python学习Day28--模块划分+hashlib模块+configparse模块+logging模块+异常处理
【知识点】
常用模块一:
collection模块(★★★)
时间模块(★★★★)
random模块(★★★★★)
os模块(★★★★★)
sys模块 sys.path sys.modules sys.argv
序列化模块 json/pickle (★★★★★)
re模块(★★★★★)
常用模块二:
hashlib模块 (★★★★★)
configaparse模块 (★)处理配置文件的模块
logging模块 (★★★★★)
1、hashlib模块
能够把一个 字符串 数据类型的变量转换成一个 定长的 密文的 字符串,字符串里的每一个字符都是一个十六进制数字
(1)md5算法:得到一个32位的字符串,每一个字符都是一个十六进制
1 import hashlib 2 3 s='alex3714' 4 md5_obj=hashlib.md5() 5 md5_obj.update(s.encode('utf-8')) 6 res=md5_obj.hexdigest() 7 print(res,len(res),type(res)) 8 # aee949757a2e698417463d47acac93df 32 <class 'str'>
优点:效率快,算法相对简单一些,普及广
① md5——加盐(加强安全性)
1 import hashlib 2 3 s='alex3714' 4 md5_obj=hashlib.md5('任意的字符作为加盐'.encode('utf-8')) 5 md5_obj.update(s.encode('utf-8')) 6 res=md5_obj.hexdigest() 7 print(res,len(res),type(res)) 8 # 889df903fec61e567bf4367f910a94df 32 <class 'str'>
② md5——动态加盐
1 # md5——动态加盐 2 import hashlib 3 4 username=input('请输入用户名:') 5 passwd=input('请输入密码:') 6 md5_obj=hashlib.md5(username.encode('utf-8')) 7 md5_obj.update(passwd.encode('utf-8')) 8 print(md5_obj.hexdigest()) #38cd69698411cb1de19240d88cc66a51
(2)sha1算法:得到40位的字符串,每一个字符都是一个十六进制(也可以加盐)
1 import hashlib 2 3 s='alex3714' 4 md5_obj=hashlib.sha1() 5 md5_obj.update(s.encode('utf-8')) 6 res=md5_obj.hexdigest() 7 print(res,len(res),type(res)) 8 # 8a003668a9c990f15148f9e4046e1410781533b6 40 <class 'str'>
优点:安全性高 缺点:算法相对复杂,计算速度慢
(3)文件的一致性校验
1 # 文件的一致性检验 2 import hashlib 3 4 # md5_obj=hashlib.md5() 5 # with open ('5.序列化模块_shelve.py','rb') as f: 6 # md5_obj.update(f.read()) 7 # ret1=md5_obj.hexdigest() 8 # 9 # md5_obj=hashlib.md5() 10 # with open ('5.序列化模块_shelve.py','rb') as f: 11 # md5_obj.update(f.read()) 12 # ret2=md5_obj.hexdigest() 13 # 14 # print(ret1,ret2) 15 16 # 如果这个文件特别大,内存装不下(大文件的一致性校验) 17 # 按字节读 18 md5_obj=hashlib.md5() 19 md5_obj.update('hello,alex,sb'.encode('utf-8')) 20 print(md5_obj.hexdigest()) # 6557c9e1d6fc95bf2b12e36c09e13c46 21 22 md5_obj=hashlib.md5() 23 md5_obj.update('hello,'.encode('utf-8')) # 注意逗号 24 md5_obj.update('alex,'.encode('utf-8')) # 注意逗号 25 md5_obj.update('sb'.encode('utf-8')) 26 print(md5_obj.hexdigest()) #6557c9e1d6fc95bf2b12e36c09e13c46
2、configaparser模块
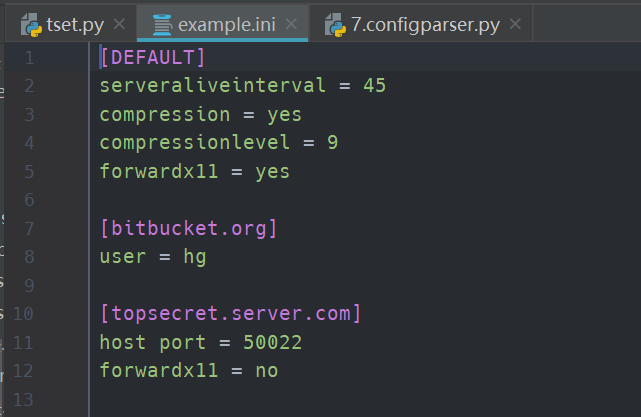
1 import configparser 2 3 config = configparser.ConfigParser() 4 5 config["DEFAULT"] = {'ServerAliveInterval': '45', 6 'Compression': 'yes', 7 'CompressionLevel': '9', 8 'ForwardX11':'yes' 9 } 10 11 config['bitbucket.org'] = {'User':'hg'} 12 13 config['topsecret.server.com'] = {'Host Port':'50022','ForwardX11':'no'} 14 15 with open('example.ini', 'w') as f: 16 config.write(f)
生成的文件如下:
其他操作:
1 import configparser 2 3 config = configparser.ConfigParser() 4 # print(config.sections()) # [] 5 config.read('example.ini') 6 # print(config.sections()) # ['bitbucket.org', 'topsecret.server.com'] 7 # print('bytebong.com' in config) # False 8 # print('bitbucket.org' in config) # True 9 # print(config['bitbucket.org']["user"]) # hg 10 # print(config['DEFAULT']['Compression']) #yes 11 # print(config['topsecret.server.com']['ForwardX11']) #no 12 # print(config['bitbucket.org']) #<Section: bitbucket.org> 13 # for key in config['bitbucket.org']: # 注意,有default会默认default的键 14 # print(key) 15 # print(config.options('bitbucket.org')) # 同for循环,找到'bitbucket.org'下所有键 16 # print(config.items('bitbucket.org')) #找到'bitbucket.org'下所有键值对 17 # print(config.get('bitbucket.org','compression')) # yes get方法Section下的key对应的value
3、logging模块
(1)功能:
① 日志格式的规范
② 操作的简化
③ 日志的分级管理
(2)logging不能帮你做的事情
① 自动生成你要打印的内容,需要程序员吧在开发的时候定义好:在哪些地方打印,打印什么内容,内容的级别。
(3)logging模块的使用:
① 普通配置型:简单的 可定制化差
② 对象配置型:复杂的 可定制化强
(4)认识日志的分级
1 # 认识logging的分级 2 import logging 3 4 logging.basicConfig(level=logging.DEBUG) # 加入这个下面的debug,info就会显示 5 logging.debug('debug message') # 调试模式 6 logging.info('info message') # 基础信息模块 7 logging.warning('warning message') # 警告 8 logging.error('error message') # 错误 9 logging.critical('critical message') # 严重错误
(5)日志的参数使用
1 # 参数配置 2 import logging 3 4 logging.basicConfig(level=logging.DEBUG, 5 format='%s(asctime)s %(filname)s[line:%(lineno)d] %(levelnames) %(message)s', 6 datefmt='%a,%d %b %Y %H:%M:%S', 7 filename='test.log') 8 logging.debug('debug message') # 调试模式 9 logging.info('info message') # 基础信息模块 10 logging.warning('warning message') # 警告 11 logging.error('error message') # 错误 12 logging.critical('critical message') # 严重错误
(6)logging进阶设置(既可以在屏幕显示,也可以在文件里显示)
1 #*****第一步******* 2 # 创建一个logger对象 3 # 创建一个文件管理操作符 4 # 创建一个屏幕管理操作符 5 # 创建一个日志输出格式 6 7 #*****第二步******* 8 # 文件管理操作符 绑定一个 格式 9 # 屏幕管理操作符 绑定一个 格式 10 11 #*****第三步******* 12 # 将logger对象 绑定 文件管理操作符 13 # 将logger对象 绑定 屏幕管理操作符 14 15 # 第一步 16 import logging 17 18 # 创建一个logger对象 19 logger=logging.getLogger() 20 # 创建一个文件管理操作符 21 fh=logging.FileHandler('logger.log1',encoding='utf-8') 22 # 创建一个屏幕管理操作符 23 sh=logging.StreamHandler() 24 # 创建一个日志输出格式 25 format1=logging.Formatter('%s(asctime)s - %(name)s - %(levelname)s - %(message)s') 26 27 # 第二步 28 # 文件管理操作符 绑定一个 格式 29 fh.setFormatter(format1) 30 logger.setLevel(logging.DEBUG) 31 # 屏幕管理操作符 绑定一个 格式 32 sh.setFormatter(format1) 33 34 # 第三步 35 # 将logger对象 绑定 文件管理操作符 36 logger.addHandler(fh) 37 # 将logger对象 绑定 屏幕管理操作符 38 logger.addHandler(sh) 39 40 logger.debug('debug message') # 调试模式 41 logger.info('info message') # 基础信息模块 42 logger.warning('warning message') # 警告 43 logger.error('error message') # 错误 44 logger.critical('critical message') # 严重错误
4、异常处理
# 什么是异常?异常和错误的区别?
① Error 错误 比较明显的错误 在编译代码阶段就能检测出来
② Iteration 异常 在执行代码的过程中引发的异常
# 异常之后发生的效果:一旦在程序中发生异常,程序就不再继续执行了
# 如何看报错信息?
Traceback——错误的追踪信息; 错误类(有限)——IndexError等;错误提示。
(1)万能异常
1 # 万能异常 2 try: 3 name 4 dic={} 5 dic['key'] 6 except Exception as e: # e——错误对象 7 print(type(e),e,e.__traceback__.tb_lineno)
(2)万能异常与其他分支合作:万能异常要放在所有except的最后
1 # 万能异常和其他分支合作:万能异常要放在所有except的最后 2 try: 3 name 4 dic={} 5 dic['key'] 6 7 except NameError:pass 8 except IndexError:pass 9 except Exception as e: # e——错误对象 10 print(type(e),e,e.__traceback__.tb_lineno)
(3)其他机制
元组写法:
1 try: 2 name 3 dic={} 4 dic['key'] 5 6 except (NameError,IndexError): # 写法一 7 print('error') 8 9 except (NameError,IndexError) as e: # 写法二 10 print(type(e),e,e.__traceback__.tb_lineno)
else与finally:
1 try: 2 pass 3 except NameError: 4 print('name error') 5 else: # try中代码正常执行,没有异常的时候会执行else中的代码 6 print('执行了else了') 7 finally: # 无论如何都会执行(关闭文件) 8 print('执行finally了')
raise主动抛异常:
1 # 主动抛异常 2 try: 3 num=int(input('>>>')) 4 except Exception: 5 print('在出现了异常之后做点什么,再让它抛异常') 6 raise NameError # 主动抛出一个异常
自定义异常:
1 # 自定义异常 2 class FxbError(Exception): # 继承Exception 3 def __init__(self,msg): 4 self.msg=msg 5 6 raise FxbError('这是一个XXX错误,有xxx问题')
(4)断言 assert
1 # 断言 2 assert 1==1 # assert 布尔值 3 # True就往下执行,False就报错
5、collections模块
数据类型的拓展模块
# 什么是队列?先进先出
1 # deque 双端队列 2 from collections import deque 3 # 最先放进去的在中间 4 dq=deque() 5 dq.append(2) 6 dq.append(5) 7 dq.appendleft('a') 8 dq.appendleft('b') 9 print(dq) # deque(['b', 'a', 2, 5]) 10 print(dq.pop()) # 5 # pop返回右端的 11 print(dq) # deque(['b', 'a', 2]) 12 print(dq.popleft()) # b 13 dq.insert(0,'111') 14 print(dq) # deque(['111', 'a', 2])
【总结】:
在insert remove的时候,deque否认平均效率要高于列表
列表根据索引查看某个的值的要高于deque
append和pop对于列表的效率是没有影响的
时间:2020-02-24 14:21:18

 浙公网安备 33010602011771号
浙公网安备 33010602011771号