
Hadoop生产调优手册-2
Hadoop生产调优手册-2
HDFS——集群压测
测试HDFS写性能
写测试底层原理
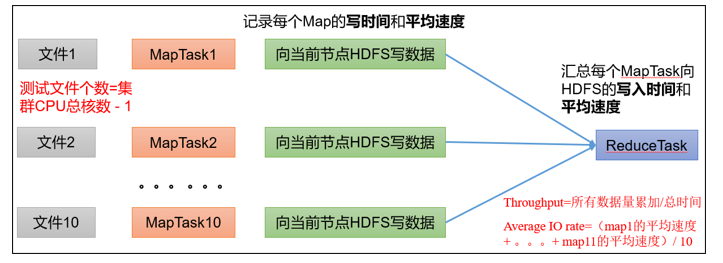
测试内容:向集群写5个128MB的文件
[atguigu@hadoop102 mapreduce]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 128MB
2021-02-09 10:43:16,853 INFO fs.TestDFSIO: ----- TestDFSIO ----- : write
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Date & time: Tue Feb 09 10:43:16 CST 2021
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Number of files: 10
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Total MBytes processed: 1280
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Throughput mb/sec: 1.61
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Average IO rate mb/sec: 1.9
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: IO rate std deviation: 0.76
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Test exec time sec: 133.05
2021-02-09 10:43:16,854 INFO fs.TestDFSIO:
注意:nFiles n为生成mapTask的数量,生产环境一般可通过hadoop103:8088查看CPU核数,设置为(CPU核数-1)
Number of files:生成mapTask数量,一般是集群中(CPU核数-1),我们测试虚拟机就按照实际的物理内存-1分配即可Total MBytes processed:单个map处理的文件大小Throughput mb/sec:单个mapTak的吞吐量计算方式:处理的总文件大小/每一个mapTask写数据的时间累加
集群整体吞吐量:生成mapTask数量*单个mapTak的吞吐量
Average IO rate mb/sec:平均mapTak的吞吐量计算方式:每个mapTask处理文件大小/每一个mapTask写数据的时间
全部相加除以task数量
IO rate std deviation:方差、反映各个mapTask处理的差值,越小越均衡
注意:如果测试过程中出现异常
可以在yarn-site.xml中设置虚拟内存检测为false
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true --> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property>分发配置并重启Yarn集群
测试结果分析
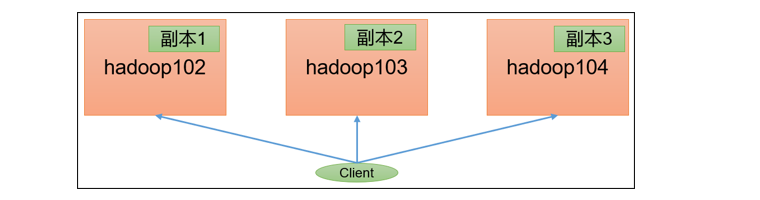
由于副本1就在本地,所以该副本不参与测试

副本测试-1 一共参与测试的文件:10个文件 * 2个副本 = 20个
压测后的速度:1.61
实测速度:1.61M/s * 20个文件 ≈ 32M/s
三台服务器的带宽:12.5 + 12.5 + 12.5 ≈ 30m/s
所有网络资源都已经用满。
如果实测速度远远小于网络,并且实测速度不能满足工作需求,可以考虑采用固态硬盘或者增加磁盘个数。
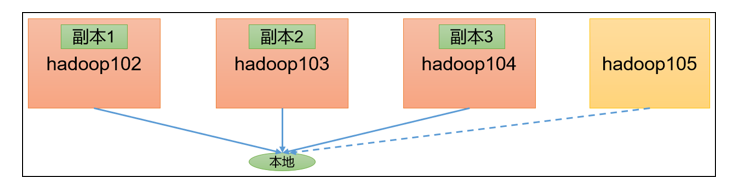
如果客户端不在集群节点,那就三个副本都参与计算
副本测试-2
测试HDFS读性能
测试内容:读取HDFS集群10个128M的文件
[atguigu@hadoop102 mapreduce]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 128MB
2021-02-09 11:34:15,847 INFO fs.TestDFSIO: ----- TestDFSIO ----- : read
2021-02-09 11:34:15,847 INFO fs.TestDFSIO: Date & time: Tue Feb 09 11:34:15 CST 2021
2021-02-09 11:34:15,847 INFO fs.TestDFSIO: Number of files: 10
2021-02-09 11:34:15,847 INFO fs.TestDFSIO: Total MBytes processed: 1280
2021-02-09 11:34:15,848 INFO fs.TestDFSIO: Throughput mb/sec: 200.28
2021-02-09 11:34:15,848 INFO fs.TestDFSIO: Average IO rate mb/sec: 266.74
2021-02-09 11:34:15,848 INFO fs.TestDFSIO: IO rate std deviation: 143.12
2021-02-09 11:34:15,848 INFO fs.TestDFSIO: Test exec time sec: 20.83
删除测试生成数据
[atguigu@hadoop102 mapreduce]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -clean
测试结果分析
为什么读取文件速度大于网络带宽?由于目前只有三台服务器,且有三个副本,数据读取就近原则,相当于都是读取的本地磁盘数据,没有走网络。
HDFS——多目录
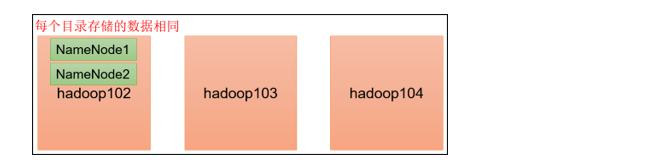
NameNode多目录配置
NameNode的本地目录可以配置成多个,且每个目录存放内容相同,增加了可靠性
具体配置如下
在
hdfs-site.xml文件中添加如下内容<property> <name>dfs.namenode.name.dir</name> <value>file://${hadoop.tmp.dir}/dfs/name1,file://${hadoop.tmp.dir}/dfs/name2</value> </property>注意:因为每台服务器节点的磁盘情况不同,所以这个配置配完之后,可以选择不分发
停止集群,删除三台节点的data和logs中所有数据
[atguigu@hadoop102 hadoop-3.1.3]$ rm -rf data/ logs/ [atguigu@hadoop103 hadoop-3.1.3]$ rm -rf data/ logs/ [atguigu@hadoop104 hadoop-3.1.3]$ rm -rf data/ logs/格式化集群并启动
[atguigu@hadoop102 hadoop-3.1.3]$ bin/hdfs namenode -format [atguigu@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh查看结果
[atguigu@hadoop102 dfs]$ ll 总用量 12 drwx------. 3 atguigu atguigu 4096 12月 11 08:03 data drwxrwxr-x. 3 atguigu atguigu 4096 12月 11 08:03 name1 drwxrwxr-x. 3 atguigu atguigu 4096 12月 11 08:03 name2检查name1和name2里面的内容,发现一模一样。
DataNode多目录配置
DataNode可以配置成多个目录,每个目录存储的数据不一样(数据不是副本)
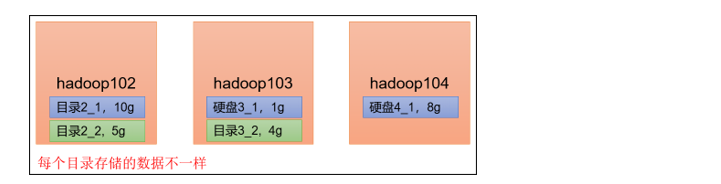
具体配置如下
在hdfs-site.xml文件中添加如下内容
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data1,file://${hadoop.tmp.dir}/dfs/data2</value>
</property>
查看结果
[atguigu@hadoop102 dfs]$ ll
总用量 12
drwx------. 3 atguigu atguigu 4096 4月 4 14:22 data1
drwx------. 3 atguigu atguigu 4096 4月 4 14:22 data2
drwxrwxr-x. 3 atguigu atguigu 4096 12月 11 08:03 name1
drwxrwxr-x. 3 atguigu atguigu 4096 12月 11 08:03 name2
向集群上传一个文件,再次观察两个文件夹里面的内容发现不一致(一个有数一个没有)
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs dfs -put wcinput/word.txt /
集群数据均衡之磁盘间数据均衡
生产环境,由于硬盘空间不足,往往需要增加一块硬盘。刚加载的硬盘没有数据时,可以执行磁盘数据均衡命令。(Hadoop3.x新特性)
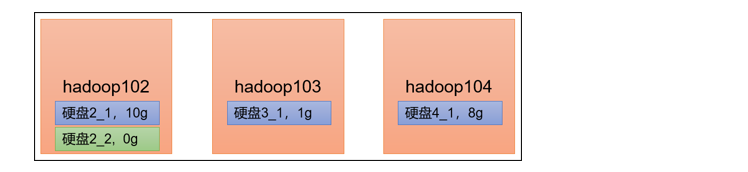
生成均衡计划(只有一块磁盘,不会生成计划)
hdfs diskbalancer -plan hadoop103
执行均衡计划
hdfs diskbalancer -execute hadoop103.plan.json
查看当前均衡任务的执行情况
hdfs diskbalancer -query hadoop103
取消均衡任务
hdfs diskbalancer -cancel hadoop103.plan.json
本文作者:逆十字
本文链接:https://www.cnblogs.com/fengxiaolong/p/15806925.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步