selenium+python之python多线程
程序、进程及线程的区别
计算机程序是磁盘中可执行的二进制数据(或者其他类型)他们只有在被读取到内存中,被操作系统调用才开始他们的生命周期。
进程是程序的一次执行,每个进程都有自己的地址空间,内存,数据栈,以及其他记录其运行轨迹的辅助数据,操作系统管理再其上面运行的所有进程,并为这些进程公平得分配时间。
线程与进程相似,不同的是所有的线程都运行在同一个进程中,共享相同的运行环境。
1.单线程
单线程时,当处理器需要处理多个任务时,必须对这些任务安排执行的顺序,并按照这个顺序来执行任务。
1 from time import sleep, ctime 2 3 4 # 听音乐 5 def music(): 6 print('i was listening to music! %s' % ctime()) 7 sleep(2) 8 9 10 # 看电影 11 def movie(): 12 print('i was at the movies! %s' % ctime()) 13 sleep(5) 14 15 16 if __name__ == '__main__': 17 music() 18 movie() 19 print('all end:', ctime())
增加循环功能:
1 from time import sleep, ctime 2 3 4 # 听音乐 5 def music(func, loop): 6 for i in range(loop): 7 print('i was listening to music! %s !%s' % (func, ctime())) 8 sleep(2) 9 10 11 # 看电影 12 def movie(func, loop): 13 for i in range(loop): 14 print('i was listening to music! %s !%s' % (func, ctime())) 15 sleep(5) 16 17 18 if __name__ == '__main__': 19 music('爱情买卖', 2) 20 movie('一代宗师', 2) 21 print('all end:', ctime())
给music()和movie()两个函数设置参数:播放文件和播放次数。函数中通过for循环控制播放的次数。
2、多线程
python通过两个标准库thread和threading提供对线程的支持。thread提供了低级别的,原始的线程以及一个简单的锁。threading基于Java的线程模型设计。锁(lock)和条件变量(condition)在Java中时对象的基本行为(每个对象都自带了锁和条件变量),而在python中则是独立的对象。
(1)threading模块
避免使用thread模块,原因是它不支持守护线程。当主线程退出时,所有的子线程不关他们是否还在工作,都会被强行退出。但是我们并不希望发生这种行为。就要引入守护线程的概念。threading支持守护线程。
1 from time import sleep, ctime 2 import threading 3 4 5 # 听音乐 6 def music(func, loop): 7 for i in range(loop): 8 print('i was listening to music! %s !%s' % (func, ctime())) 9 sleep(2) 10 11 12 # 看电影 13 def movie(func, loop): 14 for i in range(loop): 15 print('i was listening to music! %s !%s' % (func, ctime())) 16 sleep(5) 17 18 19 # 创建线程数组 20 threads = [] 21 # 创建线程t1,并添加到线程数组 22 t1 = threading.Thread(target=music, args=('爱情买卖', 2)) 23 threads.append(t1) 24 # 创建线程t2,并添加到线程数组 25 t2 = threading.Thread(target=music, args=('一代宗师', 2)) 26 threads.append(t2) 27 28 if __name__ == '__main__': 29 # 启动线程 30 for t in threads: 31 t.start() 32 # 守护线程 33 for t in threads: 34 t.join() 35 36 print('all end:', ctime())
注:import threading: 引入线程模块
threads = []:创建线程数组,用于装载线程。
threading.Thread(): 通过调用threading模块的Thread()方法来创建线程。
运行结果如下:

从上面运行的结果可以看出,两个子线程(music,movie)同时启动于10分15秒,知道所有线程结束于10分17秒共好使2秒。从执行的结果可以看出两个线程达到了并行工作。
优化线程的创建
从上面例子中发现线程的创建很麻烦,每创建一个线程都需要一个t(t1,t2.。。。。)当创建的线程较多时,这样的操作及其的不方便。
1 from time import sleep, ctime 2 import threading 3 4 5 # 创建超级播放器 6 def super_player(file_, loop): 7 for i in range(2): 8 print('start playing: %s !%s' % (file_, ctime())) 9 sleep(2) 10 # 播放文件与播放时长 11 lists = {'爱情买卖.mp3':3,'阿凡达.mp4':5,'传奇.mp3':4} 12 13 threads = [] 14 files = range(len(lists)) 15 print(files) 16 # 创建线程 17 print(lists.items()) 18 for file_,time in lists.items(): 19 t = threading.Thread(target=super_player,args=(file_,time)) 20 print(t) 21 threads.append(t) 22 23 if __name__ == '__main__': 24 # 启动线程 25 for t in files: 26 threads[t].start() 27 # 守护线程 28 for t in files: 29 threads[t].join() 30 31 print(' end:%s'% ctime())
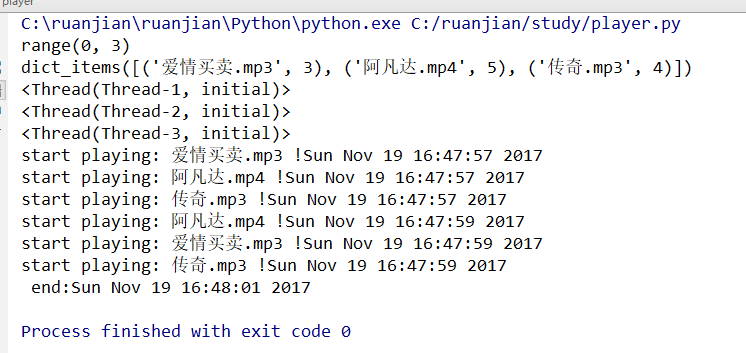
1 from time import sleep, ctime 2 import threading 3 4 5 # 创建超级播放器 6 def super_player(file_, loop): 7 for i in range(3): # 控制线程的循环次数 8 print('start playing: %s !%s' % (file_, ctime())) 9 sleep(3) # 每次循环的间接次数 10 11 12 # 播放文件与播放时长 13 lists = {'爱情买卖.mp3': 3, '阿凡达.mp4': 5, '传奇.mp3': 4} 14 15 threads = [] 16 files = range(len(lists)) 17 print(len(lists)) 18 19 print(files) # 打印的结果是range(0,3) 20 # 创建线程 21 print(lists.items()) 22 for file_, time in lists.items(): 23 t = threading.Thread(target=super_player, args=(file_, time)) 24 print(t) 25 threads.append(t) 26 27 if __name__ == '__main__': 28 # 启动线程 29 for t in files: 30 threads[t].start() 31 # 守护线程 32 for t in files: 33 threads[t].join() 34 35 print(' end:%s' % ctime())
创建了一个super_player()函数,这个函数可以接收播放文件和播放时长,可以播放任何文件。
创建了一个lists字典用于存放播放文件名与时长,通过for循环读取字典,并调用super_play()函数创建字典,接着将创建的字典都追加到threads数组中。
最后通过循环启动线程数组threads中的线程。
创建线程类(未懂)
1 import threading 2 from time import sleep, ctime 3 4 5 # 创建线程类 6 class MyThread (threading.Thread): 7 def __init__(self, func, args, name=''): 8 threading.Thread.__init__ (self) 9 self.func = func 10 self.args = args 11 self.name = name 12 13 def run(self): 14 self.func (*self.args) 15 16 17 # 创建超级播放器 18 def super_player(file_, loop): 19 for i in range (3): # 控制线程的循环次数 20 print ('start playing: %s !%s' % (file_, ctime ())) 21 sleep (3) # 每次循环的间接次数 22 23 24 # 播放文件与播放时长 25 lists = {'爱情买卖.mp3': 3, '阿凡达.mp4': 5, '传奇.mp3': 4} 26 27 threads = [] 28 files = range (len (lists)) 29 print (len (lists)) 30 31 print (files) # 打印的结果是range(0,3) 32 # 创建线程 33 print (lists.items ()) 34 for file_, time in lists.items (): 35 t = threading.Thread (target=super_player, args=(file_, time)) 36 print (t) 37 threads.append (t) 38 39 if __name__ == '__main__': 40 # 启动线程 41 for t in files: 42 threads[t].start () 43 # 守护线程 44 for t in files: 45 threads[t].join () 46 47 print (' end:%s' % ctime ())
MyThread(threading.Thread)
创建MyThread类,用于继承threading.Thread类
__init__()类的初始化方法对func,args,name等参数进行初始化。
self.func (*self.args)函数的作用是当函数参数已经存在于一个元组或者字典中时,apply()间接地调用函数。args是一个包含将要提供给函数的按位置传递的参数元组。
如果省略了args,则任何参数不会被传递,kwargs是一个包含关键字参数的字典。
注:以上内容为转载
