DeepSeek引发的AI发展路径思考
 在规模法则(Scaling Law)之外,DeepSeek 引领人工智能行业进入以算法和模型架构优化为主,同时高度重视数据质量与规模、理性提高算力的新时期。
在规模法则(Scaling Law)之外,DeepSeek 引领人工智能行业进入以算法和模型架构优化为主,同时高度重视数据质量与规模、理性提高算力的新时期。
DeepSeek引发的AI发展路径思考
参考文章来源于科技导报 ,作者李国杰院士 | 哈工大 DeepSeek 技术前沿与应用讲座
1. DeepSeek 的科技突破
7 天之内 DeepSeek 的用户增长超过 1 亿,此同时,芯片巨头公司英伟达(NVIDIA)的股价单日暴跌 17%,市值缩水 5890 亿美元。
DeepSeek 的崛起(高效率,低成本):
- 人工智能行业以算法和模型架构优化为主 | 打破了高算力和高投入是发展人工智能唯一途径;
- 高度重视数据质量与规模、理性提高算力 | 打破了集成电路制度优势 = 人工智能技术霸权;;
全球人工智能龙头企业主动融入 DeepSeek 生态,相继宣布在其 AI 服务平台上部署 DeepSeek V3 和 R1 模型,而 DeepSeek 的 V3 和 R1 在模型算法和系统软件层次都有重大创新,并且证明了推理模型的开发比想象中更为简单。
核心贡献
- 引入强化学习 (RL) ,模型自主学习到推理能力,性能接近 o1 模型;
- 极致的模型架构优化,训练,推理速度更快,远超 o1 类模型;
- 开源模型及其蒸馏子模型;
NLP的第六次范式变迁—推理能力
- 小规模专家知识:1950~1990;
- 浅层机器学习算法:1990~2010;
- 深度学习:2010~2017;
- 预训练语言模型:2018~2023;
- 大模型:2023~2024;
- 推理(Reasoning):2025(DeepSeek);
DeepSeek 发展历程
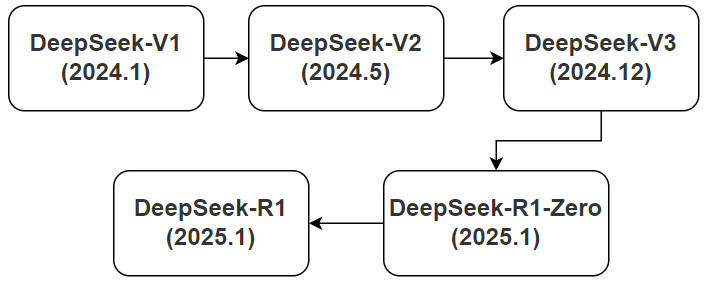
- 引入 GRPO无需价值网络,在提高学习稳定性的同时降低学习开销;
- GRPO 利用当前策略模型进行多次采样,使用平均奖励值近似价值函数;
强化学习(RL)
-
将 RL 引入模型,使用 RL 学习推理能力;
-
RL 不需要复杂的算法,简答 GRPO 即够用;
-
随着 RL 步骤数的增加,模型的性能逐步增强;
-
RL 需要大量的数据,但训练过程中不需要过程奖励,结果奖励足够;
-
RL 的 Aha 时刻:随着 RL 步骤数的增加,会在某一步突然涌向出反思/自我评估机制;
DeepSeek-V3
-
用型 NLP 模型,适合广泛的多任务场景,强调高效性和多模态处理能力。
-
模型参数量 6710 亿,采用自主研发的混合专家模型(MoE)架构,每一层有 256 个细分领域的路由专家和 1 个共享专家,每次调用只激活约 370 亿个参数,显著降低了训练计算成本;
-
改进的多头潜在注意力机制(MLA),减少了键值缓存开销,把显存占用降到了其他大模型的 5%~13%,极大提升了模型运行效率;
DeepSeek-R1
- 专精于复杂逻辑推理的优化版本,通过强化学习提升推理能力,适用于科研、金融量化等高复杂度任务。
- 模型摒弃了传统的监督微调(SFT),开创性地提出群组相对策略优化(GRPO),直接通过强化学习从基础模型中激发推理能力,大幅降低了数据标注成本,简化了训练流程。
2. 规模法则(Scaling Law)的尽头
术之尽头
2020 年 1 月,OpenAI 发表论文《神经语言模型的规模法则》(Scaling Laws for Neural Language Models),提出规模法则:“通过增加模型规模、数据量和计算资源,可以显著提升模型性能。
不同于牛顿定律是经过无数次验证的科学定律,规模法则是 OpenAI 等公司在大模型研制过程中的经验归纳:
- 从科学研究的角度看,属于一种对技术发展趋势的猜想;
- 从投资的角度看,属于对某种技术路线的押注;
- 一种信仰或猜想当成科学公理,不是科学的态度;
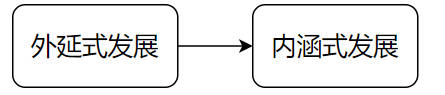
继续投入巨资追求高算力?还是在算法优化上下更多功夫?DeepSeek 的问世标志着人工智能训练模式从“大力出奇迹”的外延式发展阶段,转向集约化系统优化的内涵式发展阶段。
3. 通用人工智能”(AGI)的技术路线
莫拉维克悖论:“复杂的问题是易解的,简单的问题反而是难解的。”
通用人工智能尚未得到准确共识,目前人工智能学术界更关注智能系统持续学习,自我改进的能力。人工智能的通用性不仅表现在对语言的处理上,还包括像人一样基于常识和日常经验与外部客观世界互动的能力。
在科学技术领域,所谓“通用”一定是相对的,有一定的条件或范围。我们要认识人工智能的局限性,不能盲目追求能够解决所有问题的人工智能。 而不同公司走向“通用人工智能”(AGI)的技术路线不同(类比集成电路领域就有“通用”与“专用”10 年交替演化的“牧本周期”):
OpenAI(由通到专)
-
路线:参考 Scaling Law 扩大模型规模,先做出通用的基础模型,再“蒸馏”出各行业可使用的行业垂直模型;
-
关键问题:大模型训练成本 | 保持模型泛化的同时提高特定领域的性能和效率
DeepSeek(由专到通)
-
路线:在模型算法和工程优化方面进行系统级创新,为在受限资源下探索通用人工智能开辟新的道路;
-
混合专家模型:集小智为大智,集专智为通智。“小而精”的模型将人工智能的重点发展方向从面向企业的 to B 引向更贴近消费者的 to C;
-
关键问题:整合多个专用模型为通用模型也需要解决诸多技术和工程问题,如模型间的接口、数据格式的统一、训练时的负载平衡等;
4. 高算例 OR 高能效
发展人工智能的初始动机是模拟人脑,自然界进化了数百万年的人脑是一个计算效率和能效极高的计算装置,功耗只有 20W 左右。
- 人脑的极低功耗是因为采取了分布式的模拟计算;
- 目前计算机的高能耗是因为采用软硬件分离的数字计算;
低成本是技术普及的基本要求,蒸汽机、电力和计算机的普及都是其成本降低到大众可以接受时才做到的,人工智能肯定也会走这条路。
5. 开源生态
将 DeepSeek 提供的小而精的模型下载到本地,即使断网也可以“蒸馏”出高效率的垂直模型
真正的 AI 竞争,不仅仅是技术和模型的竞争,更是生态系统、商业模式,以及价值观的竞争。开源模型让每个开发者都能轻松调用强大 AI 工具,不再受大公司的约束,AI 的进化速度将会明显提升。
技术创新
长期以来,中国人工智能领域的高技术企业大多重视应用创新和商业模式创新,追求的目标是快速盈利,很少参与核心技术创新。人工智能不同于资本密集型和经验积累型的集成电路产业,不仅要“烧钱”,更要“烧脑”,本质上是拼人的智力的新兴产业。因此人工智能产业具有明显的不对称性,一个具有 100 多个聪明头脑的小企业就可以挑战市值上万亿的龙头企业。
产业生态
要实现人工智能自立自强,最困难的是构建自主可控的产业生态。英伟达公司的“护城河”不是 GPU 芯片本身,而是统一计算设备架构(CUDA)软件生态。DeepSeek 冲击了 CUDA 生态,但没有完全绕过 CUDA,其生态壁垒仍然存在。从长远来讲,需要开发一套比 CUDA 更优秀的自主可控的 AI 软件工具系统,重构 AI 软件生态。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号