
hsql整理
一、行转列的使用
1、问题
hive如何将
a b 1
a b 2
a b 3
c d 4
c d 5
c d 6
变为:
a b 1,2,3
c d 4,5,6
2、数据
test.txt
a b 1
a b 2
a b 3
c d 4
c d 5
c d 6
3、答案
1.建表
drop table tmp_jiangzl_test;
create table tmp_jiangzl_test
(
col1 string,
col2 string,
col3 string
)
row format delimited fields terminated by '\t'
stored as textfile;
load data local inpath '/home/jiangzl/shell/test.txt' into table tmp_jiangzl_test;
2.处理
select col1,col2,concat_ws(',',collect_set(col3))
from tmp_jiangzl_test
group by col1,col2;
二、列转行
1、问题
hive如何将
a b 1,2,3
c d 4,5,6
变为:
a b 1
a b 2
a b 3
c d 4
c d 5
c d 6
2、答案
1.建表
drop table tmp_jiangzl_test;
create table tmp_jiangzl_test
(
col1 string,
col2 string,
col3 string
)
row format delimited fields terminated by '\t'
stored as textfile;
处理:
select col1, col2, col5
from tmp_jiangzl_test a
lateral view explode(split(col3,',')) b AS col5
请把下一语句用hive方式实现
SELECT a.key,a.value
FROM a
WHERE a.key not in (SELECT b.key FROM b)
答案:
select a.key,a.value from a where a.key not exists (select b.key from b)
简要描述数据库中的 null,说出null在hive底层如何存储,并解释selecta.* from t1 a left outer join t2 b on a.id=b.id where b.id is null; 语句的含义
null与任何值运算的结果都是null, 可以使用is null、is not null函数指定在其值为null情况下的取值。
null在hive底层默认是用'\N'来存储的,可以通过alter table test SET SERDEPROPERTIES('serialization.null.format' = 'a');来修改。
查询出t1表中与t2表中id相等的所有信息。
写出hive中split、coalesce及collect_list函数的用法(可举例)
Split将字符串转化为数组。
split('a,b,c,d' , ',') ==> ["a","b","c","d"]
COALESCE(T v1, T v2, …) 返回参数中的第一个非空值;如果所有值都为 NULL,那么返回NULL。
collect_list列出该字段所有的值,不去重 select collect_list(id) from table;
写出将 text.txt 文件放入 hive 中 test 表‘2016-10-10’ 分区的语句,test 的分区字段是 l_date。
LOAD DATA LOCAL INPATH '/your/path/test.txt' OVERWRITE INTO TABLE test PARTITION (l_date='2016-10-10')
hive 常用数据清洗函数
1,case when 的利用,清洗诸如评分等的内容,用例如下。
case
when new.comment_grade = '五星商户' then 50
when new.comment_grade = '准五星商户' then 45
when new.comment_grade = '四星商户' then 40
when new.comment_grade = '准四星商户' then 35
when new.comment_grade = '三星商户' then 30
when new.comment_grade = '准三星商户' then 25
when new.comment_grade = '二星商户' then 20
when new.comment_grade = '准二星商户' then 15
when new.comment_grade = '一星商户' then 10
when new.comment_grade = '准一星商户' then 5
when new.comment_grade = '该商户暂无星级' then 0
when new.comment_grade is NULL then old.comment_grade
else new.comment_grade
END as `new.comment_grade`,
-- 使用case when行转列
drop table if exists StudentScores2;
CREATE TABLE StudentScores2
( UserName NVARCHAR(20),
-- 学生姓名 语文 FLOAT,
-- 科目 数学 FLOAT,
-- 科目 英语 FLOAT,
-- 科目 生物 FLOAT -- 科目 );
select UserName,
max(case when subject='语文' then score else 0 end) 语文,
max(case when subject='数学' then score else 0 end) 数学,
max(case when subject='英语' then score else 0 end) 英语,
max(case when subject='生物' then score else 0 end) 生物
from StudentScores group by UserName
列转行

Sql代码
create table TEST_TB_GRADE2
(
ID NUMBER(10) not null,
USER_NAME VARCHAR2(20 CHAR),
CN_SCORE FLOAT,
MATH_SCORE FLOAT,
EN_SCORE FLOAT
)
select user_name, '语文' COURSE , CN_SCORE as SCORE from test_tb_grade2
union select user_name, '数学' COURSE, MATH_SCORE as SCORE from test_tb_grade2
union select user_name, '英语' COURSE, EN_SCORE as SCORE from test_tb_grade2
order by user_name,COURSE 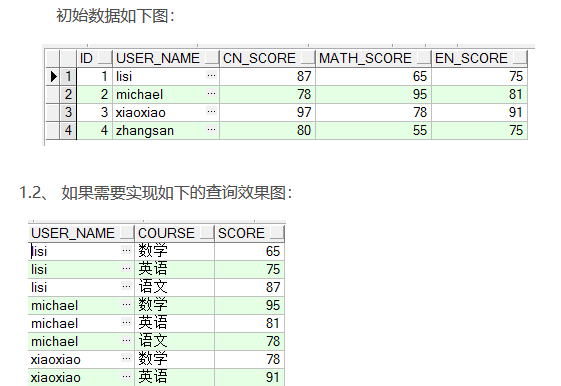
-- 建表 CREATE TABLE StudentScores
( UserName NVARCHAR(20),
-- 学生姓名 Subject NVARCHAR(30),
-- 科目 Score FLOAT -- 成绩 )
-- 使用union all 列转行
select UserName,'语文' subject,语文 score from StudentScores2
union all
select UserName,'数学' subject,数学 score from StudentScores2
union all
select UserName,'英语' subject,英语 score from StudentScores2
union all
select UserName,'生物' subject,生物 score from StudentScores2;
2, 替换字符串中的一些内容。
regexp_replace(new.avg_price, '-', '')
替换 avg_price 中的中划线。
3, 字符串切分函数
split(a.tag_flag, '>')[1],
具体例子:
select split('a,b', ',')[0] ===> 结果 a
4, 字符串拼接函数
SELECT concat('1', '2'); ====》 结果 12
SELECT concat('1', '2', '3'); ===> 结果 123
5, 去除字符串两端空格
trim(a.city)
6, 使用left join 或者 right join 补全数据
例如根据两张表,其中一张表格table2含有省份和城市的信息,
其中一张表table1只有城市信息,需要补全table1 中的省份信息,可以像如下做法:
select
a.name,
b.province,
a.city
from table1 a left join table2 b on a.city = b.city;
7,其他:清除一些不符合条件的数据
可以使用等值判断来处理数据
清除一些不符合条件的数据。
INSERT OVERWRITE table ods.js_beauty_tmp
SELECT *
from ods.js_beauty_tmp
WHERE map_lat != ''
AND map_lng != ''
AND map_lat IS NOT NULL
AND map_lng IS NOT NULL
AND map_lat != 0
AND map_lng != 0
AND map_lat not like '-%'
AND map_lng not like '-%'
and city != '其他城市'
and city != '点评实验室';
hive常用函数
去空格函数:trim
语法: trim(string A)。去除字符串两边的空格
举例:select trim(' abc ') from dual; ##返回值为abc
正则表达式替换函数:regexp_replace
语法: regexp_replace(string A, string B, string C)。将字符串A中的符合java正则表达式B的部分替换为C。
举例:select regexp_replace('foobar', 'oo|ar', '') from dual; ##返回值为fb
正则表达式解析函数:regexp_extract
语法: regexp_extract(string subject, string pattern, int index)。将字符串subject按照pattern正则表达式的规则拆分,返回index指定的字符。
举例:select regexp_extract('foothebar', 'foo(.*?)(bar)', 1) from dual; ##返回值为the
分割字符串函数: split
语法: split(string str, string pat)。按照pat字符串分割str,会返回分割后的字符串数组
举例:select split('abtcdtef','t') from dual; ##返回值为["ab","cd","ef"]
集合查找函数: find_in_set
语法: find_in_set(string str, string strList)。返回str在strlist第一次出现的位置,strlist是用逗号分割的字符串。如果没有找该str字符,则返回0
举例:select find_in_set('ab','ef,ab,de') from dual; ##返回值为2
字符串截取函数:substr,substring
语法: substr(string A, int start),substring(string A, int start)。返回字符串A从start位置到结尾的字符串
举例:select substr('abcde',3) from dual; ##返回值cde
字符串转大写函数:upper,ucase
语法: upper(string A) ucase(string A)。返回字符串A的大写格式
字符串转小写函数:lower,lcase
语法: lower(string A) lcase(string A)。返回字符串A的小写格式
带分隔符字符串连接函数:concat_ws
语法: concat_ws(string SEP, string A, string B…)。返回输入字符串连接后的结果,SEP表示各个字符串间的分隔符
举例:select concat_ws(',','abc','def','gh') from dual; ##返回值为abc,def,gh
lateral view 函数
语法:lateral view udtf()说明:当表中某个字段的取值为列表或数组时,利用该函数和split、explode可以将一行数据拆分成多行数据,在此基础上对拆分之后的数据进行聚合,
用来解决输入一行输出多行(On-to-many maping) 的需求。举例:select deal_id,type,sp from deal_ppt_mark_log t lateral view explode(split(t.sources,','))a as sp
row_number() 和rank()
语法: row_number() over (partition by col_list1 order by col_list2) rank() over(partition by col_list1 order by col_list2)
说明:首先根据col_list1分组,在分组内部根据col_list2排序,row_number()函数计算的值表示每组内部排序后的顺序编号,组内连续的唯一的;rank() over()函数则是跳跃排序,序号不唯一,即当有数据值值相同时,并列,
当遇到不同的数据,其序号为上一个数据的序号加上该序号的个数。如两个并列第一,序列号为(1,1,3.......)。
select id,age,name,sex from (select id,age,name,sex,row_number() over(partition by sex order by age desc) as rank from t_rownumber) tmp where rank<=2;
类型转换函数
日期和浮点型转换
select id,to_date(birthday as date) as bir,cast(salary as float) from t_fun;
时间函数
select cast(current_timestamp as date);
unix时间戳转字符串
select from_unixtime(unix_timestamp(),"yyyy/MM/dd HH:mm:ss");
行转列函数:explode()
select explode(subjects) as sub from t_stu_subject
hive 窗口分析函数
select * from t_access;
使用Hive做数据清洗,经常需要使用正则表达式。
比较讨厌的是,正则表达式匹配失败的时候,hive完全不会报错。
Hive使用regexp,RLIKE需要使用转义字符
原来的写法
SELECT * from ahhs_product_info where product_name NOT RLIKE '([\u4e00-\u9fa5])+' ;
在hive里面的写法
SELECT * from ahhs_product_info where product_name NOT RLIKE '([\\u4e00-\\u9fa5])+' ;
Hive中rlike,like,not like区别与使用详解
like的使用详解
A like B只能使用简单匹配符号 _%,”_”表示任意单个字符,字符”%”表示任意数量的字符
like的匹配是按字符逐一匹配的,使用B从A的第一个字符开始匹配,所以即使有一个字符不同都不行
RLIKE比较符
A RLIKE B ,B中的表达式可以使用JAVA中全部正则表达式,具体正则规则参考java,或者其他标准正则语法
select 1 from t_fin_demo where 'footbar’ rlike '^f.*r$’
转换要求:行转列需保留列名,
方式一:采用union all的形式
select
dt_month
,'valid_num' as type
,sum(valid_num) as num
from temp.temp_xw_rowtocol
group by dt_month
union all
select
dt_month
,'unvalid_num' as type
,sum(unvalid_num) as num
from temp.temp_xw_rowtocol
group by dt_month
方式二:使用lateral view和str_to_map
select
a.dt_month
,add_t.type
,add_t.num
from temp.temp_xw_rowtocol a
lateral view explode(str_to_map(concat('valid_num=',valid_num
,'&unvalid_num=',unvalid_num
),'&','='
)
) add_t as type,num
列转行
通过group by
select
a.dt_month
,sum(case when type = 'valid_num' then num end) as valid_num
,sum(case when type = 'unvalid_num' then num end) as unvalid_num
from temp.temp_xw_coltorow a
group by a.dt_month
一、求单月访问次数和总访问次数
1、数据说明
数据字段说明
用户名,月份,访问次数
数据格式
A,2015-01,5
A,2015-01,15
B,2015-01,5
A,2015-01,8
B,2015-01,25
A,2015-01,5
A,2015-02,4
A,2015-02,6
B,2015-02,10
B,2015-02,5
A,2015-03,16
A,2015-03,22
B,2015-03,23
B,2015-03,10
B,2015-03,1
最后结果展示
用户 月份 最大访问次数 总访问次数 当月访问次数
A 2015-01 33 20 20
A 2015-02 33 43 10
A 2015-03 38 81 38
B 2015-01 30 30 30
B 2015-02 30 45 15
B 2015-03 44 89 44
2、数据准备
(1)创建表
use myhive;
create external table if not exists t_access(
uname string comment ‘用户名’,
umonth string comment ‘月份’,
ucount int comment ‘访问次数’
) comment ‘用户访问表’
row format delimited fields terminated by “,”
location “/hive/t_access”;
(2)导入数据
load data local inpath “/home/hadoop/access.txt” into table t_access;
(3)验证数据
select * from t_access;
3、结果需求
现要求出:
每个用户截止到每月为止的最大单月访问次数和累计到该月的总访问次数
4、需求分析
此结果需要根据用户+月份进行分组
(1)先求出当月访问次数
–求当月访问次数
create table tmp_access(
name string,
mon string,
num int
);
insert into table tmp_access
select uname,umonth,sum(ucount)
from t_access t group by t.uname,t.umonth;
select * from tmp_access;
(2)tmp_access进行自连接视图
create view tmp_view as
select a.name anme,a.mon amon,a.num anum,b.name bname,b.mon bmon,b.num bnum from tmp_access a join tmp_access b
on a.name=b.name;
select * from tmp_view;
(3)进行比较统计
select anme,amon,anum,max(bnum) as max_access,sum(bnum) as sum_access
from tmp_view
where amon>=bmon
group by anme,amon,anum;
二、学生课程成绩
1、说明
use myhive;
CREATE TABLE course (
id int,
sid int ,
course string,
score int
) ;
// 插入数据
// 字段解释:id, 学号, 课程, 成绩
INSERT INTO course VALUES (1, 1, ‘yuwen’, 43);
INSERT INTO course VALUES (2, 1, ‘shuxue’, 55);
INSERT INTO course VALUES (3, 2, ‘yuwen’, 77);
INSERT INTO course VALUES (4, 2, ‘shuxue’, 88);
INSERT INTO course VALUES (5, 3, ‘yuwen’, 98);
INSERT INTO course VALUES (6, 3, ‘shuxue’, 65);
2、需求
求:所有数学课程成绩 大于 语文课程成绩的学生的学号
1、使用case…when…将不同的课程名称转换成不同的列
create view tmp_course_view as
select sid, case course when “shuxue” then score else 0 end as shuxue,
case course when “yuwen” then score else 0 end as yuwen from course;
select * from tmp_course_view;
2、以sid分组合并取各成绩最大值
create view tmp_course_view1 as
select aa.sid, max(aa.shuxue) as shuxue, max(aa.yuwen) as yuwen from tmp_course_view aa group by sid;
select * from tmp_course_view1;
3、比较结果
select * from tmp_course_view1 where shuxue > yuwen;
三、求每一年最大气温的那一天 + 温度
1、说明
数据格式
2010012325
具体数据
2010012325表示在2010年01月23日的气温为25度
2、 需求
比如:2010012325表示在2010年01月23日的气温为25度。现在要求使用hive,计算每一年出现过的最大气温的日期+温度。
要计算出每一年的最大气温。我用
select substr(data,1,4),max(substr(data,9,2)) from table2 group by substr(data,1,4);
出来的是 年份 + 温度 这两列数据例如 2015 99
但是如果我是想select 的是:具体每一年最大气温的那一天 + 温度 。例如 20150109 99
请问该怎么执行hive语句。。
group by 只需要substr(data,1,4),
但是select substr(data,1,8),又不在group by 的范围内。
是我陷入了思维死角。一直想不出所以然。。求大神指点一下。
在select 如果所需要的。不在group by的条件里。这种情况如何去分析?
3、解析
(1)创建一个临时表tmp_weather,将数据切分
create table tmp_weather as
select substr(data,1,4) years,substr(data,5,2) months,substr(data,7,2) days,substr(data,9,2) temp from weather;
select * from tmp_weather;
(2)创建一个临时表tmp_year_weather
create table tmp_year_weather as
select substr(data,1,4) years,max(substr(data,9,2)) max_temp from weather group by substr(data,1,4);
select * from tmp_year_weather;
(3)将2个临时表进行连接查询
select * from tmp_year_weather a join tmp_weather b on a.years=b.years and a.max_temp=b.temp;
四、求学生选课情况
1、数据说明
(1)数据格式
id course
1,a
1,b
1,c
1,e
2,a
2,c
2,d
2,f
3,a
3,b
3,c
3,e
(2)字段含义
表示有id为1,2,3的学生选修了课程a,b,c,d,e,f中其中几门。
2、数据准备
(1)建表t_course
create table t_course(id int,course string)
row format delimited fields terminated by “,”;
(2)导入数据
load data local inpath “/home/hadoop/course/course.txt” into table t_course;
3、需求
编写Hive的HQL语句来实现以下结果:表中的1表示选修,表中的0表示未选修
id a b c d e f
1 1 1 1 0 1 0
2 1 0 1 1 0 1
3 1 1 1 0 1 0
4、解析
第一步:
select collect_set(course) as courses from id_course;
第二步:
set hive.strict.checks.cartesian.product=false;
create table id_courses as select t1.id as id,t1.course as id_courses,t2.course courses
from
( select id as id,collect_set(course) as course from id_course group by id ) t1
join
(select collect_set(course) as course from id_course) t2;
启用严格模式:hive.mapred.mode = strict // Deprecated
hive.strict.checks.large.query = true
该设置会禁用:1. 不指定分页的orderby
2. 对分区表不指定分区进行查询
3. 和数据量无关,只是一个查询模式
hive.strict.checks.type.safety = true
严格类型安全,该属性不允许以下操作:1. bigint和string之间的比较
2. bigint和double之间的比较
hive.strict.checks.cartesian.product = true
该属性不允许笛卡尔积操作
第三步:得出最终结果:
思路:
拿出course字段中的每一个元素在id_courses中进行判断,看是否存在。
select id,
case when array_contains(id_courses, courses[0]) then 1 else 0 end as a,
case when array_contains(id_courses, courses[1]) then 1 else 0 end as b,
case when array_contains(id_courses, courses[2]) then 1 else 0 end as c,
case when array_contains(id_courses, courses[3]) then 1 else 0 end as d,
case when array_contains(id_courses, courses[4]) then 1 else 0 end as e,
case when array_contains(id_courses, courses[5]) then 1 else 0 end as f
from id_courses;
五、求月销售额和总销售额
1、数据说明
(1)数据格式
a,01,150
a,01,200
b,01,1000
b,01,800
c,01,250
c,01,220
b,01,6000
a,02,2000
a,02,3000
b,02,1000
b,02,1500
c,02,350
c,02,280
a,03,350
a,03,250
(2)字段含义
店铺,月份,金额
2、数据准备
(1)创建数据库表t_store
use class;
create table t_store(
name string,
months int,
money int
)
row format delimited fields terminated by “,”;
(2)导入数据
load data local inpath “/home/hadoop/store.txt” into table t_store;
3、需求
编写Hive的HQL语句求出每个店铺的当月销售额和累计到当月的总销售额
4、解析
(1)按照商店名称和月份进行分组统计
create table tmp_store1 as
select name,months,sum(money) as money from t_store group by name,months;
select * from tmp_store1;
(2)对tmp_store1 表里面的数据进行自连接
create table tmp_store2 as
select a.name aname,a.months amonths,a.money amoney,b.name bname,b.months bmonths,b.money bmoney from tmp_store1 a
join tmp_store1 b on a.name=b.name order by aname,amonths;
select * from tmp_store2;
(3)比较统计
select aname,amonths,amoney,sum(bmoney) as total from tmp_store2 where amonths >= bmonths group by aname,amonths,amoney;
Hive sql编写优化总结
Hive是将符合SQL语法的字符串解析生成可以在Hadoop上执行的MapReduce的工具。使用Hive尽量按照分布式计算的一些特点来设计sql,和传统关系型数据库有区别,
所以需要去掉原有关系型数据库下开发的一些固有思维。
基本原则:
1:尽量尽早地过滤数据,减少每个阶段的数据量,对于分区表要加分区,同时只选择需要使用到的字段
select … from A
join B
on A.key = B.key
where A.userid>10
and B.userid<10
and A.dt=‘20120417’
and B.dt=‘20120417’;
应该改写为:
select … from (select … from A
where dt=‘201200417’
and userid>10
) a
join ( select … from B
where dt=‘201200417’
and userid < 10
) b
on a.key = b.key;
2、有小表进行join,可以使用map join
3:尽量原子化操作,尽量避免一个SQL包含复杂逻辑
可以使用中间表来完成复杂的逻辑
4 jion操作 小表要注意放在join的左边,否则会引起磁盘和内存的大量消耗
5:如果union all的部分个数大于2,或者每个union部分数据量大,应该拆成多个insert into 语句,实际测试过程中,执行时间能提升50%
insert overwite table tablename partition (dt= …)
select … from (
select … from A
union all
select … from B
union all
select … from C
) R
where …;
可以改写为:
insert into table tablename partition (dt= …)
select … from A
WHERE …;
insert into table tablename partition (dt= …)
select … from B
WHERE …;
insert into table tablename partition (dt= …)
select … from C
WHERE …;
5:写SQL要先了解数据本身的特点,如果有join ,group操作的话,要注意是否会有数据倾斜
如果出现数据倾斜,应当做如下处理:
set hive.exec.reducers.max=200;
set mapred.reduce.tasks= 200;—增大Reduce个数
set hive.groupby.mapaggr.checkinterval=100000 ;–这个是group的键对应的记录条数超过这个值则会进行分拆,值根据具体数据量设置
set hive.groupby.skewindata=true; --如果是group by过程出现倾斜 应该设置为true
set hive.skewjoin.key=100000; --这个是join的键对应的记录条数超过这个值则会进行分拆,值根据具体数据量设置
set hive.optimize.skewjoin=true;–如果是join 过程出现倾斜 应该设置为true
合理设置reduce个数
reduce个数过少没有真正发挥hadoop并行计算的威力,但reduce个数过多,会造成大量小文件问题,数据量、资源情况只有自己最清楚,找到个折衷点,
2、让服务器尽量少做事情,走最优的路径,以资源消耗最少为目标
比如:
(1) 注意join的使用
若其中有一个表很小使用map join,否则使用普通的reduce join,注意hive会将join前面的表数据装载内存,所以较小的一个表在较大的表之前,减少内存资源的消耗
(2)注意小文件的问题
在hive里有两种比较常见的处理办法
第一是使用Combinefileinputformat,将多个小文件打包作为一个整体的inputsplit,减少map任务数
set mapred.max.split.size=256000000;
set mapred.min.split.size.per.node=256000000
set Mapred.min.split.size.per.rack=256000000
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat
第二是设置hive参数,将额外启动一个MR Job打包小文件
hive.merge.mapredfiles = false 是否合并 Reduce 输出文件,默认为 False
hive.merge.size.per.task = 25610001000 合并文件的大小
(3)注意数据倾斜
在hive里比较常用的处理办法:
Group By
默认情况下,Map阶段同一Key数据分发给一个reduce,当一个key数据过大时就倾斜了。并不是所有的聚合操作都需要在Reduce端完成,很多聚合操作都可以先在Map端进行部分聚合,最后在Reduce端得出最终结果。
开启Map端聚合参数设置
(1)是否在Map端进行聚合,默认为True hive.map.aggr = true
(2)在Map端进行聚合操作的条目数目 hive.groupby.mapaggr.checkinterval = 100000
(3)有数据倾斜的时候进行负载均衡(默认是false) hive.groupby.skewindata = true
Count(Distinct) 去重统计
数据量小的时候无所谓,数据量大的情况下,由于COUNT DISTINCT操作需要用一个Reduce Task来完成,这一个Reduce需要处理的数据量太大,就会导致整个Job很难完成,一般COUNT DISTINCT使用先GROUP BY再COUNT的方式替换
设置5个reduce个数 set mapreduce.job.reduces = 5;
执行去重id查询 select count(distinct id) from bigtable; 调整为 select count(id)from (select id from bigtable groupby id) a;
数据倾斜:
hive在跑数据时经常会出现数据倾斜的情况,使的作业经常reduce完成在99%后一直卡住,最后的1%花了几个小时都没跑完,
这种情况就很可能是数据倾斜的原因,解决方法要根据具体情况来选择具体的方案
大量经验表明数据倾斜的原因是人为的建表疏忽或业务逻辑可以规避的
解决思路:
Hive的执行是分阶段的,map处理数据量的差异取决于上一个stage的reduce输出,所以如何将数据均匀的分配到各个reduce中,就是解决数据倾斜的根本所在
典型的业务场景
场景:如日志中,常会有信息丢失的问题,比如日志中的 user_id,如果取其中的 user_id 和 用户表中的user_id 关联,会碰到数据倾斜的问题
解决方法1: user_id为空的不参与关联
select * from log a
join users b
on a.user_id is not null
and a.user_id = b.user_id
union all
select * from log a
where a.user_id is null;
解决方法2 :赋与空值分新的key值
select *
from log a
left outer join users b
on case when a.user_id is null then concat(‘hive’,rand() ) else a.user_id end = b.user_id;
ETL中如何替换distinct?
案例1如下:
hive的sql语句,执行效率特别慢,跑了一个多小时程序只是map完了,reduce进行到20%。
该Hive语句如下:
select count(distinct ip)
from (select ip as ip from comprehensive.f_client_boot_daily where year="2013" and month="10"
union all
select pub_ip as ip from f_app_boot_daily where year="2013" and month="10"
union all select ip as ip from format_log.format_pv1 where year="2013" and month="10" and url_first_id=1
) d
分析
总的数据量大约30亿条。这么大的数据量,使用disticnt函数,所有的数据只会shuffle到一个reducer上,导致reducer数据倾斜严重。
解决办法:
通过使用groupby,按照ip进行分组。改写后的sql语句如下:
select count(*)
from
(select ip from (select ip as ip from comprehensive.f_client_boot_daily where year="2013" and month="10"
union all
select pub_ip as ip from f_app_boot_daily where year="2013" and month="10"
union all select ip as ip from format_log.format_pv1 where year="2013" and month="10" and url_first_id=1
) d
group by ip ) b
合理的设置reducer数量,将数据分散到多台机器上。set mapred.reduce.tasks=50;
经过优化后,速度提高非常明显。整个作业跑完大约只需要20多分钟的时间。
案列2如下:
用exists代替distinct
select distinct d.dp_id,d.dp_name from depts d,staffs s where d.dp_id=s.dp_id;
用exists实现如下:
select d.dp_id,d.dp_name from depts d where exists(select null from staffs s where s.dp_id=d.dp_id)
exists语句用来判断()内的表达式是否存在返回值,如果存在就返回true,如果不存在就返回false,所以在上面语句中我们使用select null,因为返回什么数据不重要,重要有值返回就行。
另外exists的有点是,它只要括号中的表达式有一个值存在,就立刻返回true,而不用遍历表中所有的数据。
项目中使用什么调度器?
Yarn中有三种调度器可以选择:FIFO Scheduler (先进先出),Capacity Scheduler(容器调度),FairScheduler(公平调度)。
工作流调度器一般有 azkaban 和 Oozie ,一般项目组会针对这两种自定义封装后使用
就是用JAVA的上传本地文件的方式上传脚本 创建任务 写好调度
跑任务的脚本平台组已经写好了 把自己的脚本和跑任务的shell脚本一起打包就好
如何确保ETL过程数据的一致性和准确性?
这个准确性包含两个方面:数据量的准确性,数值的正确性
数值的正确性
1.如果 ETL 处理的表比较多,那么除了用监控工具之外,我想不到有什么其它好的方法,或者可以写写过程之类的,让它定期运行,获取你关心的一些数据指标。
2.在 ETL 的过程中不对数值型数据据进行四舍五入操作,可有效防止数据精度不丢失,至于客户想看到多少位的精度,我们可以在前端展现中对数据进行格式化。为了让业务人员能更好的理解指标的运算过程,我们一般在展现层以文字或在线帮助的形式对可能会引起歧义的指标给出后台的计算公式,帮助用户更好的理解指标含义
3.对照业务系统数据记录条数和导入之后的记录条数进行比较,一致应该是准确的,不过 DW 中的表要建好主键约束
4.业务系统会有一个时间戳,从昨天的时间戳重新抽取
测试:
转换规则测试
首先是数据格式的合法性。对于数据源中时间、数值、字符等数据的处理,是否符合数据仓库规则,是否进行统一的转换。
其次是值域的有效性。是否有超出维表或者业务值域的范围。
第三是空值的处理。是否捕获字段空值,或者需要对空值进行替换为其他含义值的处理。
第四是主键的有效性。主键是否唯一。
第五是乱码的检查。特殊符号或者乱码符号的护理规则。
第六是脏数据的处理。比如不符合业务逻辑的数据
关键字段测试
通过转换规则,查询关键字段是否正确。比如保费收入字段,看其是否乘以汇率,共保比率等.
数据量:
全量抽取,在抽取完成后 马上比对数据的行数 全量加载一般是先清空再插入(truncate and insert)
增量抽取,增量时间的记录行数 进行比对 增量加载一般是先删后插(delete and insert)
测试:
做好源表和目标表数据量统计对比

