

系统设计与实践(实战演练)
Design TinyURL
把用户提供的 URL 转换成“短 URL ”返回。当用户访问短 URL 时,再重定向至原始的 URL。
系统设计题的评判标准
| 打分 | 对求职者的评价 | 标准 |
| 1.0 | 差 | 对需求缺乏了解,对系统的问题范围缺乏定义 |
| 2.0 | 不及格 | 知识匮乏,设计理念一般 |
| 3.0 | 好 | 合理的解决方案,解释地也很清晰 |
| 4.0 | 非常好 | 超出预期地好,系统的设计、优缺点的取舍都经过了深思熟虑。 |
Level 1.0
#设计一个把完整 URL 编码或者压缩成5个字符的体系。
#使用单个数据库来存储从完整 URL 到原始 URL 的映射。
#重写短 URL 的规则:如果映射关系存在,就返回短 URL ,否则返回 null 。

Level 1.5
1. 字符长度不足 5 个字符怎么办?用 0 填充。例如:
t.cn/00001
t.cn/00002
t.cn/00003
t.cn/00004
t.cn/00005
2. 流程解析: 访问时 URL -> ID of DB -> Short URL (返回) 重定向 ShtorURL -> ID of DB -> URL
3. level 1.0 版本的短 URL 取值范围 0 ~ 99999 。level 1.5 版本的取值空间 64 ^ 5 (A~Z a ~ z 0~9 _ -)——这就是 base 64 编码。 64 ^ 5 = 2 ^ 30 = 1 GB
4. Cache : 读写次数比例没有被考虑到、Cache 的缓存淘汰算法 LRU(最近最少使用算法) 还是 LFU(最近最不常用页面置换算法)
Level 1.0 和 Level 1.5 的缺点:
1. 性能:当qps(query per second 每秒查询次数)很高,比如达到 1000 QPS 时,系统能否支撑得住?
2. 可拓展性和稳定性:该设计没有考虑到系统的拓展性和稳定性。单个DB能否支撑住?采用那一种 DB 没有指明NoSQL DB / SQL DB。如果 DB 失效时系统该怎么办?
Level 2.0 性能
1. key-value DB
#单个 mysql 会比较慢(比如 10,000 qps会使其达到极限)
#key-value 数据库由于剔除了“事物”等类型的操作,所以性能会达到 mysql 的10倍以上(例如 100,000 qps)
2. 将映射功能交由其他方式实现
#URL -> md5(128bits)
#Base64 -> 6bits , 128 / 6 ~ 21 chars > 5 chars
# truncate( md5( URL ), 5 )——截取前5位——如何解决碰撞?
Level 3.0 可拓展性 和 可靠性
1. 对 memcache 和 DB 采用多台服务器产生多个节点。(只用一台服务器时会产生一个单点,导致可靠性非常低)
#切分:hash(URL) % 节点数 = server ID
#standby:2-8法则,对经常被访问的机器做热备份,当该 server 被访问时,将请求继续重定向——到备份的机器上,进一步地分担流量。
2. 可用性
#多做备份(主从分离——经典的分布式方案)
#数据恢复
master :记录操作日志,记录 checkpoint 。当需要恢复时,先找到最近的 checkpoint ,然后恢复之。
slave :直接拷贝其他slave。
#一致性(最终一致性、强一致性)
Level 4.0 super star
1. 对 ID 的分配值进行泛化:使用 ID generator,比如开源软件 ZooKeeper。
2. 避免 URL 被重复访问或者“爬取”?打乱字符串,在内部建立字符串映射表——“凯撒编码”。
3. 如何限制单个用户的访问次数?流量控制?
4. 如何实现重定向 server ?采用 Apache redirect module。
Rate Limit
Question: 当用户请求频率超过 10次 / min 或者 100 / hour 或者 1000 / day 时阻止其请求。
比较直观的做法:
采用 memcache :key 可以采用 注册的IP / Username / 注册时的Email / userID
memcache 中的 real key :key + timestamp(in minute)
value:次数
expireation:/m /h /d
Memcache 介绍
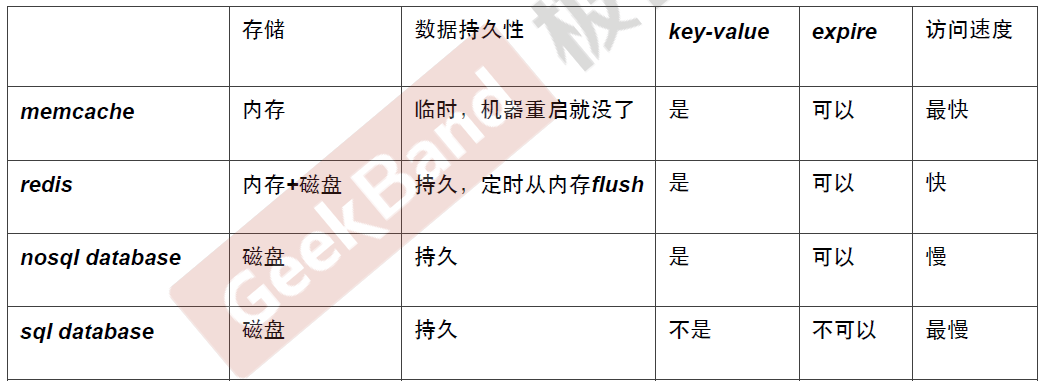
Rate Limit Level 0
已输入密码登陆为例,要求用户不能在1小时之内登陆出错超过5次。内存里放一个HashMap,存谁在哪个时间做了某件被限制的事情。然后……然后……解不了……无法查询某个用户在10分钟之内到底是否
Rate limit level 1
使用Cache, 带上expire信息,设置1小时之后自动销毁。key = event_name + user_id,如 ”login100”,代表记录了 login100 在最近的登陆出错总次数。
一旦用户登陆出错,在 cache 中找到这个计数器,然后 +1,并延长销毁时间为一小时之后。
如果发现计数器超过了5,就出错。
缺点:算法有一定正确性的问题。不能完全保证是一小时以内超过5次,会 block 掉一些正常的访问:如: 12:00 登陆出错(计数器=1),12:59 登陆出错(计数器=2),13:58 登陆出错(计数器=3),14:57登陆出错(计数器=4),15:56登陆出错(计数器=5),然后被block。。。但按照之前的规定,1小时之内其实没有超过5次。
Rate limit 2
每分钟为一个 bucket(因为一般不会出现以秒为单位的block,如果要以秒为单位的话,就每秒钟一个 bucket)
使用Cache,key = timestamp + event + user_id/username
如:”1400_login_username”
value 是 count。
expire 设为2小时。
在用户登陆出错之后。记录这个 key 到 memcache 里。并以当前时间为 key 往前数 1-60 分钟,在 memcache 中查询对应的时间上该用户是否有登陆失败的记录。如果有,统计一共登陆失败多少次,超过5次,就告诉系统这个用户需要 block。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)