python学习Day23--析构+item系列+hash、eq方法+模块前奏
【知识点】
构造方法:申请一个空间
析构方法:释放一个空间
1、__del__ 析构方法 是去归还/释放一些在创建对象的时候借用的一些资源
# 什么时候执行?
# del 对象的时候
# python解释器的垃圾回收机制 回收这个对象所占的内存的时候
2、item系列 和对象使用[ ]访问值有联系
(1)__getitem__()、__setitem__()和__delitem__()


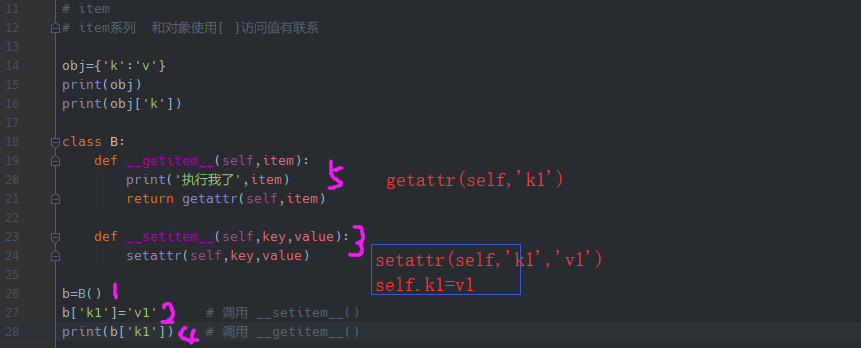
1 # item 2 # item系列 和对象使用[ ]访问值有联系 3 4 obj={'k':'v'} 5 print(obj) 6 print(obj['k']) 7 8 class B: 9 def __getitem__(self,item): 10 print('执行我了',item) 11 return getattr(self,item) 12 13 def __setitem__(self,key,value): 14 setattr(self,key,value) 15 16 def __delitem__(self,key): 17 delattr(self,key) 18 19 b=B() 20 b['k1']='v1' # 调用 __setitem__() 21 print(b['k1']) # 调用 __getitem__() 22 del b['k1'] # 调用 __delitem__()
# 在列表里使用:
1 class B: 2 def __init__(self,lst): 3 self.lst=lst 4 def __getitem__(self,item): 5 return self.lst[item] 6 7 def __setitem__(self,key,value): 8 self.lst[key]=value 9 10 def __delitem__(self,key): 11 self.lst.pop(key) 12 13 b=B(['111','222','333','444']) 14 print(b.lst[0]) # 111 执行__init__() 15 print(b[0]) # 111 调用__getitem__() 16 b[3]='aaa' # 调用 __setitem__() 17 print(b[3]) # aaa 调用__getitem__() 18 del b[2] # 调用 __delitem__() 19 print(b.lst) # ['111', '222', 'aaa']
3、hash方法
# 底层数据结构基于hash值寻址的优化操作
# hash是一个算法 能够把某一个要存在内存里的值通过一系列计算,保证不同的值的hash结果不一样
# 对同一个值在多次执行python代码的时候hash值是不同的,但是对同一个值在同一次执行python代码的时候hash值永远不变
# hash(obj) obj内部必须实现了__hash__方法
4、__eq__方法
# ==这个语法 是完全和__eq__相关
1 class A: 2 def __init__(self,name,age): 3 self.name=name 4 self.age=age 5 6 def __eq__(self,other): 7 if self.name==other.name and self.age==other.age: 8 return True 9 a=A('alex',45) 10 aa=A('alex',45) 11 aaa=A('alex',45) 12 print(a==aa) # True 13 print(a==aa==aaa) # True ==这个语法 是完全和__eq__相关
【一道面试题】
# 一个类
# 对象的属性:姓名 性别 年龄
# 员工管理系统
# 内部转岗 : python开发 --> go开发
# 1000个员工,如果几个员工对象的姓名和性别相同,这是一个人(去重)
# 请对这1000个员工去重
1 # 一道面试题 2 class Employee: 3 def __init__(self,name,age,sex,partment): 4 self.name=name 5 self.age=age 6 self.sex=sex 7 self.partment=partment 8 9 def __hash__(self): # 自己定制hsah 10 return hash('%s%s' % (self.name,self.sex)) 11 12 def __eq__(self,other): # 自己定制eq 13 if self.name==other.name and self.sex==other.sex: 14 return True 15 16 employ_lst=[] 17 for i in range(200): 18 employ_lst.append(Employee('alex',i,'male','python')) 19 for i in range(200): 20 employ_lst.append(Employee('wusir', i, 'male', 'python')) 21 for i in range(200): 22 employ_lst.append(Employee('taibai', i, 'male', 'python')) 23 employ_set=set(employ_lst) # set集合的内容是可哈希的,会触发__hash__ 24 for el in employ_set: 25 print(el.__dict__) 26 # set集合去重机制:先调用hash,再调用eq。eq不是每次都触发,只有hash值相等的时候
【set去重机制】
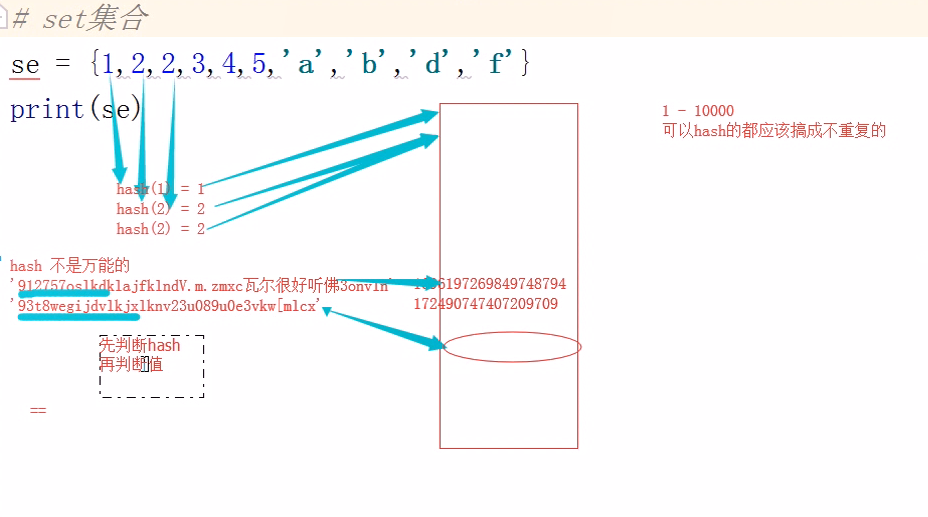
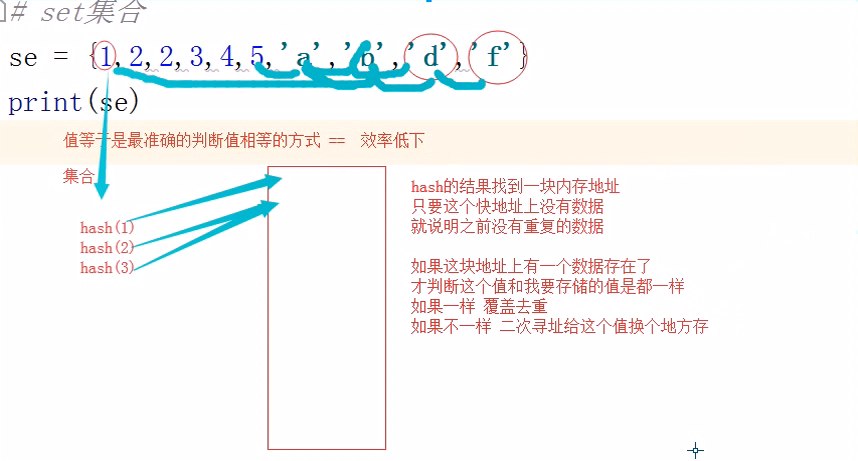
5、初始模块
(1)模块的分类:
内置模块:安装python解释器的时候跟着装上的那些方法
自定义模块:你写的功能如果是一个通用的功能,那你就把它当成一个模块
第三方模块/拓展模块:没在安装python解释器的时候安装的那些功能(site-packages文件)
# 什么是模块?
# 有的功能开发者自己无法完成,这样的话需要借助已经实现的函数/类来完成这些功能
# 你实现不了的功能都由别人替你实现了
# 别人写好的一组功能 文件夹/py文件/C语言编译好的一些编译文件
# 模块的好处:①分类 管理方法;②节省内存;③提供更多的功能
# 为什么要有模块?
# 模块怎么用?在哪儿用?
(2)模块的导入和使用
import 模块名 一个模块不会被重复导入
模块的使用:模块名.方法名 模块名.变量
1 # 模块 2 import my_module 3 4 # 如何使用模块? 5 def login(): 6 print("in my login") 7 login() # in my login 8 my_module.login() # 这是一个登录函数 alex 9 print(my_module.name) # alex
【导入一个模块的过程中发生了哪些事情?】

(4)模块的重命名
import my_module as m 重新命名为m
(5)导入多个模块
1 import os 2 import sys 3 import my_module
【注意】
① 所有的模块导入都应该尽量放在文件的开头
② 模块的导入也是有顺序的:先导入内置模块,再导入第三方模块,最后导入自定义模块
时间:2020-02-16 18:18:06

 浙公网安备 33010602011771号
浙公网安备 33010602011771号