
k8s-单节点升级为集群(高可用)
单master节点升级为高可用集群
对于生产环境来说,单节点master风险太大了。 非常有必要做一个高可用的集群,这里的高可用主要是针对控制面板来说的,比如 kube-apiserver、etcd、kube-comtroller-manager、kube-scheduler 这几个组件,其中 kube-controller-manager 与 kube-scheduler 组件是 kubernetes 集群自己去实现的高可用,apiserver 和 etcd 就需要手动去搭建高可集群了。 高可用的架构有很多,比如典型的 haproxy+keepalived架构,或者使用 nginx来做代理实现。我们这里为了声明如何将单 master 升级为高可用的集群,采用相对就更简单的 nginx 模式,当然这种模式也有一些缺点,但是足以说明高可用的实现方式了。

从上图可以看出,我们需要在所有控制节点上安装 nginx、keepalived服务。 来代理 apiserver,这里我准备了2个节点作为控制平面节点: k8s-master1、k8s-master2, 这里我默认所有节点都已经正常安装配置好了docker, 以及节点初始化操作。
在所有节点 hosts配置文件中添加如下内容:
$ cat /etc/hosts 127.0.0.1 api.k8s.local 192.168.166.128 k8s-master1 192.168.166.129 k8s-master2 192.168.166.130 k8s-node1 192.168.166.131 k8s-node2
1、更新证书
由于我们需要将集群替换成高可用的集群,那么势必会想到我们会用一个负载均衡器来代理 APIServer, 也就是这个负载均衡器访问 APIServer 的时候需要能正常访问,所以默认安装的 APIServer 证书就需要更新,因为里面没有包含我们需要的地址,需要保证在 SAN 列表中包含一些额外的名称。
首先我们一个 kubeadn 的配置文件,如果一开始安装集群的时候你就是使用的配置文件,那么我们可以直接更新这个配置文件,但是我们你没有使用这个配置文件,直接使用 kubeadm init 来安装的集群,那么我们可以从集群中获取 kubeadm 的配置信息来插件一个配置文件,因为 kubeadm 会将其配置写入到 kube-system 命名空间下面的名为 kubeadm-config 的 ConfigMap 中。可以直接执行如下所示的命令将该配置导出:会生成一个 kubeadm.yam的配置文件
$ kubectl -n kube-system get configmap kubeadm-config -o jsonpath='{.data.ClusterConfiguration}' > kubeadm.yaml
生成的kubeadm.yaml 文件中并没有列出额外的 SAN 信息,我们需要添加一个新的数据,需要在 apiserver 属性下面添加一个 certsSANs 的列表。如果你在启动集群的时候就使用的 kubeadm 的配置文件,可能就已经包含 certsSANs 列表了,如果没有我们就需要添加它,比如我们这里要添加一个新的域名 api.k8s,local 以及 k8s-master 和 k8s-master2 这两个主机名和IP地址 192.168,.166.128、192.168.166.129、192.168.168.100。可以添加多个IP,192.168.166.100为虚拟VIP,那么我们需要在 apiServer 下面添加如下的所示的数据:
apiServer: certSANs: - api.k8s.local - k8s-master1 - k8s-master2 - 192.168.166.128 - 192.168.166.129 - 192.168.166.100 extraArgs: authorization-mode: Node,RBAC timeoutForControlPlane: 4m0s apiVersion: kubeadm.k8s.io/v1beta2 certificatesDir: /etc/kubernetes/pki clusterName: kubernetes controllerManager: {} dns: type: CoreDNS etcd: local: dataDir: /var/lib/etcd imageRepository: registry.aliyuncs.com/k8sxio kind: ClusterConfiguration kubernetesVersion: v1.17.11 networking: dnsDomain: cluster.local podSubnet: 10.244.0.0/16 serviceSubnet: 10.96.0.0/12 scheduler: {}
上面我只列出了 apiServer 下面新增的 certSANs 信息,这些信息是包括在标准的 SAN 列表之外的,所以不用担心这里没有添加 kubernetes、kubernetes.default 等等这些信息,因为这些都是标准的 SAN 列表中的。
更新完 kubeadm 配置文件后我们就可以更新证书了,首先我们移动现有的 APIServer 的证书和密钥,因为 kubeadm 检测到他们已经存在于指定的位置,它就不会创建新的了。
$ mv /etc/kubernetes/pki/apiserver.{crt,key} ~
然后直接使用 kubeadm 命令生成一个新的证书:
$ kubeadm init phase certs apiserver --config kubeadm.yaml W0902 10:05:28.006627 832 validation.go:28] Cannot validate kubelet config - no validator is available W0902 10:05:28.006754 832 validation.go:28] Cannot validate kube-proxy config - no validator is available [certs] Generating "apiserver" certificate and key [certs] apiserver serving cert is signed for DNS names [ydzs-master kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local api.k8s.local k8s-master1 k8s-master2] and IPs [10.96.0.1 192.168.166.128 192.168.166.129 192.168.166.100]
通过上面的命令可以查看到 APIServer 签名的 DNS 和 IP 地址信息,一定要和自己的目标签名信息进行对比,如果缺失了数据就需要在上面的 certSANs 中补齐,重新生成证书。
该命令会使用上面指定的 kubeadm 配置文件为 APIServer 生成一个新的证书和密钥,由于指定的配置文件中包含了 certSANs 列表,那么 kubeadm 会在创建新证书的时候自动添加这些 SANs。
最后一步是重启 APIServer 来接收新的证书,最简单的方法是直接杀死 APIServer 的容器:
$ docker ps | grep kube-apiserver | grep -v pause 7fe227a5dd3c aa63290ccd50 "kube-apiserver --ad…" 14 hours ago Up 14 hours k8s_kube-apiserver_kube-apiserver-ydzs-master_kube-system_6aa38ee2d66b7d9b6660a88700d00581_0 $ docker kill 7fe227a5dd3c 7fe227a5dd3c
容器被杀掉后,kubelet 会自动重启容器,然后容器将接收新的证书,一旦 APIServer 重启后,我们就可以使用新添加的 IP 地址或者主机名来连接它了,比如我们新添加的 api.k8s.local。
验证证书
要验证证书是否更新我们可以直接去编辑 kubeconfig 文件中的 APIServer 地址,将其更换为新添加的 IP 地址或者主机名,然后去使用 kubectl 操作集群,查看是否可以正常工作。
当然我们可以使用 openssl 命令去查看生成的证书信息是否包含我们新添加的 SAN 列表数据:
$ openssl x509 -in /etc/kubernetes/pki/apiserver.crt -text Certificate: ...... Subject: CN=kube-apiserver ...... X509v3 Subject Alternative Name: DNS:ydzs-master, DNS:kubernetes, DNS:kubernetes.default, DNS:kubernetes.default.svc, DNS:kubernetes.default.svc.cluster.local, DNS:api.k8s.local, DNS:k8s-master1, DNS:k8s-master2, IP Address:10.96.0.1, IP Address:192.168.166.128 IP Address:192.168.166.129, IP Address:192.168.166.100 ......
如果上面的操作都一切顺利,最后一步是将上面的集群配置信息保存到集群的 kubeadm-config 这个 ConfigMap 中去,这一点非常重要,这样以后当我们使用 kubeadm 来操作集群的时候,相关的数据不会丢失,比如升级的时候还是会带上 certSANs 中的数据进行签名的。
$ kubeadm config upload from-file --config kubeadm.yaml
# 如果上面命令报错,可以直接编辑修改 添加需要的内容即可
$ kubectl -n kube-system edit configmap kubeadm-config
使用上面的命令保存配置后,我们同样可以用下面的命令来验证是否保存成功了:
$ kubectl -n kube-system get configmap kubeadm-config -o yaml
更新 APIServer 证书的名称在很多场景下都会使用到,比如在控制平面前面添加一个负载均衡器,或者添加新的 DNS 名称或 IP 地址来使用控制平面的端点,所以掌握更新集群证书的方法也是非常有必要的。
2、部署 nginx + keepalived 高可用负载均衡器
Kubernetes作为容器集群系统,通过健康检查+重启策略实现了Pod故障自我修复能力,通过调度算法实现将Pod分布式部署,并保持预期副本数,根据Node失效状态自动在其他Node拉起Pod,实现了应用层的高可用性。
针对Kubernetes集群,高可用性还应包含以下两个层面的考虑:Etcd数据库的高可用性和Kubernetes Master组件的高可用性。 而kubeadm搭建的K8s集群,Etcd只起了一个,存在单点,所以我们这里会独立搭建一个Etcd集群。
Master节点扮演着总控中心的角色,通过不断与工作节点上的Kubelet和kube-proxy进行通信来维护整个集群的健康工作状态。如果Master节点故障,将无法使用kubectl工具或者API做任何集群管理。
Master节点主要有三个服务kube-apiserver、kube-controller-manager和kube-scheduler,其中kube-controller-manager和kube-scheduler组件自身通过选择机制已经实现了高可用,所以Master高可用主要针对kube-apiserver组件,而该组件是以HTTP API提供服务,因此对他高可用与Web服务器类似,增加负载均衡器对其负载均衡即可,并且可水平扩容。
kube-apiserver高可用架构图:
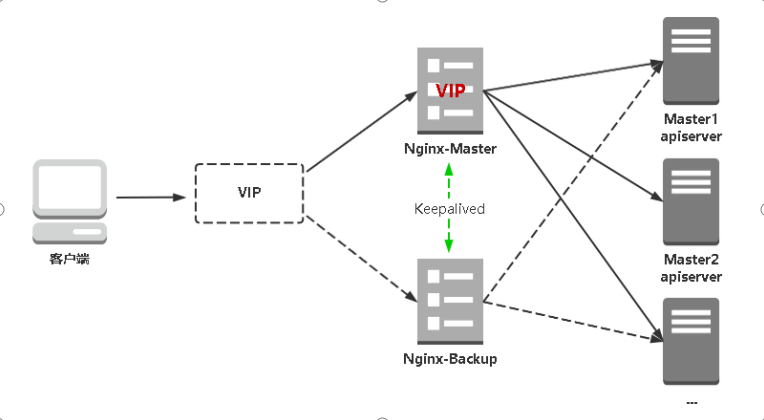
- Nginx是一个主流Web服务和反向代理服务器,这里用四层实现对apiserver实现负载均衡。
- Keepalived是一个主流高可用软件,基于VIP绑定实现服务器双机热备,在上述拓扑中,Keepalived主要根据Nginx运行状态判断是否需要故障转移(偏移VIP),例如当Nginx主节点挂掉,VIP会自动绑定在Nginx备节点,从而保证VIP一直可用,实现Nginx高可用。
注:为了节省机器,这里与K8s master节点机器复用。也可以独立于k8s集群之外部署,只要nginx与apiserver能通信就行。
2.1 安装软件包(主/备)
yum install epel-release -y
yum install nginx keepalived -y
2.2 Nginx配置文件(主/备一样)
cat > /etc/nginx/nginx.conf << "EOF" user nginx; worker_processes auto; error_log /var/log/nginx/error.log; pid /run/nginx.pid; include /usr/share/nginx/modules/*.conf; events { worker_connections 1024; } # 四层负载均衡,为两台Master apiserver组件提供负载均衡 stream { log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent'; access_log /var/log/nginx/k8s-access.log main; upstream k8s-apiserver { server 192.168.166.128:6443; # Master1 APISERVER IP:PORT server 192.168.166.129:6443; # Master2 APISERVER IP:PORT } server { listen 16443; # 由于nginx与master节点复用,这个监听端口不能是6443,否则会冲突 proxy_pass k8s-apiserver; } } http { log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; tcp_nopush on; tcp_nodelay on; keepalive_timeout 65; types_hash_max_size 2048; include /etc/nginx/mime.types; default_type application/octet-stream; server { listen 80 default_server; server_name _; location / { } } } EOF
2.3 keepalived配置文件(Nginx Master)
cat > /etc/keepalived/keepalived.conf << EOF global_defs { notification_email { acassen@firewall.loc failover@firewall.loc sysadmin@firewall.loc } notification_email_from Alexandre.Cassen@firewall.loc smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id NGINX_MASTER } vrrp_script check_nginx { script "/etc/keepalived/check_nginx.sh" } vrrp_instance VI_1 { state MASTER interface ens33 # 修改为实际网卡名 virtual_router_id 51 # VRRP 路由 ID实例,每个实例是唯一的 priority 100 # 优先级,备服务器设置 90 advert_int 1 # 指定VRRP 心跳包通告间隔时间,默认1秒 authentication { auth_type PASS auth_pass 1111 } # 虚拟IP virtual_ipaddress { 192.168.166.100/24 } track_script { check_nginx } } EOF
- vrrp_script:指定检查nginx工作状态脚本(根据nginx状态判断是否故障转移)
- virtual_ipaddress:虚拟IP(VIP)
准备上述配置文件中检查nginx运行状态的脚本:
cat > /etc/keepalived/check_nginx.sh << "EOF" #!/bin/bash count=$(ss -antp |grep 16443 |egrep -cv "grep|$$") if [ "$count" -eq 0 ];then exit 1 else exit 0 fi EOF chmod +x /etc/keepalived/check_nginx.sh
2.4 keepalived配置文件(Nginx Backup)
cat > /etc/keepalived/keepalived.conf << EOF global_defs { notification_email { acassen@firewall.loc failover@firewall.loc sysadmin@firewall.loc } notification_email_from Alexandre.Cassen@firewall.loc smtp_server 127.0.0.1 smtp_connect_timeout 30 router_id NGINX_BACKUP } vrrp_script check_nginx { script "/etc/keepalived/check_nginx.sh" } vrrp_instance VI_1 { state BACKUP interface ens33 virtual_router_id 51 # VRRP 路由 ID实例,每个实例是唯一的 priority 90 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.166.100/24 } track_script { check_nginx } } EOF
准备上述配置文件中检查nginx运行状态的脚本:
cat > /etc/keepalived/check_nginx.sh << "EOF" #!/bin/bash count=$(ss -antp |grep 16443 |egrep -cv "grep|$$") if [ "$count" -eq 0 ];then exit 1 else exit 0 fi EOF chmod +x /etc/keepalived/check_nginx.sh
注:keepalived根据脚本返回状态码(0为工作正常,非0不正常)判断是否故障转移。
2.5 启动并设置开机启动
systemctl daemon-reload
systemctl start nginx
systemctl start keepalived
systemctl enable nginx
systemctl enable keepalived
2.6 查看keepalived工作状态
[root@k8s-master1 install]# ip add |grep ens33 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 inet 192.168.166.128/24 brd 192.168.166.255 scope global noprefixroute ens33 inet 192.168.166.100/24 scope global secondary ens33
可以看到,在ens33网卡绑定了192.168.31.88 虚拟IP,说明工作正常。
2.7 Nginx+Keepalived高可用测试
关闭主节点Nginx,测试VIP是否漂移到备节点服务器。
在Nginx Master执行 pkill nginx
在Nginx Backup,ip addr命令查看已成功绑定VIP。
启动成功后 apiserver 的负载均衡地址就成了 https://192.168.166.100:16443。然后我们将 kubeconfig 文件中的 apiserver 地址替换成负载均衡器的地址。
# 修改 kubelet 配置 $ vi /etc/kubernetes/kubelet.conf ...... server: https://192.168.166.100:16443 name: kubernetes ...... $ systemctl restart kubelet # 修改 controller-manager $ vi /etc/kubernetes/controller-manager.conf ...... server: https://192.168.166.100:16443 name: kubernetes ...... # 重启 $ docker kill $(docker ps | grep kube-controller-manager | \ grep -v pause | cut -d' ' -f1) # 修改 scheduler $ vi /etc/kubernetes/scheduler.conf ...... server: https://192.168.166.100:16443 name: kubernetes ...... # 重启 $ docker kill $(docker ps | grep kube-scheduler | grep -v pause | \ cut -d' ' -f1)
然后更新 kube-proxy
$ kubectl -n kube-system edit cm kube-proxy ...... kubeconfig.conf: |- apiVersion: v1 kind: Config clusters: - cluster: certificate-authority: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt server: https://api.k8s.local:8443 name: default ......
当然还有 kubectl 访问集群的 ~/.kube/config 文件也需要修改。
3、更新控制面板
由于我们现在已经在控制平面的前面添加了一个负载平衡器,因此我们需要使用正确的信息更新此 ConfigMap。(您很快就会将控制平面节点添加到集群中,因此在此ConfigMap中拥有正确的信息很重要。)
首先,使用以下命令从 ConfigMap 中获取当前配置:
$ kubectl -n kube-system get configmap kubeadm-config -o jsonpath='{.data.ClusterConfiguration}' > kubeadm.yaml
# 或者直接编辑添加
$ kubectl -n kube-system edit configmap kubeadm-config
然后在当前配置文件里面里面添加 controlPlaneEndpoint 属性,用于指定控制面板的负载均衡器的地址。
$ vi kubeadm.yaml
apiVersion: v1
data:
ClusterConfiguration: |
apiServer:
certSANs:
- api.k8s.local
- k8s-master1
- k8s-master2
- 192.168.166.128
- 192.168.166.129
- 192.168.166.100
extraArgs:
authorization-mode: Node,RBAC
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: 192.168.166.100:16443 # 添加改配置
controllerManager: {}
......
然后需要在 kube-public 命名空间中更新 cluster-info 这个 ConfigMap,该命名空间包含一个Kubeconfig 文件,该文件的 server: 一行指向单个控制平面节点。只需使用kubectl -n kube-public edit cm cluster-info 更新该 server: 行以指向控制平面的负载均衡器即可。
$ kubectl -n kube-public edit cm cluster-info ...... server: https://192.168.166.100:16443 name: "" ...... $ kubectl cluster-info Kubernetes master is running at https://192.168.166.100:16443 KubeDNS is running at https://api.k8s.local:8443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy KubeDNSUpstream is running at https://api.k8s.local:8443/api/v1/namespaces/kube-system/services/kube-dns-upstream:dns/proxy Metrics-server is running at https://api.k8s.local:8443/api/v1/namespaces/kube-system/services/https:metrics-server:/proxy To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
更新完成就可以看到 cluster-info 的信息变成了负载均衡器的地址了。
添加控制平面
接下来我们来添加额外的控制平面节点,首先使用如下命令来将集群的证书上传到集群中,供其他控制节点使用:
$ kubeadm init phase upload-certs --upload-certs I0903 15:13:24.192467 20533 version.go:251] remote version is much newer: v1.19.0; falling back to: stable-1.17 W0903 15:13:25.739892 20533 validation.go:28] Cannot validate kube-proxy config - no validator is available W0903 15:13:25.739966 20533 validation.go:28] Cannot validate kubelet config - no validator is available [upload-certs] Storing the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace [upload-certs] Using certificate key: e71ef7ede98e49f5f094b150d604c7ad50f125279180a7320b1b14ef3ccc3a34
上面的命令会生成一个新的证书密钥,但是只有2小时有效期。由于我们现有的集群已经运行一段时间了,所以之前的启动 Token 也已经失效了(Token 的默认生存期为24小时),所以我们也需要创建一个新的 Token 来添加新的控制平面节点:
$ kubeadm token create --print-join-command --config kubeadm.yaml W0903 15:29:10.958329 25049 validation.go:28] Cannot validate kube-proxy config - no validator is available W0903 15:29:10.958457 25049 validation.go:28] Cannot validate kubelet config - no validator is available kubeadm join 192.168.166.100:16443 --token f27w7m.adelvl3waw9kqdhp --discovery-token-ca-cert-hash sha256:6917cbf7b0e73ecfef77217e9a27e76ef9270aa379c34af30201abd0f1088c34
上面的命令最后给出的提示是添加 node 节点的命令,我们这里要添加控制平面节点就要使用如下所示的命令:
$ kubeadm join <DNS CNAME of load balancer>:<lb port> \ --token <bootstrap-token> \ --discovery-token-ca-cert-hash sha256:<CA certificate hash> \ --control-plane --certificate-key <certificate-key>
获得了上面的添加命令过后,登录到 ydzs-master2 节点进行相关的操作,在 ydzs-master2 节点上安装软件:
$ yum install -y kubeadm-1.19.0 kubelet-1.19.0 kubectl-1.19.0
要加入控制平面,我们可以先拉取相关镜像:
$ kubeadm config images pull --image-repository registry.aliyuncs.com/k8sxio
然后执行上面生成的 join 命令,将参数替换后如下所示:
$ kubeadm join 192.168.166.100:16443 \ --token f27w7m.adelvl3waw9kqdhp \ --discovery-token-ca-cert-hash sha256:6917cbf7b0e73ecfef77217e9a27e76ef9270aa379c34af30201abd0f1088c34 \ --control-plane --certificate-key e71ef7ede98e49f5f094b150d604c7ad50f125279180a7320b1b14ef3ccc3a34 [preflight] Running pre-flight checks [preflight] Reading configuration from the cluster... [preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml' [preflight] Running pre-flight checks before initializing the new control plane instance [preflight] Pulling images required for setting up a Kubernetes cluster [preflight] This might take a minute or two, depending on the speed of your internet connection [preflight] You can also perform this action in beforehand using 'kubeadm config images pull' [download-certs] Downloading the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace [certs] Using certificateDir folder "/etc/kubernetes/pki" [certs] Generating "apiserver-kubelet-client" certificate and key [certs] Generating "apiserver" certificate and key [certs] apiserver serving cert is signed for DNS names [ydzs-master2 kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local api.k8s.local api.k8s.local ydzs-master2 ydzs-master3] and IPs [10.96.0.1 10.151.30.70 10.151.30.11 10.151.30.70 10.151.30.71] [certs] Generating "front-proxy-client" certificate and key [certs] Generating "etcd/healthcheck-client" certificate and key [certs] Generating "etcd/server" certificate and key [certs] etcd/server serving cert is signed for DNS names [ydzs-master2 localhost] and IPs [10.151.30.70 127.0.0.1 ::1] [certs] Generating "etcd/peer" certificate and key [certs] etcd/peer serving cert is signed for DNS names [ydzs-master2 localhost] and IPs [10.151.30.70 127.0.0.1 ::1] [certs] Generating "apiserver-etcd-client" certificate and key [certs] Valid certificates and keys now exist in "/etc/kubernetes/pki" [certs] Using the existing "sa" key [kubeconfig] Generating kubeconfig files [kubeconfig] Using kubeconfig folder "/etc/kubernetes" [endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address [kubeconfig] Writing "admin.conf" kubeconfig file [kubeconfig] Writing "controller-manager.conf" kubeconfig file [kubeconfig] Writing "scheduler.conf" kubeconfig file [control-plane] Using manifest folder "/etc/kubernetes/manifests" [control-plane] Creating static Pod manifest for "kube-apiserver" W0903 15:55:08.444989 4353 manifests.go:214] the default kube-apiserver authorization-mode is "Node,RBAC"; using "Node,RBAC" [control-plane] Creating static Pod manifest for "kube-controller-manager" W0903 15:55:08.457787 4353 manifests.go:214] the default kube-apiserver authorization-mode is "Node,RBAC"; using "Node,RBAC" [control-plane] Creating static Pod manifest for "kube-scheduler" W0903 15:55:08.459829 4353 manifests.go:214] the default kube-apiserver authorization-mode is "Node,RBAC"; using "Node,RBAC" [check-etcd] Checking that the etcd cluster is healthy ...... This node has joined the cluster and a new control plane instance was created: * Certificate signing request was sent to apiserver and approval was received. * The Kubelet was informed of the new secure connection details. * Control plane (master) label and taint were applied to the new node. * The Kubernetes control plane instances scaled up. * A new etcd member was added to the local/stacked etcd cluster. To start administering your cluster from this node, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Run 'kubectl get nodes' to see this node join the cluster.
查看etcd
$ cat /etc/kubernetes/manifests/etcd.yaml ...... - --initial-cluster=k8s-master2=https://192.168.166.129:2380,k8s-master1=https://192.168.166.128:2380 - --initial-cluster-state=existing ......
查看集群是否正常:
[root@k8s-master2 ~]# kubectl get node NAME STATUS ROLES AGE VERSION k8s-master1 Ready master 4h29m v1.19.0 k8s-master2 Ready master 3h47m v1.19.0 k8s-node1 Ready <none> 4h15m v1.19.0 k8s-node2 Ready <none> 4h14m v1.19.0
这里我们就可以看到 k8s-master1、k8s-master2 2个节点变成了 master 节点,我们也就完成了将单 master 升级为多 master 的高可用集群了。
最后负载均衡访问测试:
找K8s集群中任意一个节点,使用curl查看K8s版本测试,使用VIP访问:
$ curl -k https://192.168.166.100:16443/version { "major": "1", "minor": "20", "gitVersion": "v1.20.0", "gitCommit": "e87da0bd6e03ec3fea7933c4b5263d151aafd07c", "gitTreeState": "clean", "buildDate": "2021-02-18T16:03:00Z", "goVersion": "go1.15.8", "compiler": "gc", "platform": "linux/amd64" }
可以正确获取到K8s版本信息,说明负载均衡器搭建正常。该请求数据流程:curl -> vip(nginx) -> apiserver
通过查看Nginx日志也可以看到转发apiserver IP:
$ tail /var/log/nginx/k8s-access.log -f 192.168.166.130 192.168.166.129:6443 - [13/Jun/2021:15:06:15 +0800] 200 423 192.168.166.130 192.168.166.128:6443 - [13/Jun/2021:15:06:15 +0800] 200 423 192.168.166.130 192.168.166.128:6443 - [13/Jun/2021:15:06:15 +0800] 200 423 192.168.166.130 192.168.166.129:6443 - [13/Jun/2021:15:06:15 +0800] 200 423 192.168.166.130 192.168.166.129:6443 - [13/Jun/2021:15:06:15 +0800] 200 423


