
双线性模型(六)(CrossE、RotatE、TuckER)
这是最后一篇记录双线性模型的博文,记录放假前草草看了的、做了屎一样笔记的、而今全部忘了paper在讲啥的 CrossE、RotatE、TuckER。
CrossE
【paper】 Interaction Embeddings for Prediction and Explanation in Knowledge Graphs
【简介】 本文是浙大和苏黎世大学的学者联合发表于 WSDM 2019 上的工作,文章提出了 CrossE,模型的思想也没有很高端,就是引入了一个矩阵C,用于计算实体和关系 crossover interaction,然后挖掘出可靠路径用于为链接预测提供解释。本文的重点有两个,一个是建模了 crossover interaction,另一个是对链接预测进行了 explanation。
问题定义
crossover interaction
crossover interaction 指的是实体和关系的双向(bi-directional)影响,包括从关系到实体的交互和从实体到关系的交互。
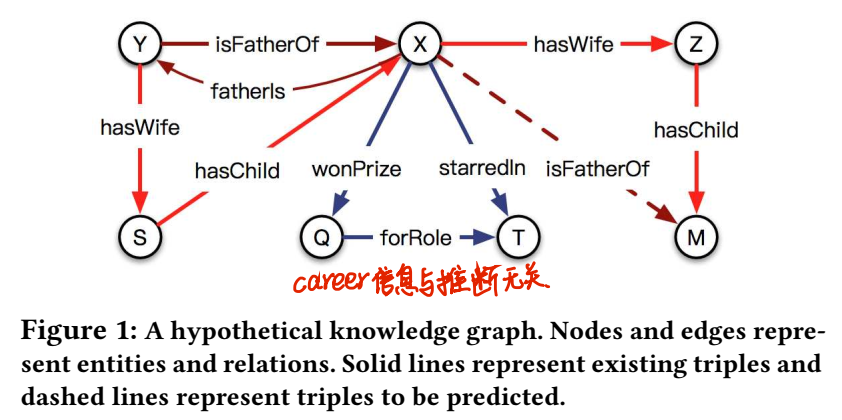
文章举了个栗子,为了说明关系(isFatherOf)影响了 information of entities to be chosen for inference,这是从关系到实体的交互;同样,实体信息也影响关系推断路径。
给定三元组(h,r,t),crossE分四步:
1.对头实体 h 生成 interaction embedding \(h_I\);
2.对关系 r 生成 interaction embedding \(r_I\);
3.组合上面二者的 interaction embedding \(h_I\) 和 \(r_I\);
4.比较组合 embedding 和尾实体 t 的相似性。
link prediction explanation
给出链接预测的解释,就是找出从头实体到尾实体的合理路径和相似结构以支持路径解释。
评价指标有:1.Recall;2.Average Support。
CrossE 模型
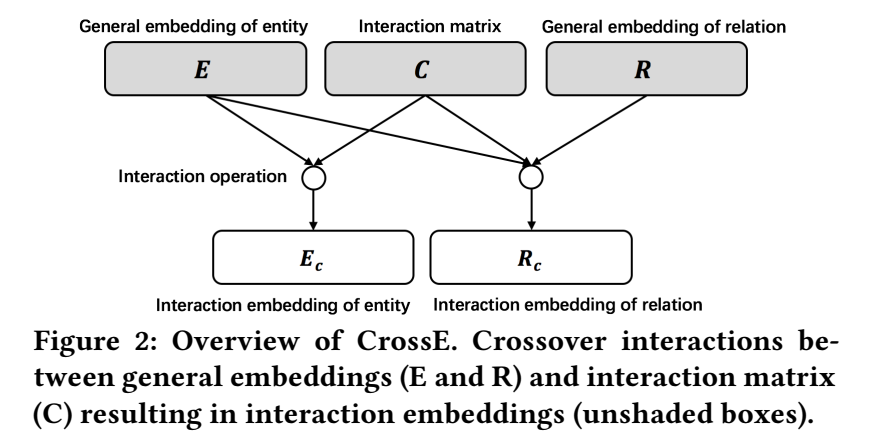
首先通过 one-hot 向量查表找到头尾实体和关系的 general embedding:
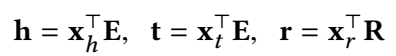
(1)头实体的 interaction embedding
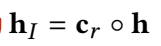
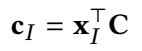
\(c_r\) depends on 关系 r。
(2)关系的 interaction embedding
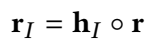
头实体的interaction embedding 与 r 做 Hadamard 积得到 r 的 interaction embedding。
(3)头实体与关系组合
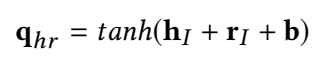
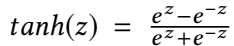
(4)相似性度量
上一步得到的头实体与关系的组合表示与尾实体进行相似性度量:
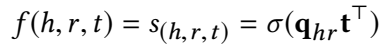
整体的三元组打分函数为:
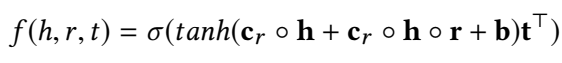
同时,为了对比 crossover interaction 的作用,文章还给出了没有 interaction 的简化版本:
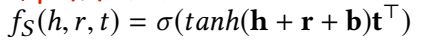
Loss Function 采用 log-likelihood 的损失函数:
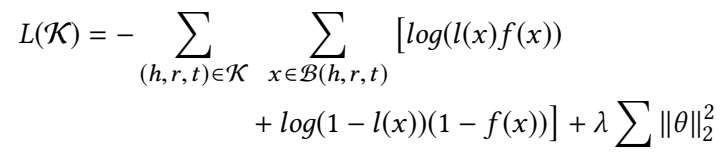
预测结果的解释
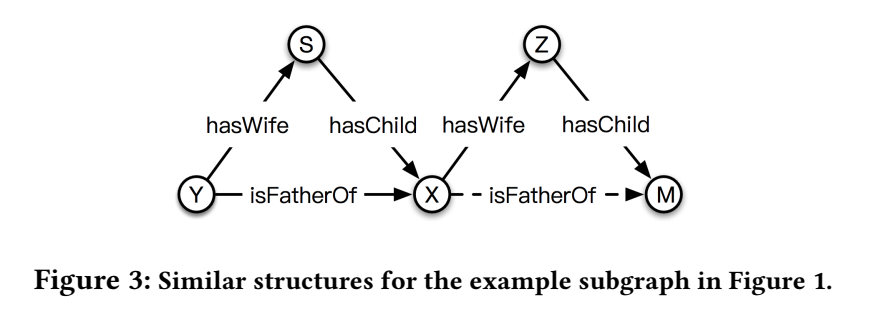
链接预测的解释,其实就是类比推理。对于预测出的三元组(X, isFatherOf, M),做出预测的原因有二:一是已有 premise (X, hasWife, Z) 和 (Z, hasChild, M);二是左侧的 similar structure,存在这两个 premise 的 S 和 X 之间存在 hasChild 的关系。和昨天看的四边形的 ANALOGY 类比推理是一回事。
进行 explanation search 有两步:
1.寻找从 h 到 t 的闭合路径;
2.寻找 similar structure 作为 support。
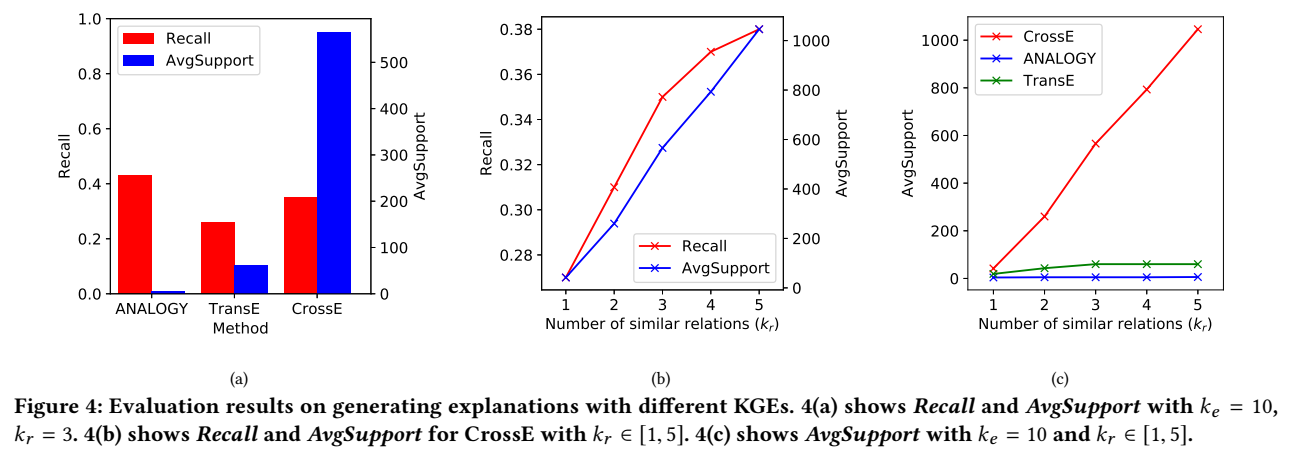
实验
链接预测正确率
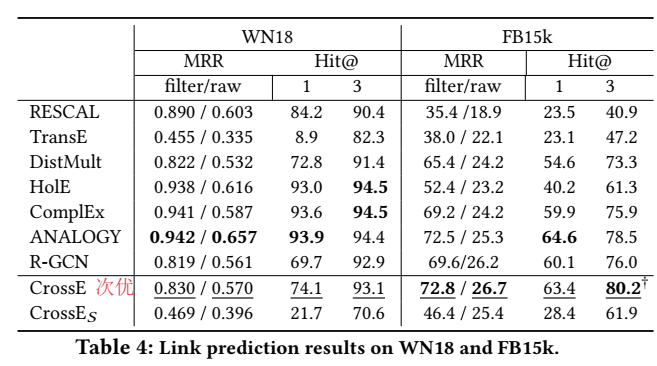
实验的效果根本就不是最优,不知道 introduction 里的 state-of-the-art 是怎么写出来的=.=|
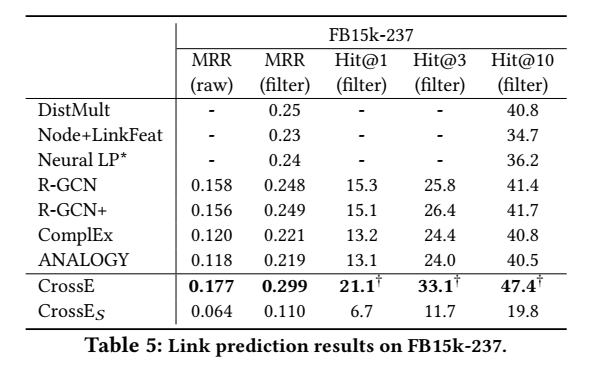
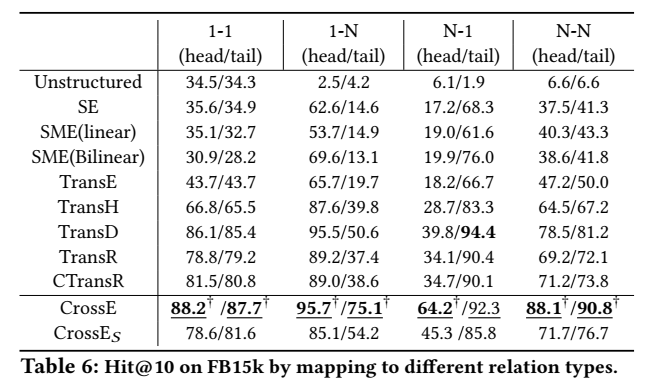
explanation
举例展示了挖掘出的六种类比推理结构类型:
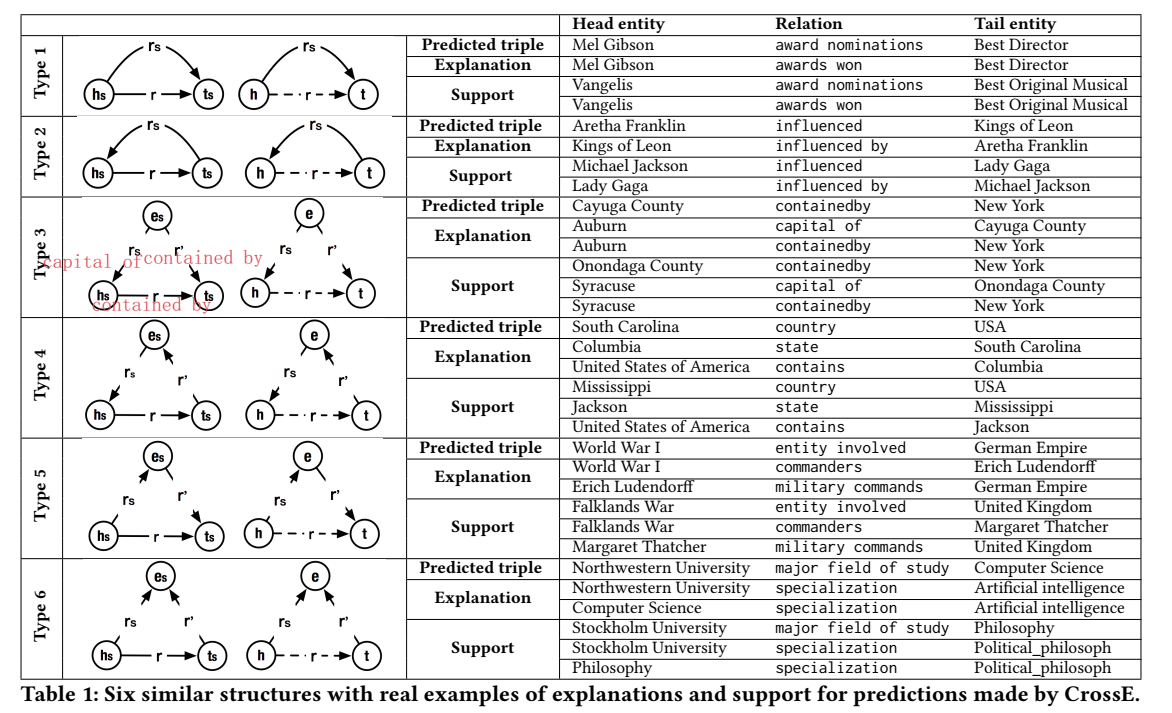
该模型没有给出代码。
【总结】 在这篇文章中学到/想到的一点是,如果方法/idea不是那么高端的话,可以通过多做实验另辟蹊径来弥补,如本文如果只做了 crossover interaction 的工作的话,就会显得单薄和鸡肋,但是因为加上了 explanation 这样一个工作重点,就会显得比较详实。
RotatE
【paper】 RotatE: Knowledge Graph Embedding by Relational Rotation in Complex Space
【简介】 本文是北大和加拿大的研究团队发表在 ICLR 2019 上的文章,提出了 RotatE(Rotation Embedding),主要思想是将实体表示为复向量,关系视为从头实体指向尾实体的旋转(Rotation)。这个模型大概是看明白了的,感觉还是比较巧妙的。
问题定义
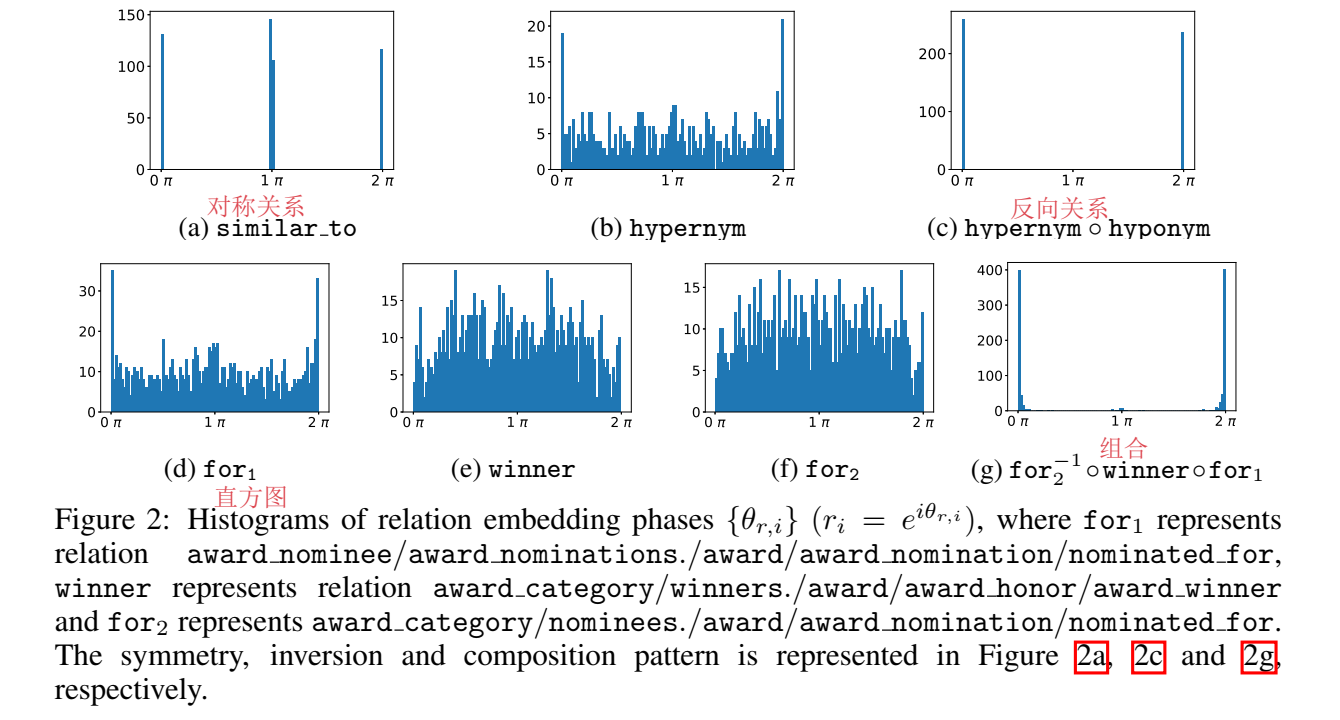
RotatE 的提出主要是为了建模三种关系:对称/非对称、反向关系、关系组合

这里的对称关系指的就是自反关系,inverse 是对两个关系来说的。TransE 可以建模 inverse 和 composition,无法表示 symmetry。
模型
RotatE 是复空间中的双线性模型,希望 truth triplet 满足:
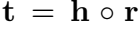
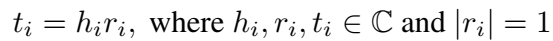
RotatE 巧妙地利用了欧拉公式,将关系视为从头实体向尾实体的旋转。

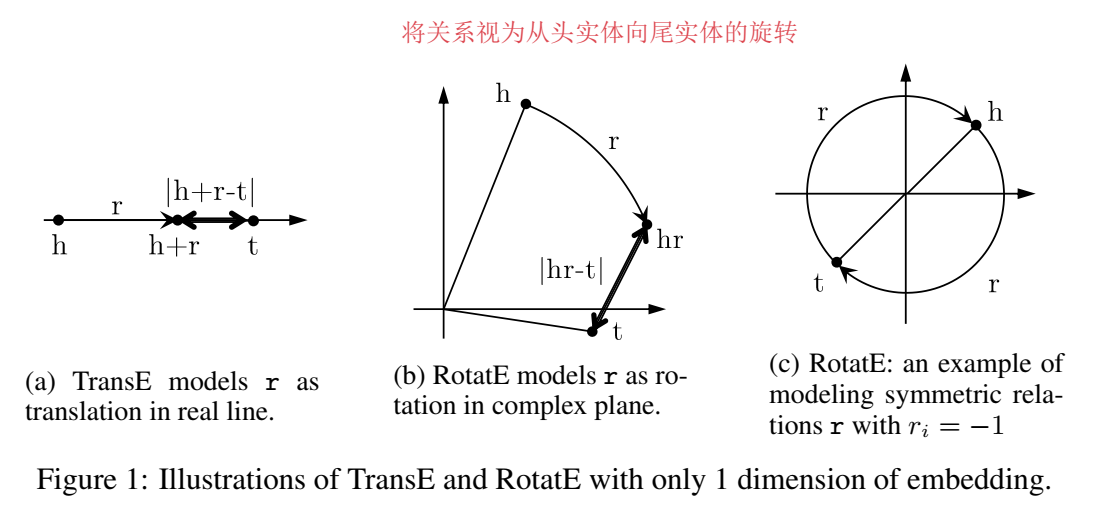
RotatE 的距离函数为:
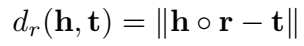
附录中还给出了为什么 RotatE 可以建模这三种关系的证明:
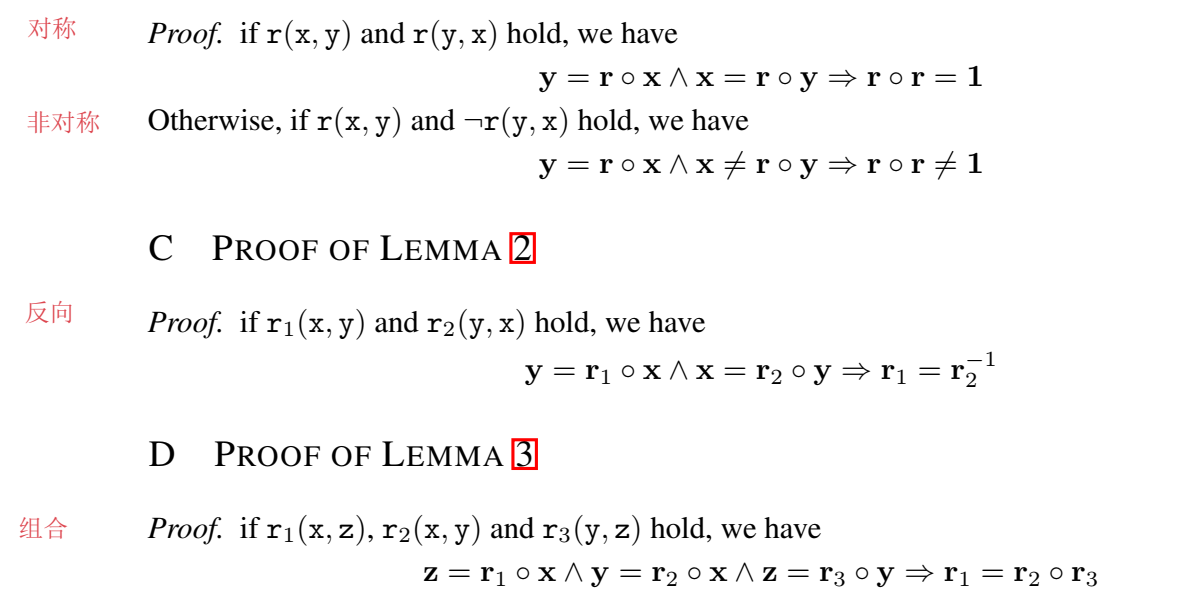
文章还提出了一种 self-adversarial 的负采样方法,为负样本赋权重。
最终 loss 为:
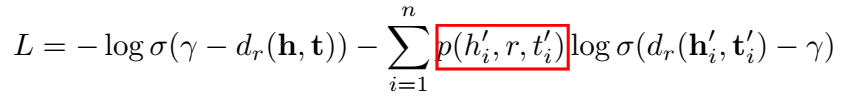
实验

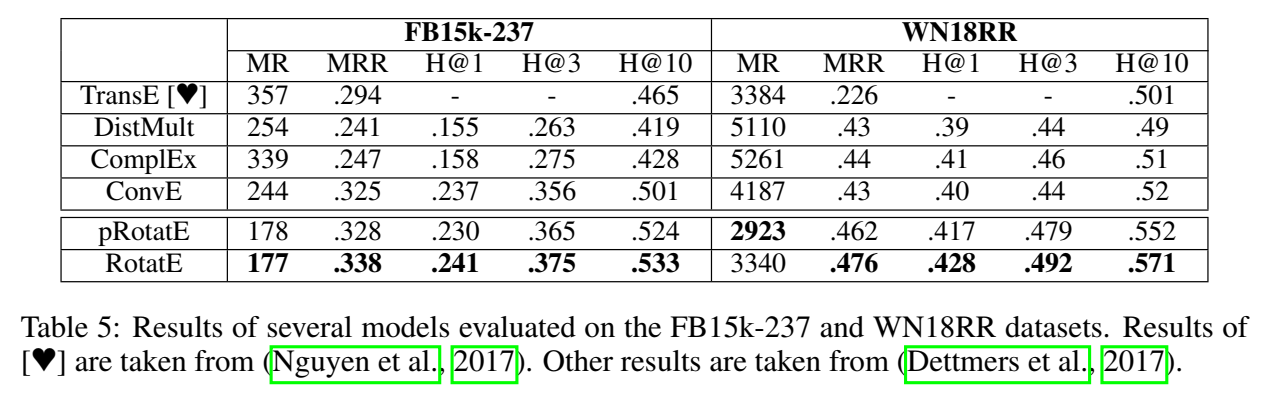
pRotatE 是 RotatE 没有模长(modulus)信息,只有相位(phase)信息的版本。
【code】 https://github.com/DeepGraphLearning/KnowledgeGraphEmbedding
TuckER
【paper】 TuckER: Tensor Factorization for Knowledge Graph Completion
【简介】 这篇文章是英国爱丁堡大学的研究者发表于 ICML 2019 上的文章,提出了 TuckER,是一个线性的张量分解模型,对表示三元组事实的二值张量做 Tucker 分解。
背景知识
本模型基于 1966 年 Tucker 提出的 Tucker decomposition,它将一个张量分解为一个 core tensor 和一组矩阵相乘的形式,可以被视为一种高阶 SVD 的形式,在矩阵是正交的和 core tensor 是“all-orthogonal(全正交)”的 special case 下。
文章声称 TuckER 是 fully expressive 的,这个词也在很多文章中见过,这里解释了它的含义:
对于给定的 golden triplet,一定有 embedding 各维度值的分配方法,使其与负样本分开。
TuckER 可以视为各种 bilinear model (RESCAL、DistMult、ComplEx、SimplE)的通用情况。
Related Work 中介绍了几大 bilinear 模型的方法和打分函数。
Tucker 分解:
一篇博客里介绍得很清楚,贴在这里好了:https://blog.csdn.net/qq_42397330/article/details/116290128

模型
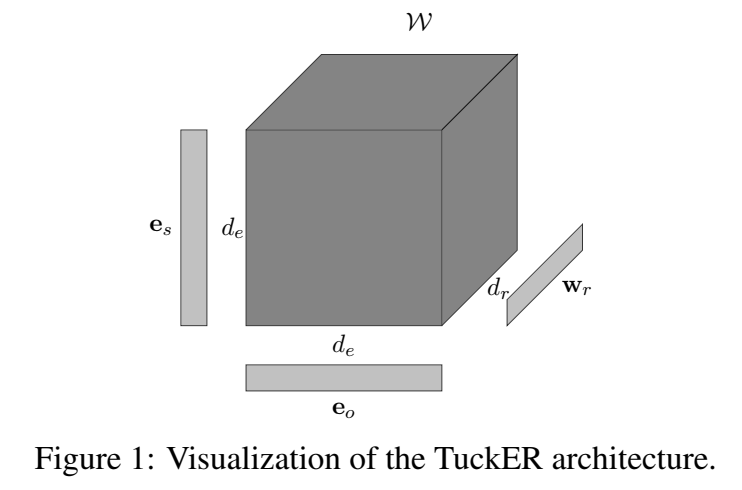
TuckER 对三元组的打分函数:
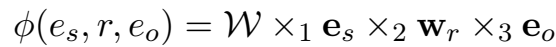
文章说,TuckER 的优势在于没有将所有的知识编码到 embedding 中,一些被储存在 core tensor 中,通过 multi-task learning 在实体和关系中共享。(不太理解。。。)
将上式计算出的三元组得分输入到 sigmoid 函数中,得到一个概率值,然后计算 loss(伯努利负 log-likelihood loss):
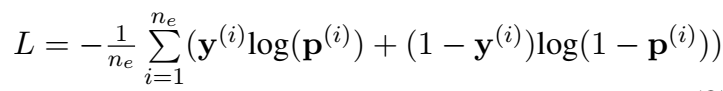
上面博客中的博主研读了代码:
在看代码之前,我认为这个评分函数是对整个三元组的评分,实际上代码中并不是这个意思。前向传播计算输出的是,一个矩阵,大小为(batch,len(entity)),输入的是一个batch的头实体和关系,相当于是在预测尾实体出现在每个位置的概率值。然后将这个概率值同目标位置组成的矩阵(正确位置为1)计算loss(可以理解为二分类问题)
理论分析
和 Rescal 的关系
Rescal 的打分函数是这样的:
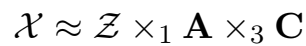
少了一个矩阵 B,关系矩阵就是 core tensor \(\mathcal{Z}\) 的 slice。
表示非对称关系

对称关系训练出的矩阵是对称的,非对称关系的矩阵是非对称的。
实验
在四个数据集(FB15k、FB15k-237、WN18、WN18RR)上进行了实验。
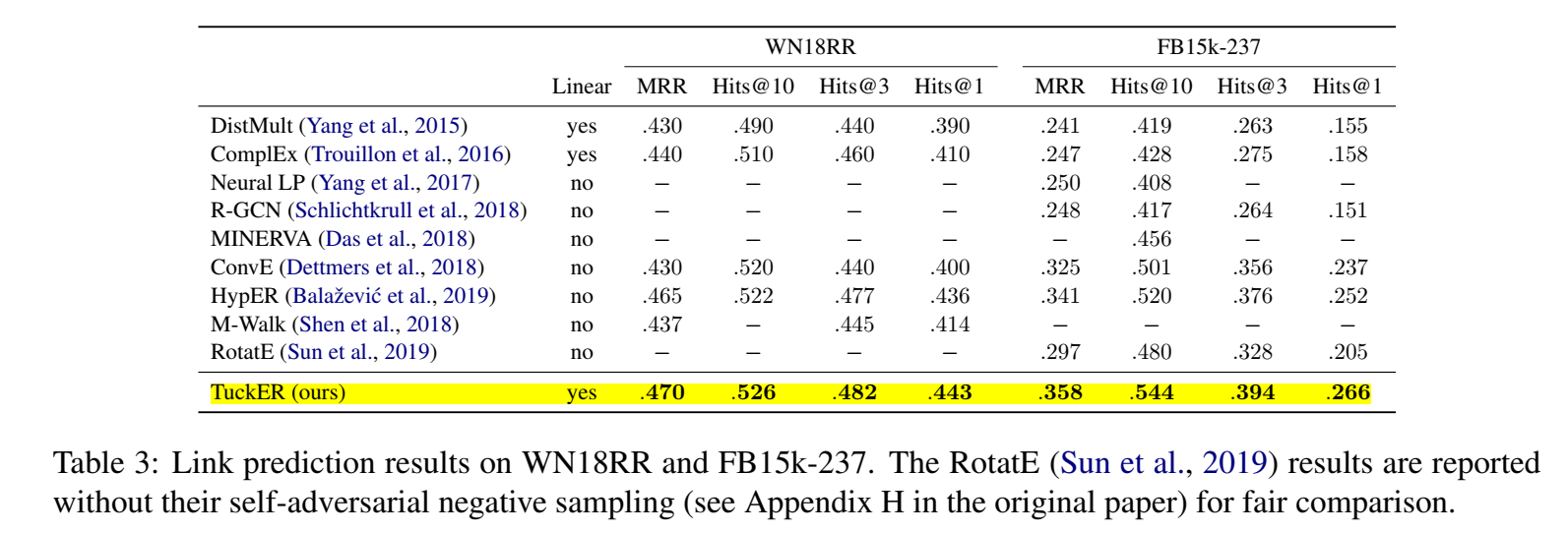
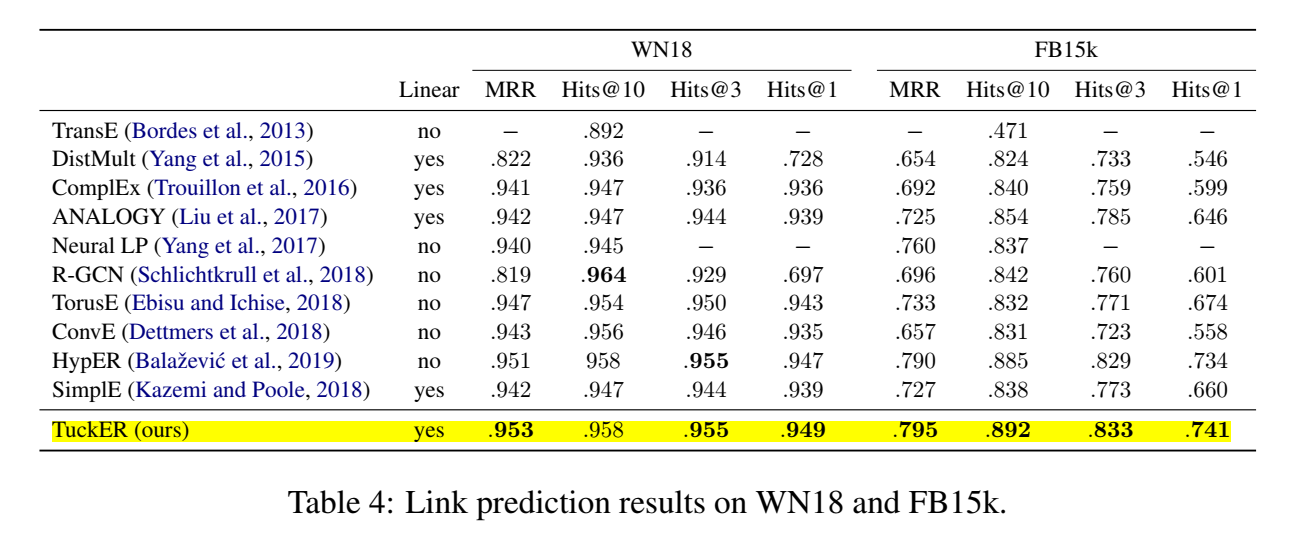
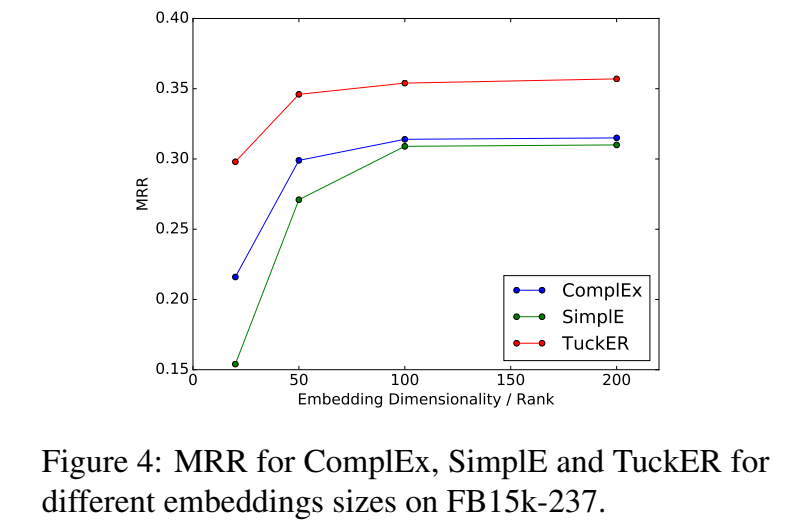
【code】 https://github.com/ibalazevic/TuckER
这个代码是用 PyTorch 实现的,看起来很简洁的样子,有时间的话真想好好学习一下,试着跑一下,but我没有。。。
【总结】 双线性模型终于tmd看完了!
