sharding-jdbc分库分表
1. 分库分表目的
- 为了解决由于数据量过大而造成数据库性能降低问题。
2. 分库分表有两种拆分方式:垂直拆分和水平拆分。
-
垂直分表:按照表字段进行拆分,常用字段存一张表,其余字段存一张表。
-
垂直分库:单一的数据库按照业务进行拆分,做到专库专表(例如商品表和订单表存在不同的库)。
-
水平拆分:简单说就是数据离散存储,相同结构的表拆成多个表或者多个库,拆分后结构保持一样,没有任何变化(例如商品表1,商品表2,商品库1,商品库2....)
3. shardingjdbc对分库分表操作配置
-
逻辑表:存在于不同数据库或者同一个数据库中结构相同的表名称的公共部分(例如,t_user1,t_user2的逻辑表名称是t_user)
-
inline 行表达式分片策略(水平分库和分表,数据库db0,db1中都有t_user0,t_user1两张表)
#分库分表配置
spring:
main:
allow-bean-definition-overriding: true #是否允许bean(dataSource)覆盖,否则可能会由于bean重复报错
shardingsphere:
# 参数配置,显示sql
props:
sql:
show: true
# 配置数据源
datasource:
# 给每个数据源取别名,下面的db0,db1任意取名字
names: db0,db1
# db0
db0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.1.9:3306/java_sharding_db0?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password: 1004
# db1
db1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/java_sharding_db1?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password: 1004
# 配置默认数据源db0
sharding:
# 默认数据源
default-data-source-name: db0
# 配置分表的规则
tables:
# 逻辑表名
t_user:
# 数据节点:数据源$->{0..N}.逻辑表名$->{0..N}
actual-data-nodes: db$->{0..1}.t_user$->{0..1}
# 拆分库策略,也就是什么样子的数据放入放到哪个数据库中。
database-strategy:
inline:
sharding-column: age # 分片字段(分片键)
algorithm-expression: db$->{age % 2} # 分片算法表达式 最终结果db0或db1
# 拆分表策略,也就是什么样子的数据放入放到哪个数据表中。
table-strategy:
#策略inline
inline:
sharding-column: sex # 分片字段(分片键)
algorithm-expression: t_user$->{sex % 2} # 分片算法表达式 最终结果t_user0或t_user1
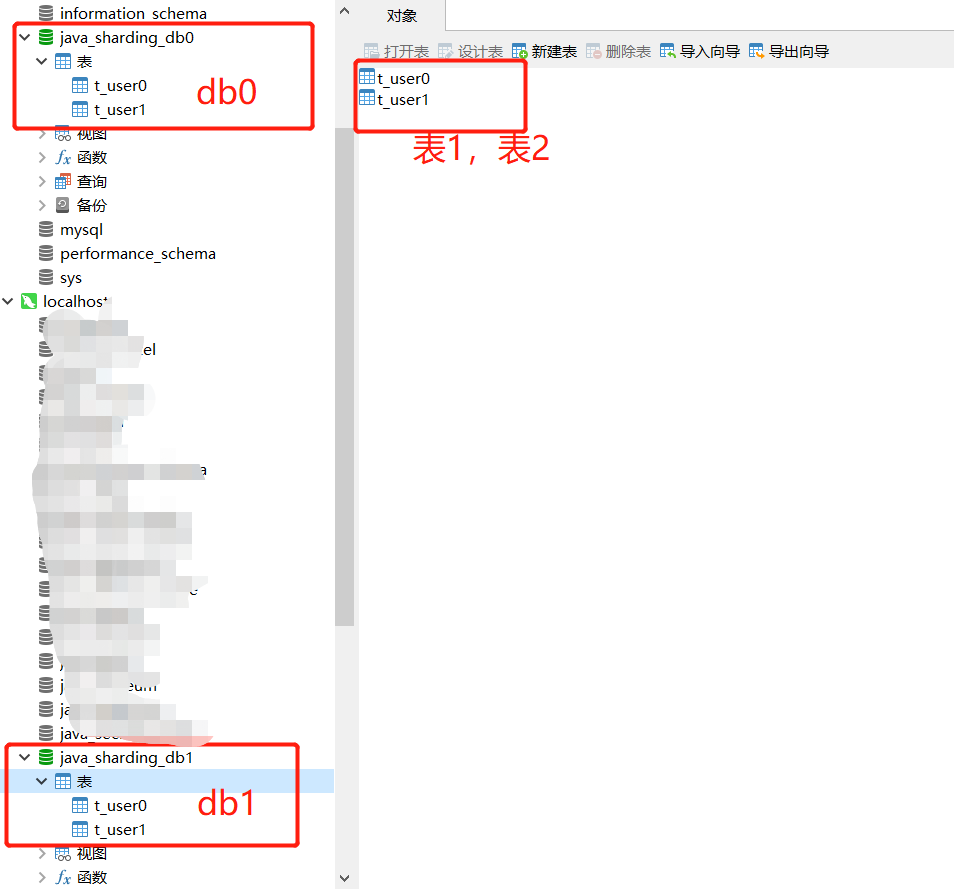
分别把两个库db0,db1创建在不同的服务器,用本机代替一个,虚拟机代替一个,数据库如下图
在Controller编写新增user接口测试
@PostMapping(value = "/save")
public String save(@RequestBody User user) {
userService.save(user);
return "ok";
}
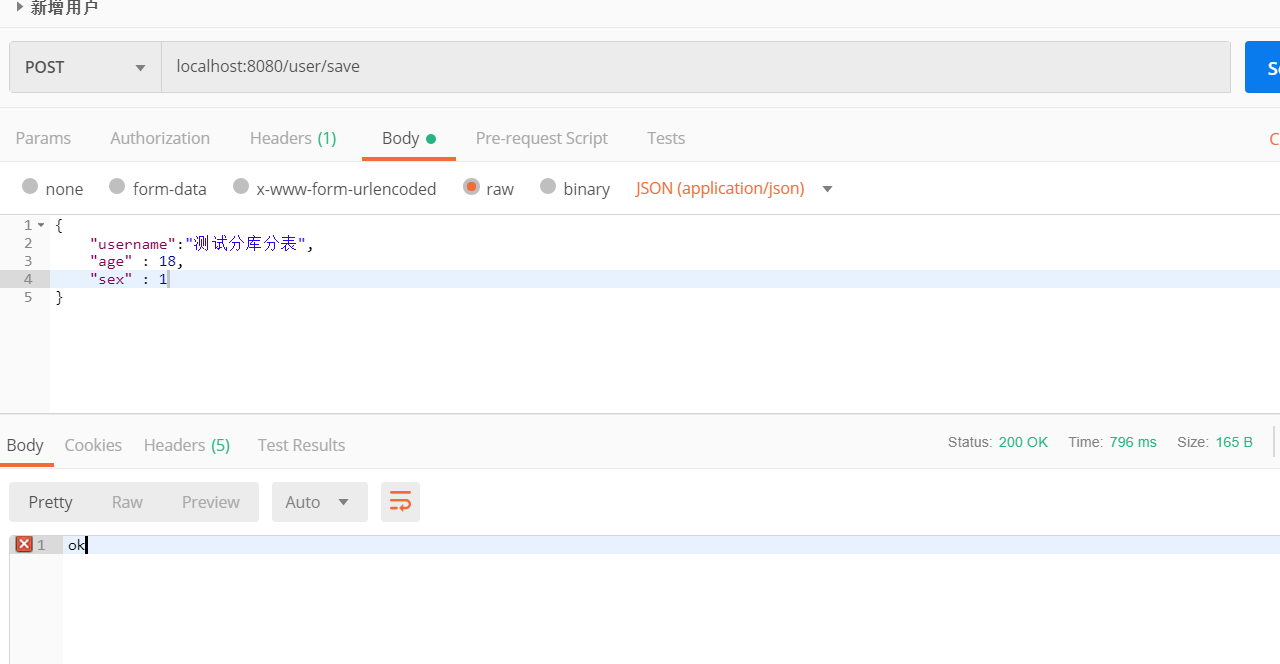
postman测试新增用户
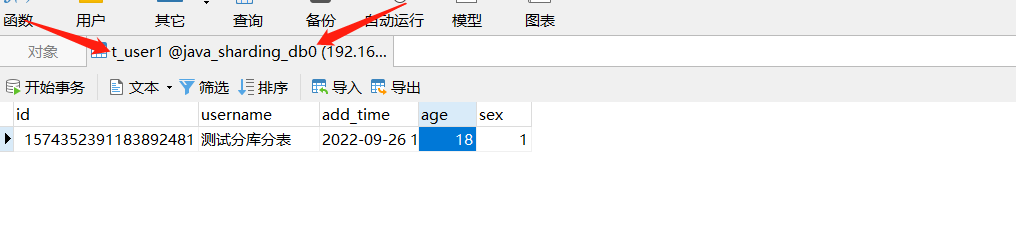
根据分表分库inline策略,age为偶数存到db0库,age为奇数存到db1库;sex为偶数存到t_user0表,sex奇数存到t_user1表。所以新增的数据存到db0库的t_user1表中。
- 根据时间日期规则操作分库分表
sharding-jdbc提供了一个PreciseShardingAlgorithm接口,主要用于配置时间策略操作分库分表,自定义ShardingConfig实现PreciseShardingAlgorithm接口。
public class ShardingConfig implements PreciseShardingAlgorithm<Date> {
List<Date> dateList = new ArrayList<>();
{
Calendar calendar= Calendar.getInstance();
Calendar calendar1 = Calendar.getInstance();
calendar.set(2021, 1, 1, 0, 0, 0);
calendar1.set(2022, 1, 1, 0, 0, 0);
dateList.add(calendar.getTime());
dateList.add(calendar1.getTime());
}
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<Date> preciseShardingValue) {
// 获取属性数据库的值
Date date = preciseShardingValue.getValue();
// 获取数据源的名称信息列表
Iterator<String> iterator = collection.iterator();
String target = null;
for (Date item : dateList) {
target = iterator.next();
// 如果数据晚于指定的日期直接返回
if (item.after(date)) {
break;
}
}
//最终返回db0或db1
return target;
}
}
相应的yml策略配置如下
database-strategy:
standard:
sharding-column: birthday
preciseAlgorithmClassName: com.fj.datasource.config.ShardingConfig
table-strategy:
inline:
sharding-column: sex # 分片字段(分片键)
algorithm-expression: t_user$->{sex % 2} # 分片算法表达式 最终结果t_user0或t_user1

