

翻译 Improved Word Representation Learning with Sememes
翻译 Improved Word Representation Learning with Sememes
题目
Improved Word Representation Learning with Sememes
融合义原知识的词汇表示学习
摘要 Abstract
Sememes are minimum semantic units of word meanings, and the meaning of each word sense is typically composed by several sememes.
义原是词语含义最小的语义单元,通常每一个词语的词义是由几个义原组成的。
Since sememes are not explicit for each word, people manually annotate word sememes and form linguistic common-sense knowledge bases.
因为对于每一个词语来说,义原不是明确地天然存在的,所以需要人们手工地标注词语义原并最终形成语义常识知识库。
In this paper, we present that, word sememe information can improve word representation learning (WRL), which maps words into a low-dimensional semantic space and serves as a fundamental step for many NLP tasks.
本文提出了词语义原信息可以用来提升词表示学习(WRL)。词表示学习是把词语映射到一个低维的语义空间中,充当了很多 NLP 任务的基石。
The key idea is to utilize word sememes to capture exact meanings of a word within specific contexts accurately.
关键思想是利用词语义原,准确地捕获特定上下文中单词的确切含义。
More specifically, we follow the frameworkofSkip-gramandpresentthree sememe-encoded models to learn representations of sememes, senses and words, where we apply the attention scheme to detect word senses in various contexts.
更具体地说,我们在继承 Skip-Gram 框架的基础上,提出了三种义原编码(sememe-encoded)模型来学习义原、意识和词语的表示,在各种各样的上下文中使用注意力机制来发现词语意识。
We conduct experiments on two tasks includingwordsimilarityandwordanalogy, and our models significantly outperform baselines.
我们在词语相似度和词语类推两项任务上实施实验,我们的模型在这两项任务上比基线系统取得了更好的表现。
The results indicate that WRL canbenefitfromsememesviatheattention scheme, and also confirm our models beingcapableofcorrectlymodelingsememe information.
结果表明,词语表示学习可以通过注意力机制从义原中获益,并且也证实了我们的模型能够正确地建模义原信息。
1 引言 Introduction
Sememes are defined as minimum semantic units of word meanings, and there exists a limited close set of sememes to compose the semantic meanings of an open set of concepts (i.e. word sense).
义原被定义为词语的最小语义单元,并且存在一个义原的有限集来组成概念的一个语义开放集。(例如知网)
However, sememes are not explicit for each word.
然而,每个词的义原不是明确的。
Hence people manually annotate wordsememesandbuildlinguisticcommon-sense knowledge bases.
因此,人们手工地标注词语义原并且建立语义常识知识库。
HowNet (Dong and Dong, 2003) is one of such knowledge bases, which annotates each concept in Chinese with one or more relevant sememes.
知网是一个在中文领域,用一个或多个相关义原标注了概念的知识库。
Different from WordNet (Miller, 1995), the philosophy of HowNet emphasizes the significance of part and attribute represented by sememes.
与WordNet(Mulle,1995)不同,知网哲学强调了义原所代表的部分(part)和属性(attribute )的意义。
HowNet has been widely utilized in word similarity computation (Liu and Li, 2002) and sentiment analysis (Xianghuaetal.,2013), and in section 3.2 we will give a detailed introduction to sememes, senses and words in HowNet.
知网被广泛应用于词语相似度计算和语义分析当中,在 3.2节中我们将对知网中的义原(sememes)、语义(senses )和词语进行详细的介绍。
In this paper, we aim to incorporate word sememes into word representation learning (WRL) and learn improved word embeddings in a low dimensional semantic space.
本文目标在于使词语义原成为词表示学习的一部分,并且在低维语义空间中学习改进的词嵌入。
WRL is a fundamental and critical step in many NLP tasks such as language modeling (Bengio et al., 2003) and neural machine translation (Sutskever et al., 2014).
词表示学习在很多NLP任务中是基石和关键步骤,例如语言模型和神经机器翻译。
There have been a lot of researches for learning word representations, among which word2vec (Mikolov et al., 2013) achieves a nice balance between effectiveness and efficiency.
曾经有许多词表示学习的研究,其中,word2vec 取得了有效性和效率之间的平衡。
In word2vec, each word corresponds to one single embedding, ignoring the polysemy of most words.
在 word2vec 中,每一个单词对应于一个单一的嵌入,忽略了大多数词的歧义。
To address this issue, (Huang et al., 2012) introduces a multi prototype model for WRL, conducting unsupervised word sense induction and embeddings according to context clusters.
为了解决这个问题,(Huang et al., 2012) 提出了一种面向词表示学习的多原型模型,根据上下文聚类进行无监督的词义归纳和嵌入。
(Chenetal.,2014) further utilizes the synset information in WordNet to instruct word sense representation learning.
(Chenetal.,2014) 更进一步利用 WordNet 中的同义词集(synset)信息来指导词语语义表示学习。
From these previous studies, we conclude that word sense disambiguation are critical for WRL, and we believe that the sememe annotation of word senses in HowNet can provide necessary semantic regularization for the both tasks.
从之前的这些研究中,我们总结出词义分布式表示对词语表示学习是至关重要的,并且我们相信对于以上任务,词语词义的义原标注可以提供必要的语义规则。
To explore its feasibility, we propose a novel Sememe-Encoded Word Representation Learning
(SE-WRL) model, which detects word senses and learns representations simultaneously.
为了探索其可行性,我们提出了一种新奇的,同时发现词义和学习表示的义原编码词表示学习模型。
More specifically, this framework regards each word sense as a combination of its sememes, and iteratively performs word sense disambiguation according to their contexts and learn representations of sememes, senses and words by extending Skip-gram in word2vec (Mikolov et al., 2013).
更具体地说,该框架将每个词语词义视为其义原的组合,并根据其上下文迭代地执行词语词义消歧,并通过在 word2vec (Mikolov et al., 2013) 中扩展 Skip-Gram 来学习义原、词义和词的表示。
In this framework, an attention-based method is proposed to select appropriate word senses according to contexts automatically.
在该模型中,提出了一种基于注意力机制的方法,自动地根据上下文选取合适的词语词义。
To take full advantages of sememes, we propose three different learning and attention strategies for SE-WRL.
为了充分发挥义原的优势,我们为 SE-WRL 提出了三种不同的学习和注意力策略。
In experiments, we evaluate our framework on two tasks including word similarity and word analogy, and further conduct case studies on sememe, sense and word representations.
在实验中,我们在词语相似度和词语类推两个任务上评测我们的框架,并且进一步开展对义原、词义和词表示的个案研究。
The evaluation results show that our models outperform other baselines significantly, especially on word analogy.
评测结果显示,我们的模型表现远超基线系统,尤其是词语类推任务。
This indicates that our models can build better knowledge representations with the help of sememe information, and also implies the potential of our models on word sense disambiguation.
这显示了我们的模型在义原信息的帮助下,可以更好地建立知识表示,还意味着我们的模型在词语语义消歧上的潜力。
The key contributions of this work are concluded as follows: (1) To the best of our knowledge, this is the first work to utilize sememes in HowNet to improve word representation learning.
本文工作的主要贡献在于:(1)据我们所知,这是第一个利用知网中义原来提升词表示的工作。
(2) We successfully apply the attention scheme to detect word senses and learn representations according to contexts with the favor of the sememe annotation in HowNet.
在知网中义原标注的帮助下,我们成功地应用注意力机制来检测词语语义,并根据上下文学习表示。
(3) We conduct extensive experiments and verify the effectiveness of incorporating word sememes for improved WRL.
我们执行了广泛的实验并验证了对于提升词表示学习,结合词语义原的有效性。
2 相关工作 Related Work
2.1 词表示 Word Representation
Recent years have witnessed the great thrive in word representation learning.
今年来,词表示学习蓬勃发展。
It is simple and straightforward to represent words using one-hot representations, but it usually struggles with the data sparsity issue and the neglect of semantic relations between words.
使用独热(one-hot)表示词是简单而且直接的。但是它受困于数据稀疏问题,并忽视了词语之间的语义关系。
To address these issues, (Rumelhart et al., 1988) proposes the idea of distributed representation which projects all words into a continuous low-dimensional semantic space, considering each word as a vector.
为了解决上述问题,(Rumelhart et al., 1988) 提出了分布式表示这一想法,把所有词语投射到一个连续的低维语义空间中,把每一个词都考虑成一个向量。
Distributed word representations are powerful and have been widely utilized in many NLP tasks, including neural language models (Bengioetal.,2003; Mikolovetal.,2010), machine translation (Sutskeveretal.,2014; Bahdanau et al., 2015), parsing (Chen and Manning, 2014) and text classification (Zhang et al., 2015).
分布式词表示是强大的,并且被广泛应用于主要的 NLP 任务当中,包括:神经语言模型 (Bengioetal.,2003; Mikolovetal.,2010),机器翻译 (Sutskeveretal.,2014; Bahdanau et al., 2015), 分析器 (Chen and Manning, 2014) 和文本分类 (Zhang et al., 2015)。
Word distributed representations are capable of encoding semantic meanings in vector space, serving as the fundamental and essential inputs of many NLP tasks.
词语分布式表示能够在向量空间中对语义进行编码,然后在主要的 NLP 任务中作为基础的和基本的输入。
There are large amounts of efforts devoted to learning better word representations.
已经有大量的努力投入到学习更好的词表示当中。
As the exponential growth of text corpora, model efficiency becomes an important issue.
与文本语料呈指数级增长的同时,模型效率成为了一个重要的问题。
(Mikolov et al., 2013) proposes two models, CBOW and Skip-gram, achieving a good balance between effectiveness and efficiency.
(Mikolov et al., 2013) 提出了 CBOW 和 Skip-Gram 两种模型,在效率和有效性上取得了很好的平衡。
These models assume that the meanings of words can be well reflected by their contexts, and learn word representations by maximizing the predictive probabilities between words and their contexts.
以上模型假设词语的含义可以通过上下文很好的表达出来,并且通过最大化词和上下文的预测概率来学习词表示。
(Pennington et al., 2014) further utilizes matrix factorization on word affinity matrix to learn word representations.
(Pennington et al., 2014) 进一步地在词近似度矩阵(word affinity matrix)上,利用矩阵分解来学习词表示。
However, these models merely arrange only one vector for each word, regardless of the fact that many words have multiple senses.
然而,这些模型仅仅为每个词只安排一个向量,没有考虑到一词多义的情况。
(Huang et al., 2012; Tian et al., 2014) utilize multi-prototype vector models to learn word representations and build distinct vectors for each word sense.
(Huang et al., 2012; Tian et al., 2014) 利用多原型向量模型学习词表示,并为每个词义建立不同的向量。
(Neelakantan et al., 2015) presents an extension to Skip-gram model for learning non-parametric multiple embeddings per word.
(Neelakantan et al., 2015) 提出了一种对每个单词进行非参数多嵌入学习的 Skip-Gram 模型的扩展。
(Rothe and Sch¨utze, 2015) also utilizes an Autoencoder to jointly learn word, sense and synset representations in the same semantic space.
在同一个语义空间中,(Rothe and Sch¨utze, 2015) 也提出了一种用来联合学习词语、语义和近义词表示的自编码器。
This paper, for the first time, jointly learns representations of sememes, senses and words.
本文首次联合学习了义原、词义和词语的表示。
The sememe annotation in HowNet provides useful semantic regularization for WRL.
知网中的义原标注为词表示学习提供了令人满意的语义规则。
Moreover, the unified representations incorporated with sememes also provide us more explicit explanations of both word and sense embeddings.
此外,结合语义的统一表示也给我们提供了词语和语义嵌入更清楚的解释。
2.2 词义消歧和表示学习 Word Sense Disambiguation and Representation Learning
Word sense disambiguation (WSD) aims to identify word senses or meanings in a certain context computationally
词义消歧(WSD)目标是在确定的上下文中计算上的识别出词语的词义和意识。
There are mainly two approaches for WSD, namely the supervised methods and the knowledge-based methods.
有两种途径来实现词义消歧,即有监督方法和基于知识的方法。
Supervised methods usually take the surrounding words or senses as features and use classifiers like SVM for word sense disambiguation (Leeetal.,2004), which are intensively limited to the time-consuming human annotation of training data.
有监督方法通常采用把周围词或周围词的词义当作特征,然后使用像是 SVM 这样的分类器来进行词义消歧。该方法严重受限于耗时的人工训练数据标注过程。
On contrary, knowledge-based methods utilize large external knowledge resources such as knowledge bases or dictionaries to suggest possible senses for a word.
而恰恰相反,基于知识的方法利用大量的外部知识资源,例如知识库或字典,来为词语建议可能的语义。
(Banerjee and Pedersen, 2002) exploits the rich hierarchy of semantic relations in WordNet (Miller,1995) for an adapted dictionary based WSD algorithm.
(Banerjee and Pedersen, 2002) 利用 WordNet 丰富的层级语义关系来改进基于字典的词义消歧算法。
(Bordesetal.,2011) introduces synset information in WordNet to WRL.
为解决词义消歧,(Bordesetal.,2011) 引入同义词集信息到 WordNet。
(Chen et al., 2014) considers synsets in WordNet as different word senses, and jointly conducts word sense disambiguation and word / sense representation learning.
(Chen et al., 2014) 认为 WordNet 的同义词集与词语词义不同,并联合执行词语语义消歧和词语/词义表示学习。
(Guo et al., 2014) considers bilingual datasets to learn sense-specific word representations.
(Guo et al., 2014) 考虑双语数据集来学习词义特性(sense-specific)词表示。
(Pilehvar and Collier, 2016) utilizes personalized PageRank to learn de-conflated semantic representations of words.
(Pilehvar and Collier, 2016) 利用个性化的 PageRank 来学习去合并的(de-conflated)的词语语义表示。
In this paper, we follow the knowledge-based approach and automatically detect word senses according to the contexts with the favor of sememe information in HowNet.
在本文中,借助于知网义原信息的帮助下,我们继承基于知识的方法自动地根据上下文检测词语语义。
To the best of our knowledge, this is the first attempt to apply attention based models to encode sememe information for word representation learning.
据我们所知,这是第一次在词语表示学习任务上,应用注意力模型来编码义原信息的尝试。
3 方法 Methodology
In this section, we present our framework Sememe-Encoded WRL (SE-WRL) that considers sememe information for word sense disambiguation and representation learning.
在本节中,我们提出了义原编码词语表示学习(SE-WRL)框架。该框架为词语语义消歧和表示学习任务,考虑了义原信息。
Specifically, we learn our models on a large-scale text corpus with the semantic regularization of the sememe annotation in HowNet and obtain sememe, sense and word embeddings for evaluation tasks.
特别地,我们的模型在使用知网义原标注信息的义原规则下,在一个大规模文本语料上学习,并面向评测任务得到了义原、语义和词嵌入。
In the following sections, we first introduce HowNet and the structures of sememes, senses and words.
在接下来的小节中,我们首先介绍知网和义原、语义和词语的结构。
Then we discuss the conventional WRL model Skip-gram that we utilize for the sememe encoded framework.
然后,我们讨论我们利用它来编码义原的框架,传统的词语表示学习模型——Skip-Gram。
Finally, we propose three sememe-encoded models in details.
最后,我们提出三种义原编码模型的细节。
3.1 知网中的义原、语义和词语 Sememes, Senses and Words in HowNet
In this section, we first introduce the arrangement of sememes, senses and words in HowNet.
在本节中,我们首先介绍知网中义原、语义和词语的约定。
HowNet annotates precise senses to each word, and for each sense, HowNet annotates the significance of parts and attributes represented by sememes.
知网为每一个词标注了严谨的语义,对于每一个语义,知网用义原注释了其所代表的成分(part)和属性(attribute)的意义。
Fig. 1gives an example of sememes, senses and words in HowNet.
图1 给出了知网中义原、语义和词语的一个例子。
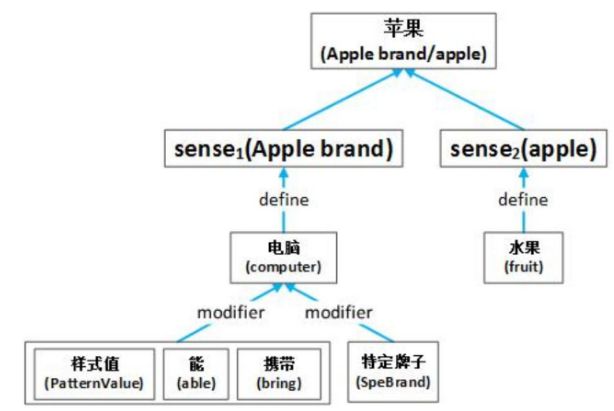
The first layer represents the word “apple”.
第一层表示词语“苹果”。
The word “apple” actually has two main senses shown on the second layer : one is a sort of juicy fruit (apple), and another is a famous computer brand (Apple brand).
严谨地说,第二层显示“苹果”一个有两个含义,一个是一种水果,另一个是一个著名的电脑品牌。
The third and following layers are those sememes explaining each sense.
接下来的第三层中是每一个语义各自的义原解释。
For instance, the first sense Apple brand indicates a computer brand, and thus has sememes computer, bring and SpeBrand.
在上面的例子中,第一个语义表明苹果是一个电脑品牌,因此它有三个义原:电脑、携带和特定牌子。
From Fig. 1 we can find that, sememes of many senses in HowNet are annotated with various relations, such as define and modifier, and form complicated hierarchical structures.
从图1中,我们可以发现:知网中很多语义的义原被各种各样的关系标注,例如“定义”、“修饰语”,并形成了复杂的层级结构。
In this paper, for simplicity, we only consider all annotated sememes of each sense as a sememe set without considering their internal structure.
在本文中,为了简化问题,我们只把每个语义的全部标注的义原考虑为一个集合,不考虑它们的内部结构。
HowNet assumes the limited annotated sememes can well represent senses and words in the real-world scenario, and thus sememes are expected to be useful for both WSD and WRL.
知网假设现实世界中的情景,可以被有限的标记好的义原很好地表示出来。因此义原被认为可以很好地应用于语义消歧和词表示学习。
We introduce the notions utilized in the following sections as follows.
我们将介绍以下章节中使用到的概念。
We define the overall sememe, sense and word sets used in training as X, S and W respectively.
我们分别定义训练中所有的义原、语义和词语集合为 X, S 和 W。
For each , there are possible multiple senses where represents the sense set of .
代表 w 的语义的集合,对于每一个 ,存在一个或多个语义 。
Each sense consists of several sememes .
每一个语义 由几个义原 组成。
For each target word in a sequential plain text, represents its context word set.
对于每一条纯文本序列中的目标字 , 代表它的上下文词语集合。
3.2 传统的 Skip-Gram 模型 Conventional Skip-Gram Model
We directly utilize the widely-used model Skip-Gram to implement our SE-WRL model, because Skip-Gram has well balanced effectiveness as well as efficiency (Mikolov et al., 2013).
由于 Skip-Gram 有着良好的有效性和良好的效率以及两者之间的良好的平衡 (Mikolov et al., 2013),我们直接利用广泛使用的 Skip-Gram 模型来实现我们的 SE-WRL 模型。
The standard skip-gram model assumes that word embeddings should relate to their context words.
标准的 skip-gram 模型假设词嵌入应与其上下文有关。
It aims at maximizing the predictive probability of context words conditioned on the target word w.
它的目标是最大化上下文在当前词的条件下的预测概率。
Formally, we utilize a sliding window to select the context word set .
形式上,我们利用一个滑动窗口来选择上下文词语集合 。
For a word sequence ,Skip-Gram model intends to maximize:
where is the size of sliding window.
对于一个词语序列 ,Skip-Gram 模型想要最大化
这里, 是滑动窗口的大小。
represents the predictive probability of context words conditional on the target word , formalized by the following softmax function:
in which and stand for embeddings of context word and target word respectively.
表示在当前词 的条件下,上下文的预测概率。由以下 softmax 函数形式化给出:
其中, 和 代表上下文 和当前词的词嵌入。
We can also follow the strategies of negative sampling proposed in (Mikolov et al., 2013) to accelerate the calculation of softmax.
我们也可以继承 (Mikolov et al., 2013) 提出的继承负采样策略,来加速 softmax 计算。
3.3 SE-WRL 模型 SE-WRL model
In this section, we introduce the SE-WRL models with three different strategies to utilize sememe information, including Simple Sememe Aggregation Model (SSA), Sememe Attention over Context Model (SAC) and Sememe Attention over Target Model (SAT).
在本节中,我们将会介绍 SE-WRL 模型的三种应用义原信息的不同策略。包括简单义原聚集模型 (SSA),基于上下文的义原注意力模型(SAC)和基于目标词的义原注意力模型(SAT)。
3.3.1 简单义原聚集模型 Simple Sememe Aggregation Model
The Simple Sememe Aggregation Model (SSA) is a straightforward idea based on Skip-gram model.
简单义原聚集模型是一个基于 Skip-Gram 模型的直截了当的想法。
For each word, SSA considers all sememes in all senses of the word together, and represents the target word using the average of all its sememe embeddings.
对于每一个词,SSA 把所有词语的语义的义原一同考虑进来,用目标词的所有上下文的义原嵌入(embedding)的平均值来表示当前词。
Formally, we have:
which means the word embedding of is composed by the average of all its sememe embeddings.
形式上,我们用下式来表示,当前词的词嵌入由它上下文义原嵌入的平均值来构成:
Here, stands for the overall number of sememes belonging to .
其中, 表示所有属于 的义原数量。
This model simply follows the assumption that, the semantic meaning of a word is composed of the semantic units, i.e., sememes.
该模型朴素地继承了这样的假设,即一个词语的语义由语义单元组成,例如义原。
As compared to the conventional Skip-gram model, since sememes are shared by multiple words, this model can utilize sememe information to encode latent semantic correlations between words.
与传统的 skip-gram 模型相比,因为义原被多个词共享,所以该模型可以利用义原信息来编码词语之间隐含的语义关联。
In this case, similar words that share the same sememes may finally obtain similar representations.
在本例中,相似词共享相同的义原,最终可能会获得相似的表示。
3.3.2 基于上下文的义原注意力模型 Sememe Attention over Context Model
The SSA Model replaces the target word embedding with the aggregated sememe embeddings to encode sememe information into word representation learning.
SSA 模型用聚集的义原嵌入来代替目标词词嵌入,用义原信息编码来进行词表示学习。
However, each word in SSA model still has only one single representation in different contexts, which cannot deal with polysemy of most words.
然而,在不同的上下文中,SSA 模型中的每一个词仍然只有一个单独的表示。它不能处理大多数词的多义词现象。
It is intuitive that we should construct distinct embeddings for a target word according to specific contexts, with the favor of word sense annotation in HowNet.
直觉上,我们应该借助知网词语语义的标注,根据特定的上下文为目标词生成不同的嵌入。
To address this issue, we come up with the Sememe Attention over Context Model (SAC).
为了解决这个问题,我们提出了基于上下文的义原注意力模型(SAC)。
SAC utilizes the attention scheme to automatically select appropriate senses for context words according to the target word.
SAC 利用注意力机制,根据当前词自动地选择上下文合适的语义。
That is, SAC conducts word sense disambiguation for context words to learn better representations of target words.
换句话说,为了学习更好的目标词词表示,SAC 为上下文执行词语语义消歧。
The structure of the SAC model is shown in Fig. 2.
SAC 模型的结构在图二中展示。
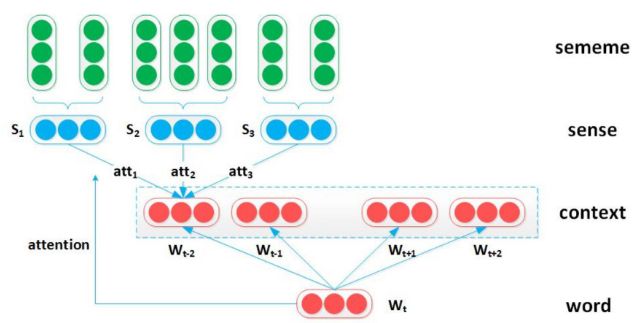
More specifically, we utilize the original word embedding for target word , but use sememe embeddings to represent context word instead of original context word embeddings.
更确切地说,我们为目标词 使用原始的词嵌入,使用义原嵌入来表示上下文中的词 ,而不是使用原始的上下文词嵌入。
Suppose a word typically demonstrates some specific senses in one sentence.
假设一个词通常在一个特定的句子中表现出一些特定的语义。
Here we employ the target word embedding as an attention to select the most appropriate senses to make up context word embeddings.
在这里,我们使用目标词的词嵌入作为一个注意力,去选取更合适的语义来生成上下文词嵌入。
We formalize the context word embedding as follows:
where stands for the -th sense embedding of , and represents the attention score of the -th sense with respect to the target word , defined as follows:
我们用如下的式子来形式化上下文词嵌入 :
其中, 代表 的第 个语义嵌入, 代表关于目标词 的第 个语义的注意力得分。 定义如下:
Note that, when calculating attention, we use the average of sememe embeddings to represent each sense :
请注意,当计算注意力的时候,我们使用语义嵌入的平均值来表示每一个语义 .
The attention strategy assumes that the more relevant a context word sense embedding is to the target word , the more this sense should be considered when building context word embeddings.
在建立上下文词向量的时候,注意力策略假设:上下文的词语嵌入与当前词 越相关,那么越应该被考虑。
With the favor of attention scheme, we can represent each context word as a particular distribution over its sense.
在注意力机制的帮助下,我们可以把每个上下文的语义表示为一个语义上具体的分布。
This can be regarded as soft WSD.
这可以被认为是“软词语语义消歧”(soft WSD)。
As shown in experiments, it will help learn better word representations.
如实验所示,这将会帮助学习更好的词语表示。
3.3.3 基于目标词的义原注意力模型 Sememe Attention over Target Model
The Sememe Attention over Context Model can flexibly select appropriate senses and sememes for context words according to the target word.
基于上下文的义原注意力模型,可以根据当前词灵活地为上下文选取合适的语义和义原。
The process can also be applied to select appropriate senses for the target word, by taking context words as attention.
这个过程也可以被用来为目标词选取合适的义原,通过对上下文词语使用注意力。
Hence, we propose the Sememe Attention over Target Model (SAT) as shown in Fig.3.
因此,我们提出了基于目标词的义原注意力模型,如图三。
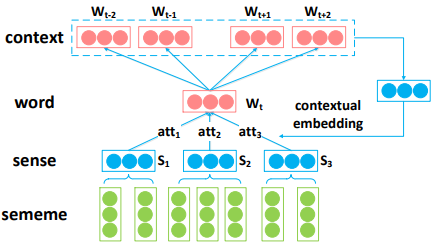
Different from SAC model, SAT learns the original word embeddings for context words, but sememe embeddings for target words.
与 SAC 模型不同,SAT 为上下文词语学习原始的词嵌入,但是为目标词学习义原嵌入。
We apply context words as attention over multiple senses of the target word to build the embedding of , formalized as follows:
where stands for the -th sense embedding of , and the context-based attention is defined as follows:
where, similar to Eq. (6), we also use the average of sememe embedding to represent each sense .
我们在目标词 的多个语义上,应用上下文词语作为注意力,来建立 的嵌入,形式化给出:
其中, 代表 的第 个语义嵌入。基于上下文的注意力被定义如下:
与等式 (6) 相似。其中,我们同样使用义原嵌入的平均值来表示每一个语义 。
Here, is the context embedding, consisting of a constrained window of word embeddings in .
这时, 是由 中受限窗口内的词嵌入,组成的上下文嵌入。
we have:
我们有:
Note that, since in experiment we find the sense selection of the target word only relies on more limitied context words for calculating attention, hence we select a smaller as compared to .
请注意,因为在实验中我们发现,目标词语义的选取仅依赖于更为有限的上下文来计算注意力。因此我们选取了比 更小的 。
Recall that, SAC only uses one target word as attention to select senses of context words, but SAT uses several context words together as attention to select appropriate senses of target words.
回想一下,SAC 只使用一个目标词作为注意力来选择上下文词语的语义,但是 SAT 同时使用一些上下文作为注意力来选择适合目标词的语义。
Hence SAT is expected to conduct more reliable WSD and result in more accurate word representations, which will be explored in experiments.
因此,接下来的实验将会证明: SAT 应该会在词语消歧(WSD)任务上更可靠,而且具有更准确的词语表示能力。
4 实验 Experiments
In this section, we evaluate the effectiveness of our SE-WRL models on two tasks including word similarity and word analogy, which are two classical evaluation tasks mainly focusing on evaluating the quality of learned word representations.
在本节中,我们将会评测我们的 SE-WRL 模型,在词语相似度和词语类推这两项任务上的有效性。这是两个经典的、聚焦在评价词语表示学习质量上的评测任务。
We also explore the potential of our models in word sense disambiguation with case study, showing the power of our attention-based models.
在个案研究的帮助下,我们也会探索我们的模型在词语语义消歧上的潜力,并展示我们基于注意力模型的威力。
4.1 数据集 Dataset
We use the web pages in Sogou-T as the text corpus to learn WRL models.
我们使用 Sougou-T 中的网页作为文本语料来训练我们的词语表示学习(WRL)模型。
Sogou-T is provided by a Chinese commercial search engine, which contains 2.7 billion words in total.
Sougou-T 由中国商业搜索引擎公司提供,内含总计 27 亿词。
We also utilize the sememe annotation in HowNet.
我们也会使用知网中的义原标注。
The number of distinct sememes used in this paper is 1, 889.
论文中使用到的不同的义原有 1889 个。
The average senses for each word are about 2.4, while the average sememes for each sense are about 1.6.
每个词平均的语义大约有 2.4 个,每个语义平均的义原有 1.6 个。
Throughout the Sogou-T corpus, we find that 42.2% of words have multiple senses.
纵观整个 Sougou-T 语料,我们发现 42.2 % 的词语具有多个语义。
This indicates the significance of WSD.
这表明了词语消歧的意义。
For evaluation, we choose wordsim-240 and wordsim-297 to evaluate the performance of word similarity computation.
为了评测,我们选取了 wordsim-240 和 wordsim-297 来评测词语相似度计算的性能。
The two datasets both contain frequently-used Chinese word pairs with similarity scores annotated manually.
这两个数据集包括了常用的中文词语词对(word pair)和手工标记的相似度打分。
We choose the Chinese Word Analogy dataset proposed by (Chen et al., 2015) to evaluate the performance of word analogy inference, that is, w(“king”) − w(“man”) w(“queen”) − w(“woman”) .
我们选取了 (Chen et al., 2015) 提出的中文词语类推数据集,来评价词语类推推断的性能,也即 w(“king”) − w(“man”) w(“queen”) − w(“woman”) .
4.2 实验设置 Experimental Settings
We evaluate three SE-WRL models including SSA, SAC and SAT on all tasks.
我们在全部的任务中,评测 SSA, SAC 和 SAT 这三个 SE-WRL 模型。
As for baselines, we consider three conventional WRL models including Skip-gram, CBOW and GloVe.
对于基线系统,我们考虑了传统的 Skip-Gram, CBOW 和 GloVe 三种词语表示学习模型。
For Skip-Gram and CBOW, we directly use the code released by Google (Mikolov et al., 2013).
我们直接使用了 Google (Mikolov et al., 2013) 发布的 Skip-Gram 和 CBOW 的代码。
GloVe is proposed by (Pennington et al., 2014), which seeks the advantages of the WRL models based on statistics and those based on prediction.
GloVe 是由 (Pennington et al., 2014) 提出的,它寻求基于统计的词语表示学习模型和基于预测的词语表示学习模型的优势。
Moreover, we propose another model, Maximum Selection over Target Model (MST), for further comparison inspired by (Chen et al., 2014).
此外,在 (Chen et al., 2014) 的激发下,我们提出另一个模型——基于目标的最大选择模型(MST)——来进一步比较。
It represents the current word embeddings with only the most probable sense according to the contexts, instead of viewing a word as a particular distribution over all its senses similar to that of SAT.
它代表的是当前词的词嵌入只与上下文中最可能的语义相关,而不是把一个词看作在它所有的语义上的一个具体的分布,比如 SAT。
For a fair comparison, we train these models with the same experimental settings and with their best parameters.
为了达成一个公平的比较,我们使用相同的实验设置和各模型的最佳参数来训练这些模型。
As for the parameter settings, we set the context window size as the upper bound, and during training, the window size is dynamically selected ranging from 1 to 8 randomly.
在参数设置方面,我们设置上下文窗口大小的上界为 = 8,然后在训练期间,窗口大小是自动地在 1 至 8 之间动态地调节。
We set the dimensions of word, sense and sememe embeddings to be the same 200.
我们把词语、语义和义原的嵌入维度都设置为 200。
For learning rate , its initial value is 0.025 and will descend through iterations.
初始学习率设置为 0.025 ,在迭代期间会自动下降。
We set the number of negative samples to be 25.
负采样数值设置为 25。
We also set a lower bound of word frequency as 50, and in the training set, those words less frequent than this bound will be filtered out.
我们也设置了词频的下界为 50,在训练期间,词频低于下界的词将会被滤掉。
For SAT, we set = 2.
对于 SAT, 我们设置 = 2 。
4.3 词语相似度 Word Similarity
The task of word similarity aims to evaluate the quality of word representations by comparing the similarity ranks of word pairs computed by WRL models with the ranks given by dataset.
词语相似度任务,旨在通过比较在给定的数据集上,通过词语表示学习模型计算出的词对相似度排名来衡量词语表示的质量。
WRL models typically compute word similarities according to their distances in the semantic space.
通常,词语表示学习模型在语义空间中,根据词语的距离来计算词语相似度。
4.3.1 评测草案 Evaluation Protocol
In experiments, we choose the cosine similarity between two word embeddings to rank word pairs.
在实验当中,我们选取余弦距离来度量两个词嵌入之间的距离,然后对词对进行排序。
For evaluation, we compute the Spearman correlation between the ranks of models and the ranks of human judgments.
在评测中,我们在模型排序和人工排序中计算斯皮尔曼相关度(Spearman correlation)。
| Model | Wordsim-240 | Wordsim-297 |
|---|---|---|
| CBOW | 57.7 | 61.1 |
| GloVe | 59.8 | 58.7 |
| Skip-Gram | 58.5 | 63.3 |
| SSA | 58.9 | 64.0 |
| MST | 59.2 | 62.8 |
| SAC | 59.1 | 61.0 |
| SAT | 61.2 | 63.3 |
表一:词语相似度计算的评价结果。
4.3.2 实验结论 Experiment Results
Table 1 shows the results of these models for word similarity computation.
表一展示了以上模型在词语相似度计算上的结果。
From the results we can observe that:
从以上结果中,我们可以观察到:
(1) Our models outperform all baselines on both two test sets.
(1)我们的模型在两个测试集上的表现明显好于所有的基线系统。
This indicates that, by utilizing sememe annotation properly, our model can better capture the semantic relations of words, and learn more accurate word embeddings.
这表明:通过适当地运用义原标注,我们的模型可以更好地捕捉词语之间的语义关系,并且学习更准确的词嵌入。
(2) The SSA model represents a word with the average of its sememe embeddings.
(2)SSA模型用每个词语的义原平均嵌入来表示这个词。
In general, SSA model performs slightly better than baselines, which tentatively proves that sememe information is helpful.
大体上,SSA 模型表现稍好于基线系统,这试初步证明了义原信息是有帮助的。
The reason is that words which share common sememe embeddings will benefit from each other.
原因是词语之间通过共享义原嵌入而相互受益。
Especially, those words with lower frequency, which cannot be learned sufficiently using conventional WRL models, in contrast, can obtain better word embeddings from SSA simply because their sememe embeddings can be trained sufficiently through other words.
特别地,低频词无法通过传统的词语表示学习模型来获得有效的训练。但与之相反的是,SSA 模型可以使低频词获得较好的嵌入,仅仅是因为低频词的义原可以通过其他单词而得到充分的训练。
(3) The SAT model performs better than baselines and SAC, especially on Wordsim-240.
(3)SAT 模型比 SAC 具有更好的表现,尤其是在 Wordsim-240 数据集上。
This indicates that SAT can obtain more precise sense distribution of a word.
这表明 SAT 可以习得更准确的词语语义分布。
The reason has been mentioned above that, different from SAC using only one target word as attention for WSD, SAT adopts richer contextual information as attention for WSD.
其原因已经在上面提到过了,不同于 SAC 在词语消歧上只使用一个目标词作为注意力,SAT 在词语消歧上选取了更丰富的上下文信息作为注意力。
(4) SAT works better than MST, and we can conclude that a soft disambiguation over senses prevents inevitable errors when selecting only one most-probable sense.
(4) SAT 比 MST 表现更好,并且我们可以得出结论:一个在语义上的软消歧(soft disambiguation)阻止了当选择只有一个最可能的语义时必然发生的错误。
The result makes sense because, for many words, their various senses are not always entirely different from each other, but share some common elements.
结果很有意义,对于很多词来说,因为它们各种各样的语义并不是总完全地与其他不同,而是共享了相同的元素。
In some contexts, a single sense may not convey the exact meaning of this word.
在相同的上下文中,一个单独的语义可能不会准确地表达该词的词义。
4.4 词语类推 Word Analogy
Word analogy inference is another widely-used task to evaluate the quality of WRL models (Mikolov et al., 2013).
词语类比推理是另一个广泛被使用的,用来评价模型词语表示学习质量的任务 (Mikolov et al., 2013) 。
4.4.1 评测草案 Evaluation Protocol
The dataset proposed by (Chen et al., 2015) consists of 1, 124 analogies, which contains three analogy types: (1) capitals of countries (Capital), 677 groups; (2) states/provinces of cities (City), 175 groups; (3) family words (Relationship), 272 groups.
该数据集由 (Chen et al., 2015) 提出,由 1,124 个类比实体组成(analogy),其包括 3 种实体类型:(1)677 组国家的首都;(2) 175 组城市的州或省份;(3)272 组家庭(关系)词。
Given an analogy group of words , WRL models usually get equal to .
给出类比词组 ,词语表示学习模型通常会给出 等于 。
Hence for word analogy inference, we suppose is missing, and WRL models will rank all candidate words according to their scores as follows:
and select the top-ranked word as the answer
因此对于词语类比推理,我们假设 不存在,然后词语表示学习模型会给出所有候选词的得分:
进行排序,,并选取排在前几个的词语作为答案。
For word analogy inference, we consider two evaluation metrics: (1) Accuracy.
在词语类比推理上,我们考虑两个主要的指标 (1) 准确率。
For each analogy group, a WRL model selects the top-ranked word , which is judged as positive if .
对于每一组类比,一个词语表示学习模型选取 排在前面的词语, 如果 则判断为阳性。
The percentage of positive samples is regarded as the accuracy score for this WRL model.
正确例子的百分比被视为词语表示学习模型的准确率打分。
(2) Mean Rank.
(2)平均排名。
For each analogy group, a WRL model will assign a rank for the gold standard word w4 according to the scores computed by Eq. (10).
对于每一组类比,一个词语表示学习模型将会根据公式(10)计算出的打分,给词 一个正确等级的排名。
We use the mean rank of all gold standard words as the evaluation metric.
我们使用所有正确标准词的平均等级作为评估度量。
4.4.2 实验结果 Experiment Results
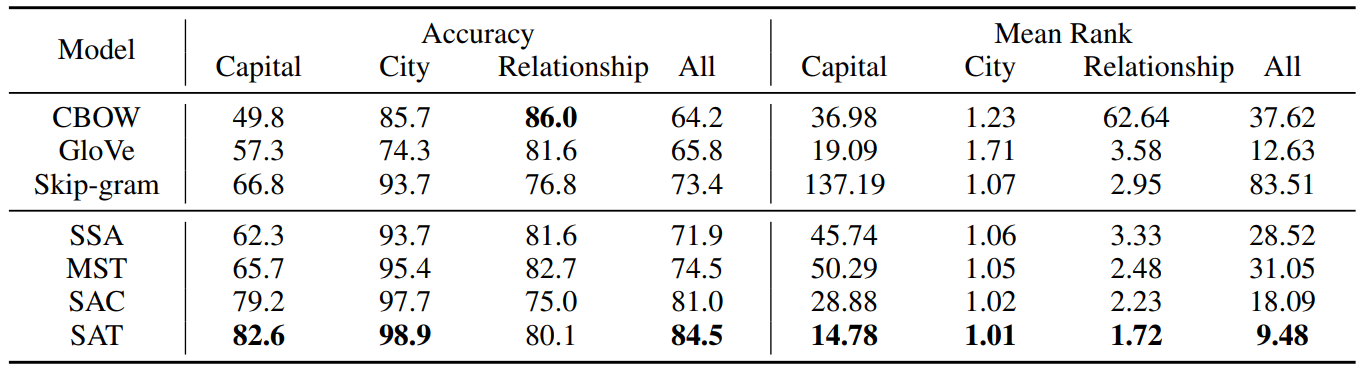
Table 2 shows the evaluation results of these models for word analogy inference.
表二给出了三个模型在词语类比推理上的评测结果。
From the table, we can observe that:
从上表可知:
(1) The SAT model performs best among all models, and the superiority is more significant than that on word similarity computation.
(1)SAT 模型在所有模型中的表现是最好的,相比于词语相似计算具有更突出的优势。
This indicates that SAT will enhance the modeling of implicit relations between word embeddings in the semantic space.
这表明 SAT 将会加强语义空间中词嵌入间隐式关系的建模。
The reason is that sememes annotated to word senses have encoded these word relations.
原因是注释到单词语义的义原编码了这些单词的关系。
For example, capital and Cuba are two sememes of the word “Havana”, which provide explicit semantic relations between the words “Cuba” and “Havana”.
例如,“首都”和“古巴”是词语“哈瓦那”的两个义原,这就为"古巴"和“哈瓦那”之间提供了明确的语义关系。
(2) The SAT model does well on both classes of Capital and City, because some words in these classes have low frequencies, while their sememes occur so many times that sememe embeddings can be learned sufficiently.
(2)SAT 模型在首都和城市两类上的表现都很好,这是因为这些类中一些词的词频不高,但是它们蕴含的义原却出现了很多次,那些义原嵌入可以得到有效的学习。
With these sememe embeddings, these low-frequent words can be learned more efficiently by SAT.
在那些义原嵌入的帮助下,这些低频词可以被 SAT 有效的学习。
(3) It seems that CBOW works better than SAT on Relationship class.
结果表明, CBOW 似乎在关系类上比 SAT 表现的更好。
Whereas for the mean rank, CBOW gets the worst results, which indicates the performance of CBOW is unstable.
然而 CBOW 在平均排序上得到了不尽如人意的结果,这表明 CBOW 的表现是不稳定的。
On the contrary, although the accuracy of SAT is a bit lower than that of CBOW, SAT seldom gives an outrageous prediction.
与之相反,尽管 SAT 的准确率只比 CBOW 低了一点,但是 SAT 很少给出差强人意的预测。
In most wrong cases, SAT predicts the word “grandfather” instead of “grandmother”, which is not completely nonsense, because in HowNet the words “grandmother”, “grandfather”, “grandma” and some other similar words share four common sememes while only one sememe of them are different.
在大多数的错误的例子中,SAT 应该预测出 “祖父” 而不是 “祖母”,但这并不是完全没有道理的,因为知网中 "祖母"、“祖父” 和其他相似的词语共享着四个共同的义原,只有一个义原不同。
These similar sememes make the attention process less discriminative with each other.
这些相似的义原削弱了注意力过程在这些词之间的判别能力。
But for the wrong cases of CBOW, we find that many mistakes are about words with low frequencies, such as “stepdaughter” which occurs merely for 358 times.
但是对于 CBOW 的错误例子,我们发现很多的错误是关于低频词的,例如仅仅出现了 358 次的“继女”一词。
Considering sememes may relieve this problem.
考虑义原的话,可能会缓解这个问题。
4.5 个例研究 Case study
The above experiments verify the effectiveness of our models for WRL.
以上的实验验证了我们词语表示学习模型的有效性。
Here we show some examples of sememes, senses and words for case study.
下面我们为个例研究展示一些义原、语义和词语。
4.5.1 Word Sense Disambiguation
To demonstrate the validity of Sememe Attention, we select three attention results in training set, as shown in Table 3.
为了证明语义注意力的正确性,我们选取训练集中三个注意力结果,在表三中展示。
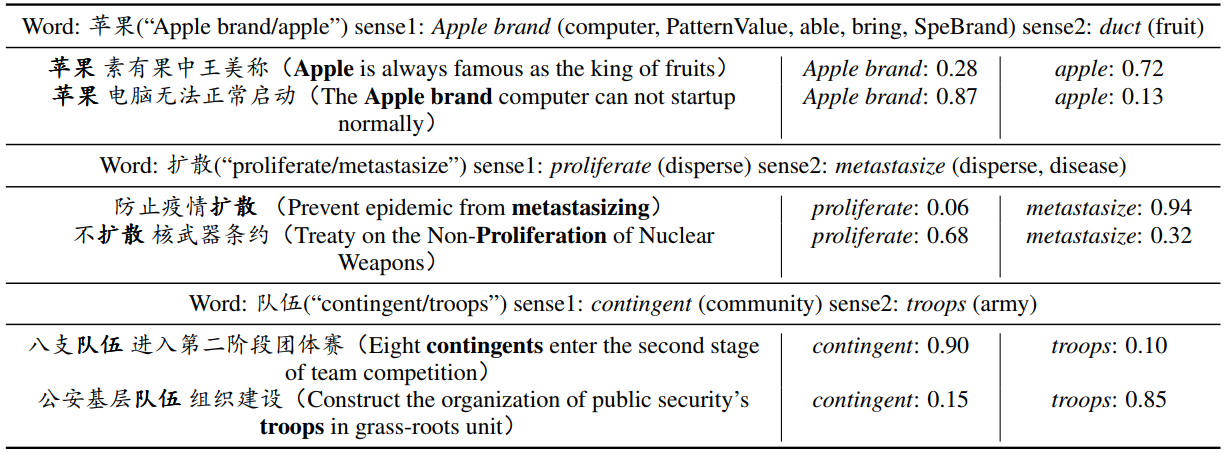
In this table, the first rows of three examples are word-sense-sememe structures of each word.
本表中,第一行是的三个例子中每个词的词语-语义-义原结构。
For instance, in the third example, the word has two senses, contingent and troops; contingent has one sememe community, while troops has one sememe army.
拿第三个例子来说,该词具有两个语义“代表队”和“军队”;代表队有一个义原——共同体,军队有一个义原——军队。
The three examples all indicate that our models can estimate appropriate distributions of senses for a word given a context.
三个例子都表明:对于一个给定上下文的词,我们的模型可以估计出适当的语义分布。
4.5.2 上下文词语对注意力的影响 Effect of Context Words for Attention
We demonstrate the effect of context words for attention in Table. 4.
我们在表四中证明了上下文词语对注意力的影响。

The word “Havana” consists of four sememes, among which two sememes capital and Cuba describe distinct attributes of the word from different aspects.
“哈瓦那”由四个义原组成,其中的两个义原“首都”和“古巴”从不同角度描述了该词有区别的属性。
Here, we list three different context words “Cuba”, “Russia” and “cigar”.
这里,我们列出三个不同的上下文单词——“古巴”、“俄罗斯“和”雪茄“。
Given the context word “Cuba”, both sememes get high weights, indicating their contributions to the meaning of “Havana” in this context.
给定上下文 ”古巴“,两个义原都得到了较高的权重,这表明它们在这个上下文中对 ”哈瓦那“ 一词有意义上的贡献。
The context word “Russia” is more relevant to the sememe capital.
上下文 ”俄罗斯“ 与首都这个义原更有关联。
When the context word is “cigar”, the sememe Cuba has more influence, because cigar is a famous specialty of Cuba.
当上下文是 ”雪茄“ 的时候,义原古巴给予了更多的影响,因为雪茄是古巴著名的特产。
From these examples, we can conclude that our Sememe Attention can accurately capture the word meanings in complicated contexts.
从上例中我们可以总结出:我们的义原注意力可以准确地捕获复杂上下文中词语的语义。
5 结论和未来的工作
In this paper, we propose a novel method to model sememe information for learning better word representations.
在本文中,为了更好地学习词语表示,我们提出了新奇的建模义原信息的方法。
Specifically, we utilize sememe information to represent various senses of each word and propose Sememe Attention to select appropriate senses in contexts automatically.
特别地,我们利用义原信息来表示每一个词各种各样的语义,并提出了可以自动地在上下文中选取合适的语义的义原注意力。
We evaluate our models on word similarity and word analogy, and results show the advantages of our Sememe-Encoded WRL models.
我们在词语相似度任务和词语类比任务上评价我们的模型,而且结果表明了:我们的义原-编码词表示学习模型的优势。
We also analyze several cases in WSD and WRL, which confirms our models are capable of selecting appropriate word senses with the favor of sememe attention.
我们也分析了词语消歧和词表示学习中的一些案例,这证实了我们的模型在义原注意力的帮助下,有能力选择合适的词语语义。
We will explore the following research directions in future: (1) The sememe information in HowNet is annotated with hierarchical structure and relations, which have not been considered in our framework.
我们会在将来的工作中探索接下来的几个方向:(1)知网中的义原信息是有层级结构和关系的,在我们的模型中并没有考虑这些。
We will explore to utilize these annotations for better WRL.
为了更好地词语表示学习,我们将会利用这些标注。
(2) We believe the idea of sememes is universal and could be wellfunctioned beyond languages.
(2)我么相信义原的想法是通用的,并且可以在语言之外发挥作用。
we will explore the effectiveness of sememe information for WRL in other languages.
我们将探讨词语表示学习中的义原信息,在其他语言中的有效性。
感悟
我目前的英文阅读能力太弱,仅阅读一遍的话,连论文的细节都掌握不了。因为这次是全文翻译了一遍,我猛然发现我第一遍读的时候,居然好多细节都没领悟到,甚至还有领悟错的地方。太可怕了。
综上,我以后每读一篇论文,都要力求把它全文翻译!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
2017-07-25 How to Conduct High-Impact Research and Produce High-Quality Papers