Hadoop源码解析-6
Hadoop源码解析-6
MapReduce源码解析
Job提交流程源码和切片源码详解
Job提交流程源码详解
waitForCompletion()
submit();
// 1建立连接
connect();
// 1)创建提交Job的代理
new Cluster(getConfiguration());
// (1)判断是本地运行环境还是yarn集群运行环境
initialize(jobTrackAddr, conf);
// 2 提交job
submitter.submitJobInternal(Job.this, cluster)
// 1)创建给集群提交数据的Stag路径
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
// 2)获取jobid ,并创建Job路径
JobID jobId = submitClient.getNewJobID();
// 3)拷贝jar包到集群
copyAndConfigureFiles(job, submitJobDir);
rUploader.uploadFiles(job, jobSubmitDir);
// 4)计算切片,生成切片规划文件
writeSplits(job, submitJobDir);
maps = writeNewSplits(job, jobSubmitDir);
input.getSplits(job);
// 5)向Stag路径写XML配置文件
writeConf(conf, submitJobFile);
conf.writeXml(out);
// 6)提交Job,返回提交状态
status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());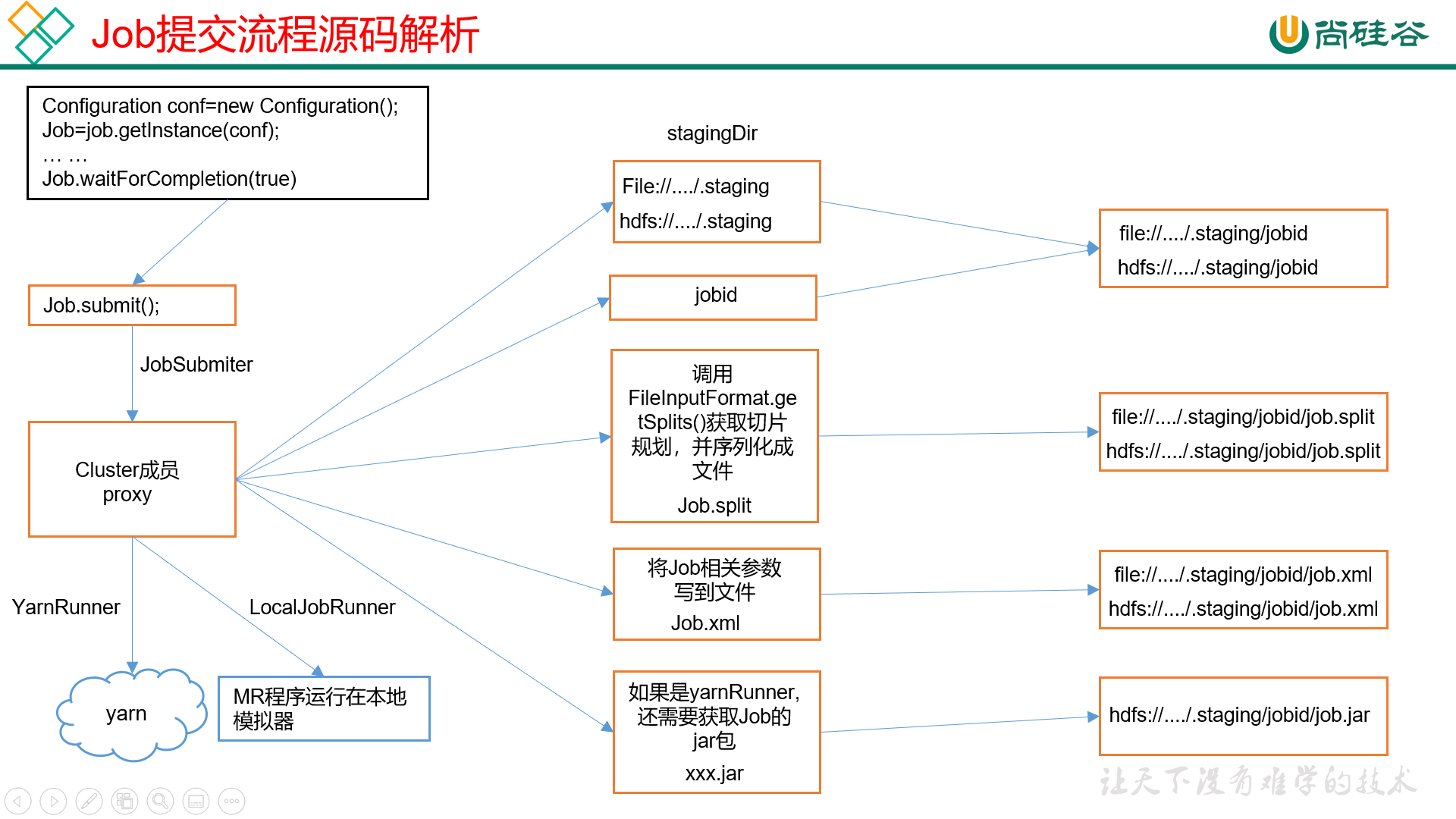
FileInputFormat切片源码解析(input.getSplits(job))

5.2 MapTask & ReduceTask源码解析
MapTask源码解析流程
=================== MapTask ===================
context.write(k, NullWritable.get()); //自定义的map方法的写出,进入
output.write(key, value);
//MapTask727行,收集方法,进入两次
collector.collect(key, value,partitioner.getPartition(key, value, partitions));
HashPartitioner(); //默认分区器
collect() //MapTask1082行 map端所有的kv全部写出后会走下面的close方法
close() //MapTask732行
collector.flush() // 溢出刷写方法,MapTask735行,提前打个断点,进入
sortAndSpill() //溢写排序,MapTask1505行,进入
sorter.sort() QuickSort //溢写排序方法,MapTask1625行,进入
mergeParts(); //合并文件,MapTask1527行,进入

collector.close(); //MapTask739行,收集器关闭,即将进入ReduceTask
ReduceTask源码解析流程
=================== ReduceTask ===================
if (isMapOrReduce()) //reduceTask324行,提前打断点
initialize() // reduceTask333行,进入
init(shuffleContext); // reduceTask375行,走到这需要先给下面的打断点
totalMaps = job.getNumMapTasks(); // ShuffleSchedulerImpl第120行,提前打断点
merger = createMergeManager(context); //合并方法,Shuffle第80行
// MergeManagerImpl第232 235行,提前打断点
this.inMemoryMerger = createInMemoryMerger(); //内存合并
this.onDiskMerger = new OnDiskMerger(this); //磁盘合并
rIter = shuffleConsumerPlugin.run();
eventFetcher.start(); //开始抓取数据,Shuffle第107行,提前打断点
eventFetcher.shutDown(); //抓取结束,Shuffle第141行,提前打断点
copyPhase.complete(); //copy阶段完成,Shuffle第151行
taskStatus.setPhase(TaskStatus.Phase.SORT); //开始排序阶段,Shuffle第152行
sortPhase.complete(); //排序阶段完成,即将进入reduce阶段 reduceTask382行
reduce(); //reduce阶段调用的就是我们自定义的reduce方法,会被调用多次
cleanup(context); //reduce完成之前,会最后调用一次Reducer里面的cleanup方法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号