向namenode发送 block report 之前,启动安全模式
2.hadoop什么时候退出安全模式?
当namenode读取的block总数 / 所有datanode发送到namenode的block之和 =99.99% ,此时整个文件系统中,几步不存在损坏块的情况下,安全模式退出!
3.安全模式运行时,不能够对文件系统做哪些操作?能够对文件系统的操作?
不能操作:
1.修改文件系统的命名空间
*创建文件夹 *删除文件 * 上传文件 ...
能操作:
查看文件系统的文件内容。
退出安全模式: bin/hdfs dfsadmin -safemode leave
YARN

nodeManager 配置:
/*CPU核心数*/
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>4</value>
</property>
/*内存大小*/
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>16384</value>
</property>
yarn 生态系统:
MapReduce 处理过程
input --> map --> reduce --> output
intput :------>>>>>>>
hadoop xiaoming
hadoop fengyue xiaoming
hadoop wuyue xiaomingj
hadoop haha
yarn hehe
yarn gaga
yeye iop
haha
wuyue
map:------>>>>>>>>>>>
hadoop xiaoming <key,value> >>>> <0,"hadoop xiaoming">
hadoop fengyue xiaoming <key,value> >>>> <16,"hadoop fengyue xiaoming">
hadoop wuyue xiaomingj
hadoop haha
yarn hehe
yarn gaga
yeye iop
haha
wuyue
------> <hadoop,1> ,<xiaoming,1> <hadoop,1> <fengyue,1> <xiaoming,1>
reduce:------>>>>>>>>>>>>>>>>>>
统计key==关键字的数量,将数量写入value
output:--------->>>>>>>>>>>>>>>>>>>>>>>>>>
fengyue 1
gaga 1
hadoop 4
haha 2
hehe 1
iop 1
wuyue 2
xiaoming 2
xiaomingj 1
yarn 2
yeye 1
mapreduce 程序架构:

wordCount程序:
package com.ibeifeng.hadoop.fengyue.hdfs;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
public class MapReduce extends Configured implements Tool {
public static void main(String[] args) {
try {
int run = new MapReduce().run(args);
System.exit(run);
} catch (Exception e) {
e.printStackTrace();
}
}
//Text 可以理解为String ; LongWritable 理解为hadoop对long的封装类型
public static class MapperMethod extends
Mapper<LongWritable, Text, Text, IntWritable> {
private Text wordKeys = new Text();
private IntWritable initIntWritable = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String valueStr = value.toString();
StringTokenizer tokenizer = new StringTokenizer(valueStr);
while (tokenizer.hasMoreTokens()) {
wordKeys.set(tokenizer.nextToken());
context.write(wordKeys, initIntWritable);
}
}
}
public static class ReducerMethod extends
Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
context.write(key, new IntWritable(sum));
}
}
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, this.getClass().getSimpleName());
job.setJarByClass(MapReduce.class);
job.setJobName("word_count");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(MapperMethod.class);
job.setReducerClass(ReducerMethod.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
boolean completion = job.waitForCompletion(true);
return completion ? 0 : 1;
}
}
shuffle详解:
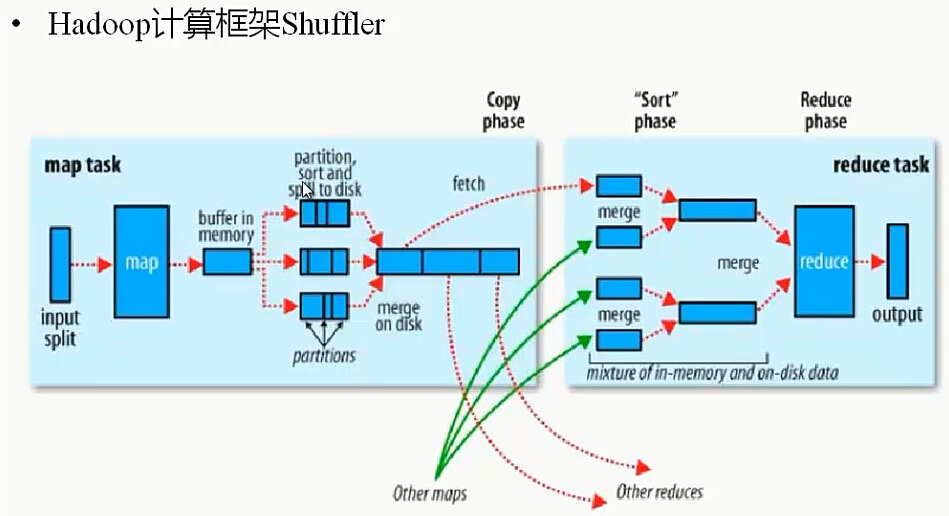
过程:
*step1:
input
InputFormat:1.读取数据 2.将数据转换为key,value
FileInputFormat
*TextInputFormat
*step2:
map
extend Mapper
map(KEYIN,VALUEIN,KEYOUT,VALUEOUT)
*step3:
shuffle
1.从map输出内容读取数据存放在memory中,当超过特定值,则spill(溢写)到本地磁盘中
2.将文件进行parttition(分区),sort(排序)
3.将分区,排序后的小文件,进行merge(合并),sort(排序),combiner(map中,短合并)->大文件 compress(可以压缩)
4.此时reduce开始工作,向每个map copy拷贝数据
5.对所有从map获取的数据,进行 合并,sort(排序),group(分组,将相同key的value放在一起)
6.此时reduce中业务逻辑处理分组后的value
*step4:
reduce
reduce(KEYIN,VALUEIN.KEYOUT,VALUEOUT)
map的输出===reduce的输入
*step5:
output
outputFormat
fileOutPutFormat
TextOutPutFormat
每一个key,value对输出一行,默认调用key,value的toString()方法
shuffle过程中,可操作的
1.分区 parttition
2.排序 sort
3.combiner map task中的短reduce
4.压缩 compress 将map处理好的文件进行压缩,可以提高reduce的效率,较少网络延迟
5.拷贝 copy (用户无法操作的过程)
6.合并 merge 将reduce从各个map读取来的数据进行合并
7.排序 sort
8.分组 group
以上过程,只有copy不可人工操作,其余根据业务需求,均可操作。
java:
//**************shuffle***********************
job.setPartitionerClass(cls);// fenqu
job.setSortComparatorClass(cls);//paixu
job.setCombinerClass(cls); //combiner
job.setGroupingComparatorClass(cls); //group
//**************shuffle***********************
shuffle压缩配置:
//默认不开启
<property>
<name>mapreduce.map.output.compress</name>
<value>false</value>
<description>Should the outputs of the maps be compressed before being
sent across the network. Uses SequenceFile compression.
</description>
</property>
//设置压缩格式
<property>
<name>mapreduce.map.output.compress.codec</name>
<value>org.apache.hadoop.io.compress.DefaultCodec</value>
<description>If the map outputs are compressed, how should they be
compressed?
</description>
</property>
hadoop压缩格式:


shuffle过程中于hdfs文件系统,以及本地磁盘的交互:
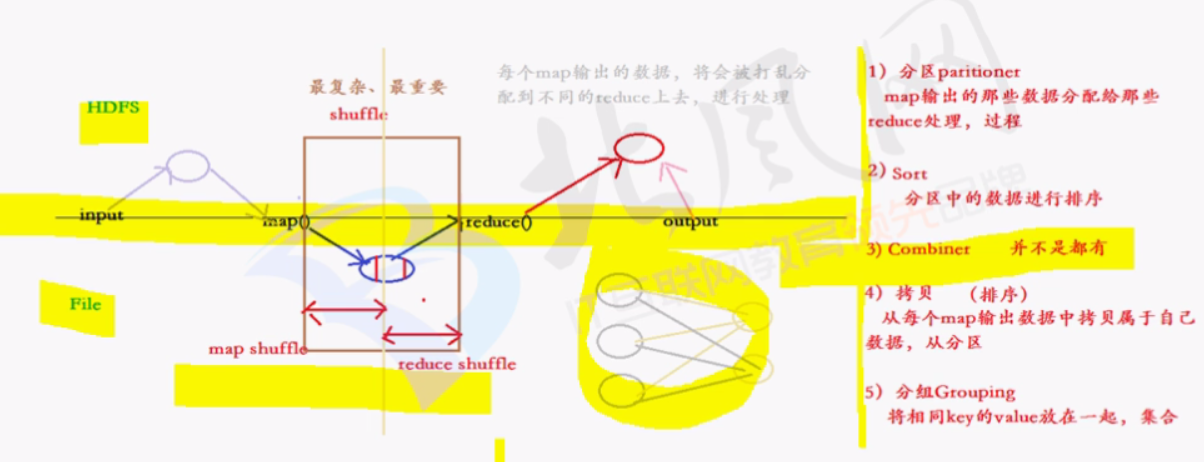
mapreduce优化:
1.shuffle过程中,对于map分区,排序后,可进行combiner(map的短reduce)
2.combiner之后,可以将本地磁盘中的文件进行压缩,减少本地磁盘IO的读写,减少网路延迟
3.创建适当个数的reduce来处理mapTask的文件
如何设置reduce的个数?
<property>
<name>mapreduce.job.reduces</name>
<value>1</value>
</property>
当map从hdfs文件系统读取文件后,暂放内存,再溢写到本地磁盘,这里的内存大小如何设置?
<property>
<name>mapreduce.task.io.sort.mb</name>
<value>100</value>
</property>
<property>
<name>mapreduce.map.sort.spill.percent</name>
<value>0.80</value>
</property>
内存大小==100MB*0.8 //可设置
