

摘要:
Py2neo:一种快速导入百万数据到Neo4j的方式 Py2neo是一个可以和Neo4j图数据库进行交互的python包。虽然py2neo操作简单方便,但是当节点和关系达几十上百万时,直接创建和导入节点、关系的方式会越来越耗时。本文提供一个py2neo小技巧,通过简单的代码,能够以每秒1万节点/关系 阅读全文
摘要: 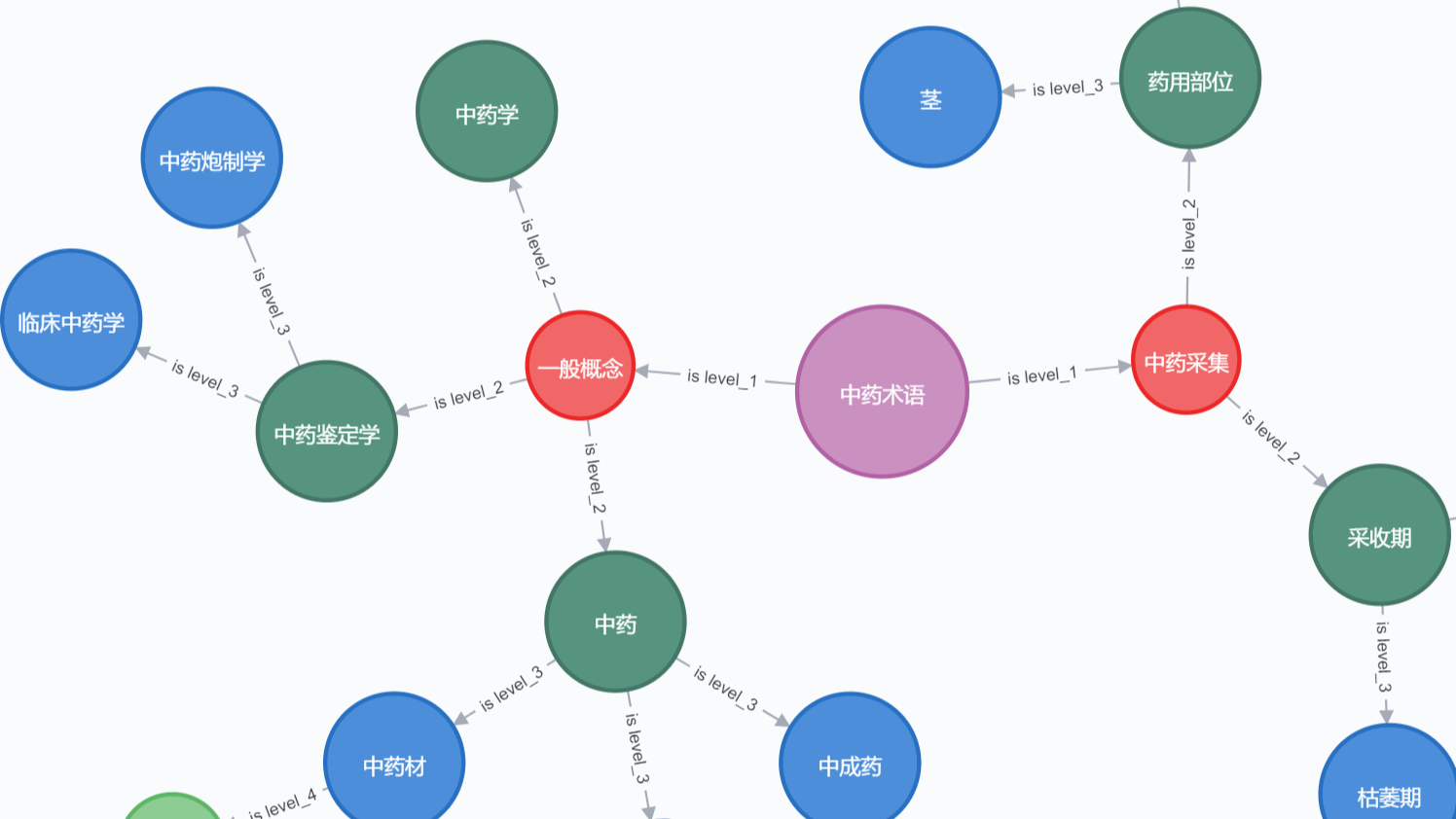 当前,知识图谱已在金融、电商和医疗等领域开展了诸多实践性探索,并被广泛的应用在了智能问答、知识搜索、个性化推荐和辅助诊断等知识型驱动的任务中。本文从中药和知识图谱研究视角出发,对所收集中药相关数据进行预处理与实体关系抽取,自顶向下构建中药知识图谱。同时利用neo4j对部分数据进行了可视化分析。 阅读全文
当前,知识图谱已在金融、电商和医疗等领域开展了诸多实践性探索,并被广泛的应用在了智能问答、知识搜索、个性化推荐和辅助诊断等知识型驱动的任务中。本文从中药和知识图谱研究视角出发,对所收集中药相关数据进行预处理与实体关系抽取,自顶向下构建中药知识图谱。同时利用neo4j对部分数据进行了可视化分析。 阅读全文
当前,知识图谱已在金融、电商和医疗等领域开展了诸多实践性探索,并被广泛的应用在了智能问答、知识搜索、个性化推荐和辅助诊断等知识型驱动的任务中。本文从中药和知识图谱研究视角出发,对所收集中药相关数据进行预处理与实体关系抽取,自顶向下构建中药知识图谱。同时利用neo4j对部分数据进行了可视化分析。 阅读全文
摘要:
数据可视化是一种直观展示数据结果和变化情况的方法,可视化有助于知识发现与应用。Neo4j数据库对于知识图谱的展示形式过于单调。因此,本文基于pyecharts对当前处理的中药知识图谱数据进行分析与可视化。以利用图形传递和表达更清晰的中药知识图谱信息,发掘有潜在价值的内容。 阅读全文
摘要:
正常安装流程 1、安装anaconda 必备条件 2、安装jupyter notebook 一般anaconda自带安装 如没有,则在终端安装 conda install jupyter notebook 3、安装nb-conda 接下来安装nb_conda... 阅读全文
摘要:
Keras网络可视化方法 Keras模型可视化 Keras可视化依赖的两个包参考链接 Keras模型可视化 代码: from ke... 阅读全文
摘要:
python中文分词方法之基于规则的中文分词 目录 常见中文分词方法 推荐中文分词工具 参考链接 一、四种常见的中文分词方法: ... 阅读全文
摘要:
直接快速下载NLTK数据 直接下载NLTK的数据速度很慢,这里提供NLTK数据集,直接下载即可。或者选择下列百度云下载: 链接:h... 阅读全文
摘要:
python3中的常见知识点3——reduce()函数 python3导入reduce()函数reduce()函数语法reduce(... 阅读全文
摘要:
python random模块几个常用方法 random.random()方法random.uniform(a, b)方法rando... 阅读全文
摘要:
python 爬取豆瓣电影评论,并进行词云展示 本文旨在提供爬取豆瓣电影《我不是药神》评论和词云展示的代码样例 1、分析URL2、爬... 阅读全文
摘要:
保存sklearn中模型的两种方法(pickle、joblib) from sklearn import svmfrom sklea... 阅读全文
摘要:
python爬取网易云音乐评论及相关信息 urllibrequests正则表达式爬取网易云音乐评论及相关信息 urllib了解 参... 阅读全文
摘要:
python安装包出现的两个问题 error: Unable to find vcvarsall.batNo module name... 阅读全文
摘要:
python 中文分词工具 jieba,https://github.com/fxsjy/jiebajieba_fast,https... 阅读全文
摘要:
python3中的常见知识点2 列表与栈和队列map()函数python列表遍历的4种方式参考链接 列表栈和队列 1、列表作为栈使... 阅读全文
摘要:
python3中的常见知识点1 简记一些python小知识 字符串输出docstring(文档字符串)Lambda 函数(匿名函数)... 阅读全文
摘要:
Python编程规范—PEP8 PEP是 Python Enhancement Proposal 的缩写. 英文链接: https... 阅读全文
摘要:
K近邻算法(K-nearest neighbor, KNN) KNN是一种分类和回归方法。 KNN简介KNN模型3要素KNN优缺点K... 阅读全文
摘要:
python文件名解析—从文件名获得分类类别 python os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名... 阅读全文
摘要:
1、将需要引用的参考文献新建为.bib格式,例如referencesTest.bib文件,具体如下:新建txt文件,后缀名改为.bib;然后打开谷歌学术,搜索参考文献, 点击导入BibTeX,具体如下图:图1---导入BibTeX方法图2---将BibTex格... 阅读全文