
python爬取网易云音乐评论及相关信息
python爬取网易云音乐评论及相关信息
- urllib
- requests
- 正则表达式
- 爬取网易云音乐评论及相关信息
urllib了解
requests了解
参考链接:
http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
正则表达式
参考链接:
http://www.runoob.com/python/python-reg-expressions.html
爬取网易云音乐评论及相关信息
1、分析网易云页面
2、获取加密的参数 params 和 encSecKey
3、爬取网易云音乐评论及相关信息
1、分析网易云音乐页面
参考链接https://blog.csdn.net/fengxinlinux/article/details/77950209
爬取网易云音乐的评论,首先在浏览器打开一首需要爬取评论的歌曲页面,比如:https://music.163.com/#/song?id=862102137
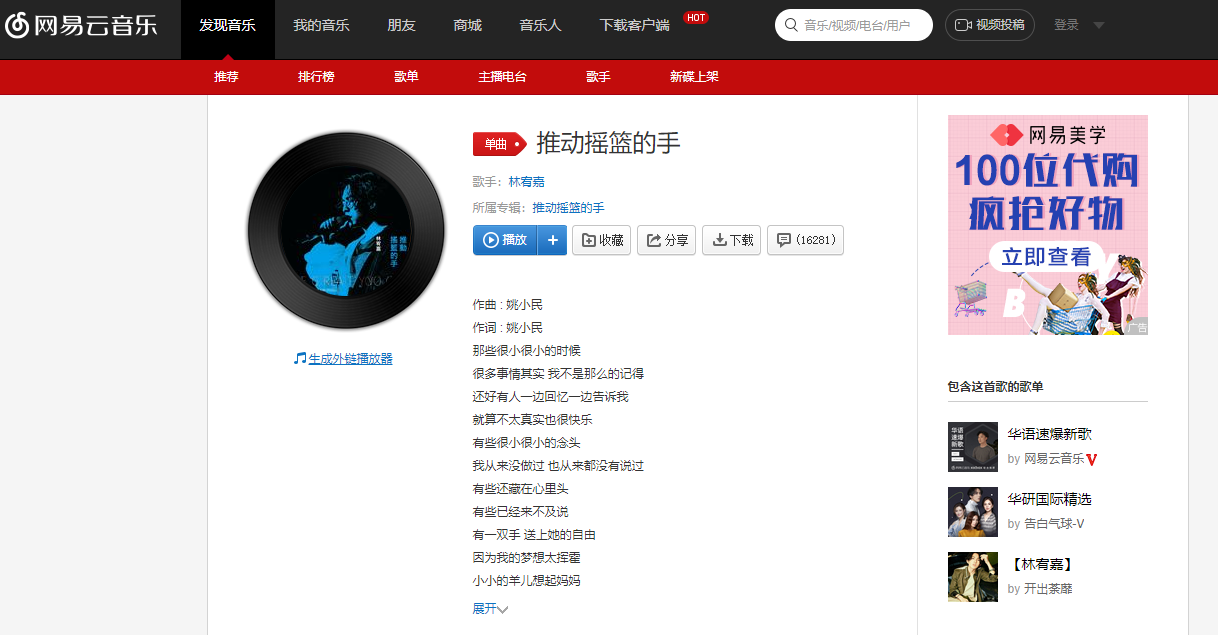
然后,在Chrome浏览器(其他类似)按F12键,按F5刷新,根据下图箭头顺序,按顺序操作
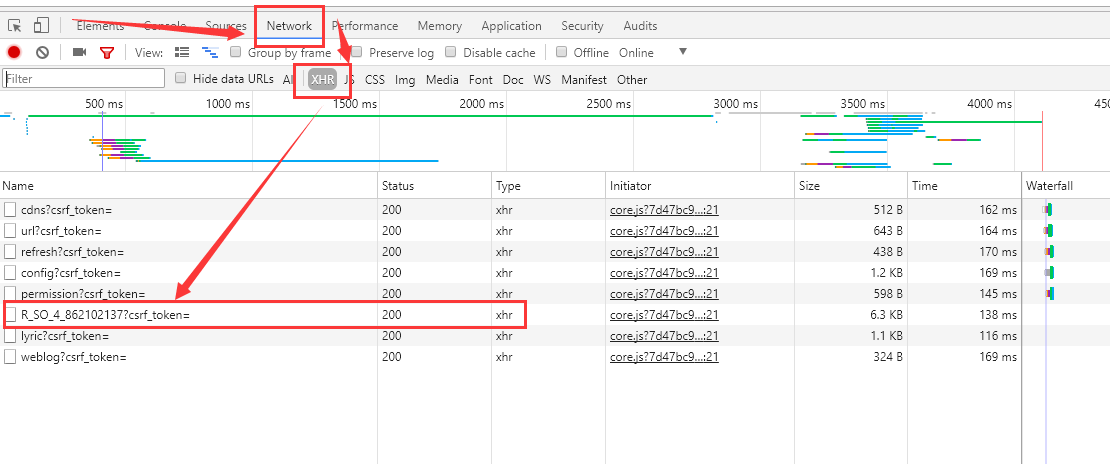
如下图所示,即为页面信息。
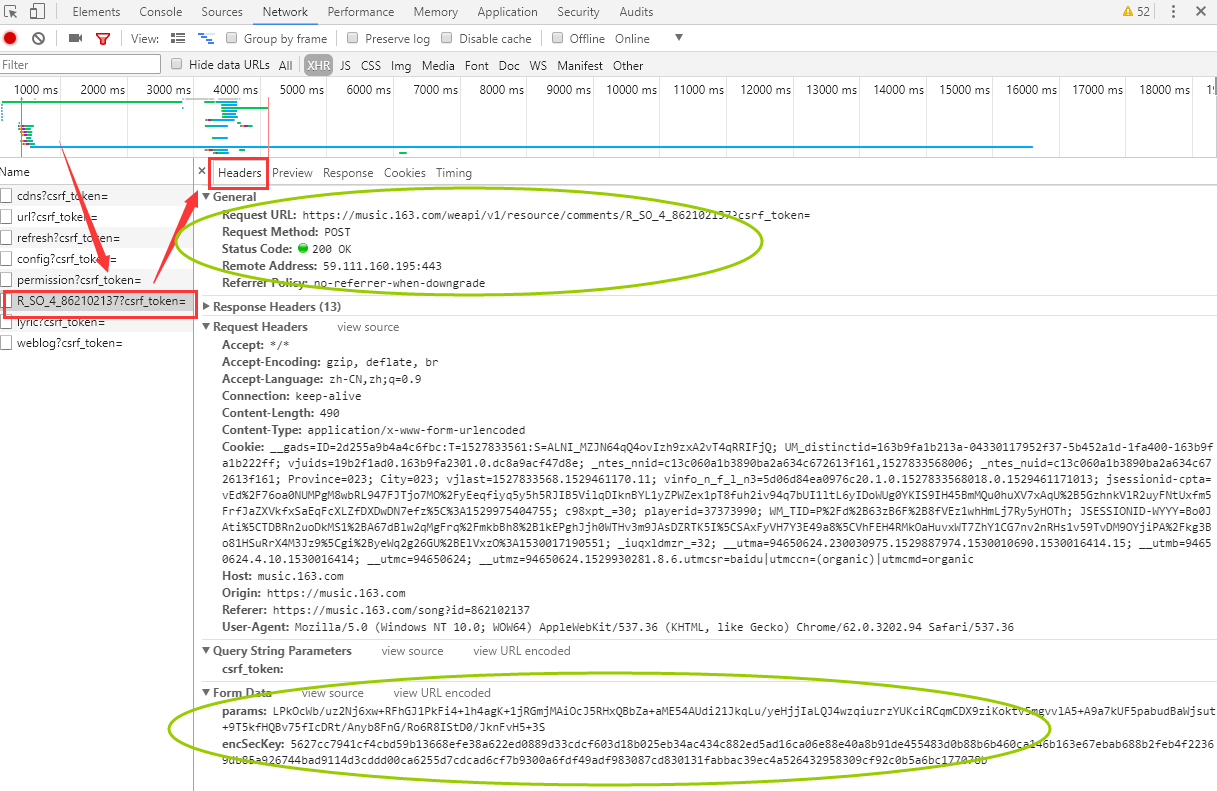
如下图所示,即为热评内容,获取页面内容,然后解析content即可,解析步骤继续向下看。
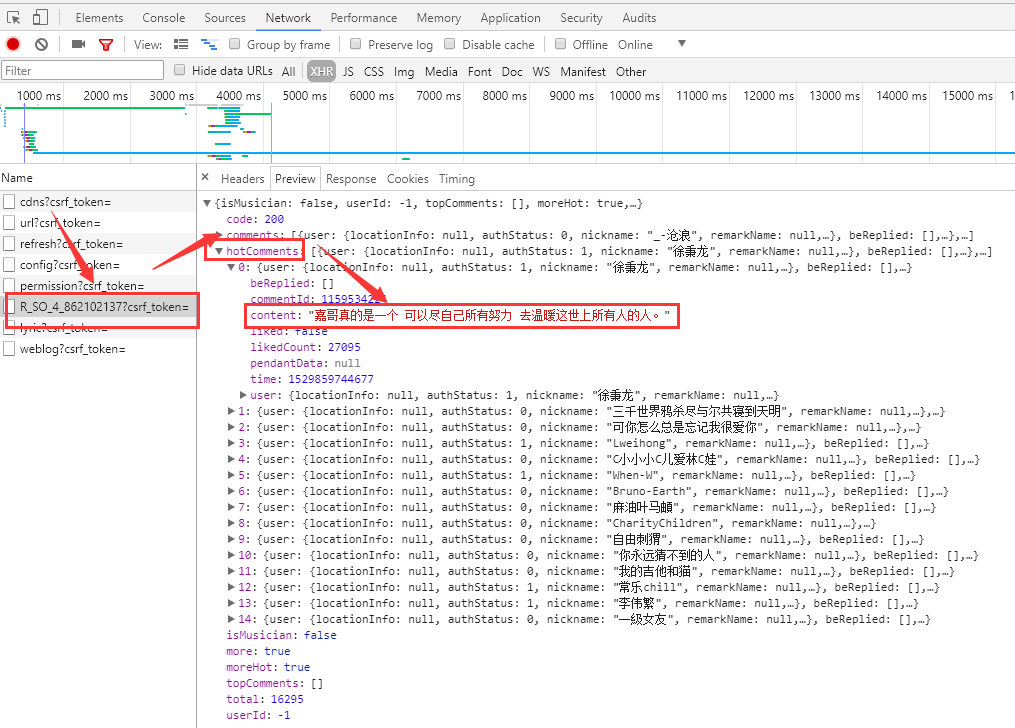
2、获取加密的参数 params 和 encSecKey
参考链接:https://www.zhihu.com/question/36081767
3、爬取网易云音乐评论及相关信息(代码有冗余)
(1)使用User Agent和代理IP隐藏身份之为何要设置User Agent
参考链接:https://blog.csdn.net/c406495762/article/details/60137956
agents = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
import random
# 爬取多首歌评时可以每次随机选取一个User Agent
header = {'User-Agent': ''.join(random.sample(agents, 1))}
# random.sample() 的值是列表, ''.join()转列表为字符串
print(header)(2)爬取指定一首歌的热评
注意:分析页面发现,热评只在每一首歌的首页,有15条。
参考链接:https://blog.csdn.net/fengxinlinux/article/details/77950209
代码说明:代码中的url和data参数值在上面的图中圈出的部分复制。
# -*-coding:utf-8-*-
"""
爬取网易云音乐指定歌曲的15条热评,
2018年6月26日
"""
import urllib.request
import urllib.error
import urllib.parse
import json
# 抓取网易云音乐指定url的热评
def get_hotComments():
url = 'https://music.163.com/weapi/v1/resource/comments/R_SO_4_862102137?csrf_token=' # 歌评url
header = {'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
# post请求表单数据
data = {'params':'LPkOcWb/uz2Nj6xw+RFhGJ1PkFi4+lh4agK+1jRGmjMAiOcJ5RHxQBbZa+aME54AUdi21JkqLu/yeHjjIaLQJ4wzqiuzrzYUKciRCqmCDX9ziKoktv5mgvvlA5+A9a7kUF5pabudBaWjsut+9T5kfHQBv75fIcDRt/Anyb8FnG/Ro6R8IStD0/JknFvH5+3S',
'encSecKey':'5627cc7941cf4cbd59b13668efe38a622ed0889d33cdcf603d18b025eb34ac434c882ed5ad16ca06e88e40a8b91de455483d0b88b6b460ca146b163e67ebab688b2feb4f22369db85a926744bad9114d3cddd00ca6255d7cdcad6cf7b9300a6fdf49adf983087cd830131fabbac39ec4a526432958309cf92c0b5a6bc177078b'}
postdata = urllib.parse.urlencode(data).encode('utf8') # 进行编码
request = urllib.request.Request(url, headers=header, data=postdata)
response = urllib.request.urlopen(request).read().decode('utf8')
json_dict = json.loads(response) # 获取json
hot_comment = json_dict['hotComments'] # 获取json中的热门评论
num = 1
for item in hot_comment:
print('第%d条评论:' % num + item['content'])
num += 1
if __name__ == '__main__':
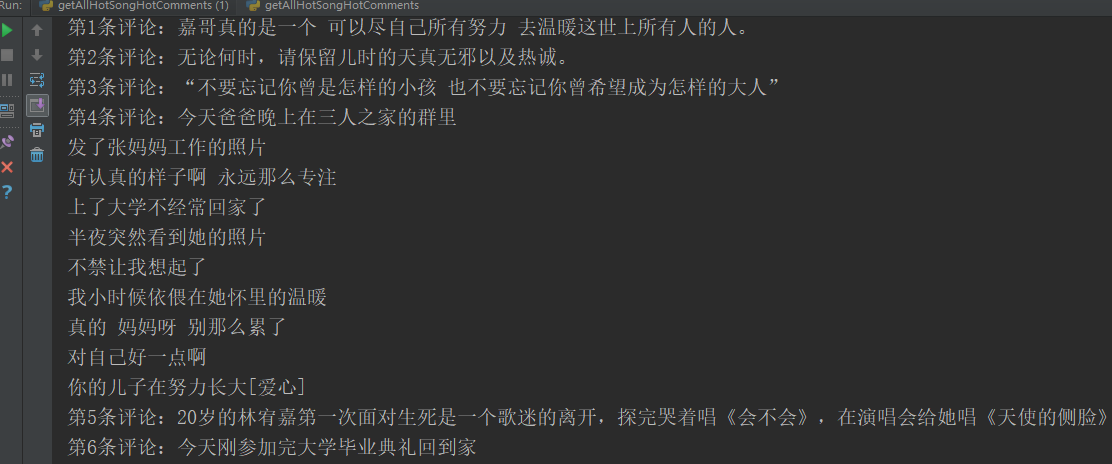
get_hotComments()代码输出,如下图:有完整15条数据,截图范围有限,显示6条。
(3)爬取网易云音乐199首热歌榜每首歌的评论数据
分析问题 ,要获取一首歌曲的页面,
参考链接:
获取歌曲名和歌曲id https://blog.csdn.net/fengxinlinux/article/details/77950209
获取一首歌所有页面的评论数据 https://www.cnblogs.com/weixuqin/p/8905867.html
代码说明1:如果导入from Crypto.Cipher import AES提示错误No module named Crypto.Cipher,请参考文章
https://blog.csdn.net/qiang12qiang12/article/details/80805016
当页面评论不足指定页面的数量时,代码可以选择跳过或者break
# -*- coding:utf-8 -*-
"""
爬取网易云音乐热歌榜的最新评论,指定页数的所有评论,比如前10页
2018年6月26日
"""
import os
import re
import random
import urllib.request
import urllib.error
import urllib.parse
from Crypto.Cipher import AES
import base64
import requests
import json
import time
agents = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
headers = {
'Host':'music.163.com',
'Origin':'https://music.163.com',
'Referer':'https://music.163.com/song?id=28793052',
'User-Agent':''.join(random.sample(agents, 1))
}
# 除了第一个参数,其他参数为固定参数,可以直接套用
# offset的取值为:(评论页数-1)*20,total第一页为true,其余页为false
# 第一个参数
# first_param = '{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}'
# 第二个参数
second_param = "010001"
# 第三个参数
third_param = "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
# 第四个参数
forth_param = "0CoJUm6Qyw8W8jud"
# 获取参数
def get_params(page): # page为传入页数
iv = "0102030405060708"
first_key = forth_param
second_key = 16 * 'F'
if(page == 1): # 如果为第一页
first_param = '{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}'
h_encText = AES_encrypt(first_param, first_key, iv)
else:
offset = str((page-1)*20)
first_param = '{rid:"", offset:"%s", total:"%s", limit:"20", csrf_token:""}' % (offset,'false')
h_encText = AES_encrypt(first_param, first_key, iv)
h_encText = AES_encrypt(h_encText, second_key, iv)
return h_encText
# 获取 encSecKey
def get_encSecKey():
encSecKey = "257348aecb5e556c066de214e531faadd1c55d814f9be95fd06d6bff9f4c7a41f831f6394d5a3fd2e3881736d94a02ca919d952872e7d0a50ebfa1769a7a62d512f5f1ca21aec60bc3819a9c3ffca5eca9a0dba6d6f7249b06f5965ecfff3695b54e1c28f3f624750ed39e7de08fc8493242e26dbc4484a01c76f739e135637c"
return encSecKey
# 解密过程
def AES_encrypt(text, key, iv):
pad = 16 - len(text) % 16
text = text + pad * chr(pad)
encryptor = AES.new(key, AES.MODE_CBC, iv)
encrypt_text = encryptor.encrypt(text)
encrypt_text = base64.b64encode(encrypt_text)
encrypt_text = str(encrypt_text, encoding="utf-8") # 注意一定要加上这一句,没有这一句则出现错误
return encrypt_text
# 获得评论json数据
def get_json(url, params, encSecKey):
data = {
"params": params,
"encSecKey": encSecKey
}
response = requests.post(url, headers=headers, data=data)
return response.content.decode('utf-8') # 解码
# 获取热歌榜所有歌曲名称和id
def get_all_hotSong():
url = 'http://music.163.com/discover/toplist?id=3778678' # 网易云云音乐热歌榜url
header = {'User-Agent': ''.join(random.sample(agents, 1))} # random.sample() 的值是列表, ''.join()转列表为字符串
request = urllib.request.Request(url=url, headers=header)
html = urllib.request.urlopen(request).read().decode('utf8') # 打开url
html = str(html) # 转换成str
# print(html)
pat1 = r'<ul class="f-hide"><li><a href="/song\?id=\d*?">.*</a></li></ul>' # 进行第一次筛选的正则表达式
result = re.compile(pat1).findall(html) # 用正则表达式进行筛选
# print(result)
result = result[0] # 获取tuple的第一个元素
pat2 = r'<li><a href="/song\?id=\d*?">(.*?)</a></li>' # 进行歌名筛选的正则表达式
pat3 = r'<li><a href="/song\?id=(\d*?)">.*?</a></li>' # 进行歌ID筛选的正则表达式
hot_song_name = re.compile(pat2).findall(result) # 获取所有热门歌曲名称
hot_song_id = re.compile(pat3).findall(result) # 获取所有热门歌曲对应的Id
# print(hot_song_name)
# print(hot_song_id)
return hot_song_name, hot_song_id
# 抓取某一首歌的前page页评论
def get_all_comments(hot_song_id, page, hot_song_name, hot_song_order): # hot_song_order为了给文件命名添加一个编号
all_comments_list = [] # 存放所有评论
url = 'http://music.163.com/weapi/v1/resource/comments/R_SO_4_' + hot_song_id + '?csrf_token=' # 歌评url
dir = os.getcwd() + '\\Comments\\'
if not os.path.exists(dir): # 判断当前路径是否存在,没有则创建new文件夹
os.makedirs(dir)
num = 0
f = open(dir + str(hot_song_order) + ' ' + hot_song_name + '.txt', 'w', encoding='utf-8')
# ' '是为了防止文件名也是数字混合,加个空格分隔符,写入文件, a 追加
for i in range(page): # 逐页抓取
# print(url, i)
params = get_params(i+1)
encSecKey = get_encSecKey()
json_text = get_json(url, params, encSecKey)
# print(json_text)
json_dict = json.loads(json_text)
for item in json_dict['comments']:
comment = item['content'] # 评论内容
num += 1
f.write(str(num) + '.' + comment + '\n')
comment_info = str(comment)
all_comments_list.append(comment_info)
print('第%d首歌的%d页抓取完毕!' % (hot_song_order, i+1))
# time.sleep(random.choice(range(1, 3))) # 爬取过快的话,设置休眠时间,跑慢点,减轻服务器负担
f.close()
# print(all_comments_list)
# print(len(all_comments_list))
return all_comments_list
if __name__ == '__main__':
start_time = time.time() # 开始时间
hot_song_name, hot_song_id = get_all_hotSong()
num = 0
while num < len(hot_song_name): # 保存所有热歌榜中的热评
print('正在抓取第%d首歌曲热评...' % (num+1))
# 热门歌曲评论很多,每首爬取最新的10页评论
get_all_comments(hot_song_id[num], 10, hot_song_name[num], num+1)
print('第%d首歌曲热评抓取成功' % (num+1))
num += 1
end_time = time.time() # 结束时间
print('程序耗时%f秒.' % (end_time - start_time))
代码说明2:当页面评论不足指定页面的数量时,代码可以选择break或者继续爬空,break代码如下(替换上面的函数即可):
def get_all_comments(url, page):
all_comments_list = [] # 存放所有评论
num = 0
f = open('TTTTTTTTTTTest.txt', 'a', encoding='utf-8') # 写入文件
for i in range(page): # 逐页抓取
print(url, i)
params = get_params(i+1)
encSecKey = get_encSecKey()
json_text = get_json(url, params, encSecKey)
# print(json_text)
json_dict = json.loads(json_text)
onePageComments = [] # 判断评论最后一页,如果评论数为0,则结束爬取
for item in json_dict['comments']:
comment = item['content'] # 评论内容
onePageComments.append(comment)
num += 1
f.write(str(num) + '.' + comment + '\n')
comment_info = str(comment)
all_comments_list.append(comment_info)
if len(onePageComments) == 0:
break
print("本页评论数量", len(onePageComments))
print('第%d页抓取完毕!' % (i+1))
# time.sleep(random.choice(range(1, 3))) # 爬取过快的话,设置休眠时间,跑慢点,减轻服务器负担
f.close()
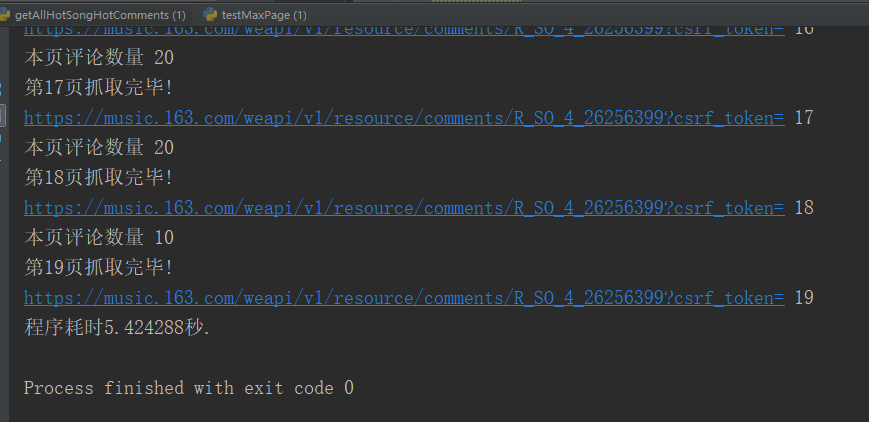
return all_comments_list比如,设置爬取页数为50页,而爬取的评论只有19页时,爬完19页即终止。
(4)爬取网易云音乐每首歌的其他数据
包括,评论总数,评论发布者昵称、头像、ID等等,可以根据自己需要解析页面获取。
def get_all_comments(url, page):
all_comments_list = [] # 存放所有评论
num = 0
f = open('Test.txt', 'w', encoding='utf-8') # 写入文件
for i in range(page): # 逐页抓取
print(url, i)
params = get_params(i+1)
encSecKey = get_encSecKey()
json_text = get_json(url, params, encSecKey)
# print(json_text)
json_dict = json.loads(json_text)
print("热评总数:", json_dict["total"]) # 热评总数
for item in json_dict['hotComments']:
comment = item['content'] # 评论内容
print("用户信息:", item['user'])
# 评论发布者昵称、头像、ID
nickname = item['user']['nickname']
avatarUrl = item['user']['avatarUrl']
userId = item['user']['userId']
urllib.request.urlretrieve(avatarUrl, "headPortrait\\" + str(userId) + '.jpg') # 存放头像
# 根据爬取的头像链接下载头像到本地
num += 1
f.write(str(num) + '.' + comment + '\n')
comment_info = str(comment)
all_comments_list.append(comment_info)
print('第%d页抓取完毕!' % (i+1))
# time.sleep(random.choice(range(1, 3))) # 爬取过快的话,设置休眠时间,跑慢点,减轻服务器负担
f.close()
return all_comments_list比如,获取第一页用户信息。

本文来自博客园,作者:风兮177,转载请注明原文链接:https://www.cnblogs.com/fengxi177/p/16939382.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号